
记一次 Kubernetes 机器内核问题排查
原文链接:https://corvo.myseu.cn/2021/03/21/
此次排查发生在 2020-11 月份, 一直没时间写博客描述事情经过, 本次正好一起写了吧.
具体现象
在线上环境中的某个应用出现了接口缓慢的问题!!
就凭这个现象, 能列出来的原因数不胜数. 本篇博客主要叙述一下几次排查以及最后如何确定原因的过程, 可能不一定适用于其他集群, 就当是提供一个参考吧. 排查过程比较冗长, 过去太久了, 我也不太可能回忆出所有细节, 希望大家见谅.
网络拓扑结构
网络请求流入集群时, 对于我们集群的结构:
用户请求=>Nginx=>Ingress =>uwsgi
不要问为什么有了 Ingress 还有 Nginx. 这是历史原因, 有些工作暂时需要由 Nginx 承担.
初次定位
请求变慢一般马上就会考虑, 程序是不是变慢了, 所以在发现问题后, 首先在 uwsgi 中增加 简单的小接口, 这个接口是处理快并且马上返回数据, 然后定时请求该接口. 在运行几天之后, 确认到该接口的访问速度也很慢, 排除程序中的问题, 准备在链路中查找原因.
再次定位 – 简单的全链路数据统计
由于我们的 Nginx 有 2 层, 需要针对它们分别确认, 看看究竟是哪一层慢了. 请求量是比较大的, 如果针对每个请求去查看, 效率不高, 而且有可能掩盖真正原因, 所以这个过程采用统计的方式. 统计的方式是分别查看两层 Nginx 的日志情况. 由于我们已经在 elk 上接入了日志. elk 中筛选数据的脚本简单如下:
{
"bool": {
"must": [
{
"match_all": {}
},
{
"match_phrase": {
"app_name": {
"query": "xxxx"
}
}
},
{
"match_phrase": {
"path": {
"query": "/app/v1/user/ping"
}
}
},
{
"range": {
"request_time": {
"gte": 1,
"lt": 10
}
}
},
{
"range": {
"@timestamp": {
"gt": "2020-11-09 00:00:00",
"lte": "2020-11-12 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss",
"time_zone": "+08:00"
}
}
}
]
}
}
数据处理方案
根据 trace_id 可以获取到 Nignx 日志以及 Ingress 日志, 通过 elk 的 api 获得.
# 这个数据结构用来记录统计结果,
# [[0, 0.1], 3]表示 落在 0~0.1区间的有3条记录
# 因为小数的比较和区间比较麻烦, 所以采用整数, 这里的0~35其实是0~3.5s区间
# ingress_cal_map = [
# [[0, 0.1], 0],
# [[0.1, 0.2], 0],
# [[0.2, 0.3], 0],
# [[0.3, 0.4], 0],
# [[0.4, 0.5], 0],
# [[0.5, 1], 0],
# ]
ingress_cal_map = []
for x in range(0, 35, 1):
ingress_cal_map.append(
[[x, (x+1)], 0]
)
nginx_cal_map = copy.deepcopy(ingress_cal_map)
nginx_ingress_gap = copy.deepcopy(ingress_cal_map)
ingress_upstream_gap = copy.deepcopy(ingress_cal_map)
def trace_statisics():
trace_ids = []
# 这里的trace_id是提前查找过, 那些响应时间比较久的请求所对应的trace_id
with open(trace_id_file) as f:
data = f.readlines()
for d in data:
trace_ids.append(d.strip())
cnt = 0
for trace_id in trace_ids:
try:
access_data, ingress_data = get_igor_trace(trace_id)
except TypeError as e:
# 继续尝试一次
try:
access_data, ingress_data = get_igor_trace.force_refresh(trace_id)
except TypeError as e:
print("Can't process trace {}: {}".format(trace_id, e))
continue
if access_data['path'] != "/app/v1/user/ping": # 过滤脏数据
continue
if 'request_time' not in ingress_data:
continue
def get_int_num(data): # 数据统一做*10处理
return int(float(data) * 10)
# 针对每个区间段进行数据统计, 可能有点罗嗦和重复, 我当时做统计够用了
ingress_req_time = get_int_num(ingress_data['request_time'])
ingress_upstream_time = get_int_num(ingress_data['upstream_response_time'])
for cal in ingress_cal_map:
if ingress_req_time >= cal[0][0] and ingress_req_time < cal[0][1]:
cal[1] += 1
break
nginx_req_time = get_int_num(access_data['request_time'])
for cal in nginx_cal_map:
if nginx_req_time >= cal[0][0] and nginx_req_time < cal[0][1]:
cal[1] += 1
break
gap = nginx_req_time - ingress_req_time
for cal in nginx_ingress_gap:
if gap >= cal[0][0] and gap <= cal[0][1]:
cal[1] += 1
break
gap = ingress_req_time - ingress_upstream_time
for cal in ingress_upstream_gap:
if gap >= cal[0][0] and gap <= cal[0][1]:
cal[1] += 1
break
我分别针对request_time(nginx), request_time(ingress), 以及requet_time(nginx) - request_time(ingress),做了统计.
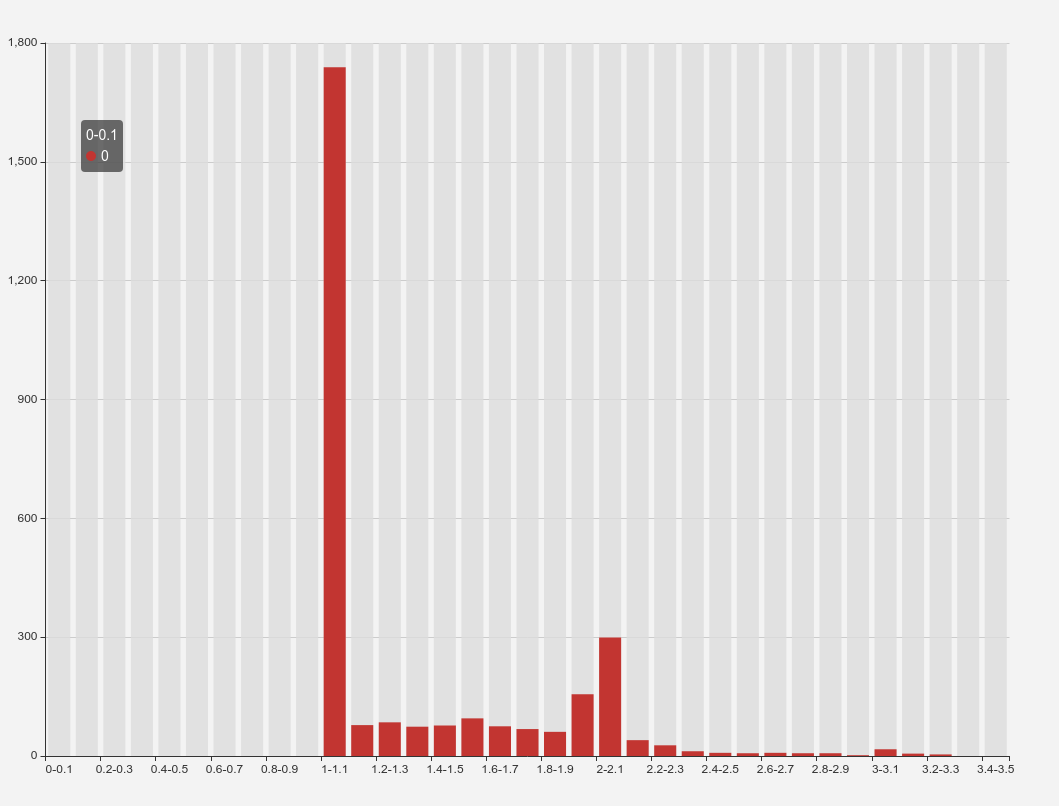
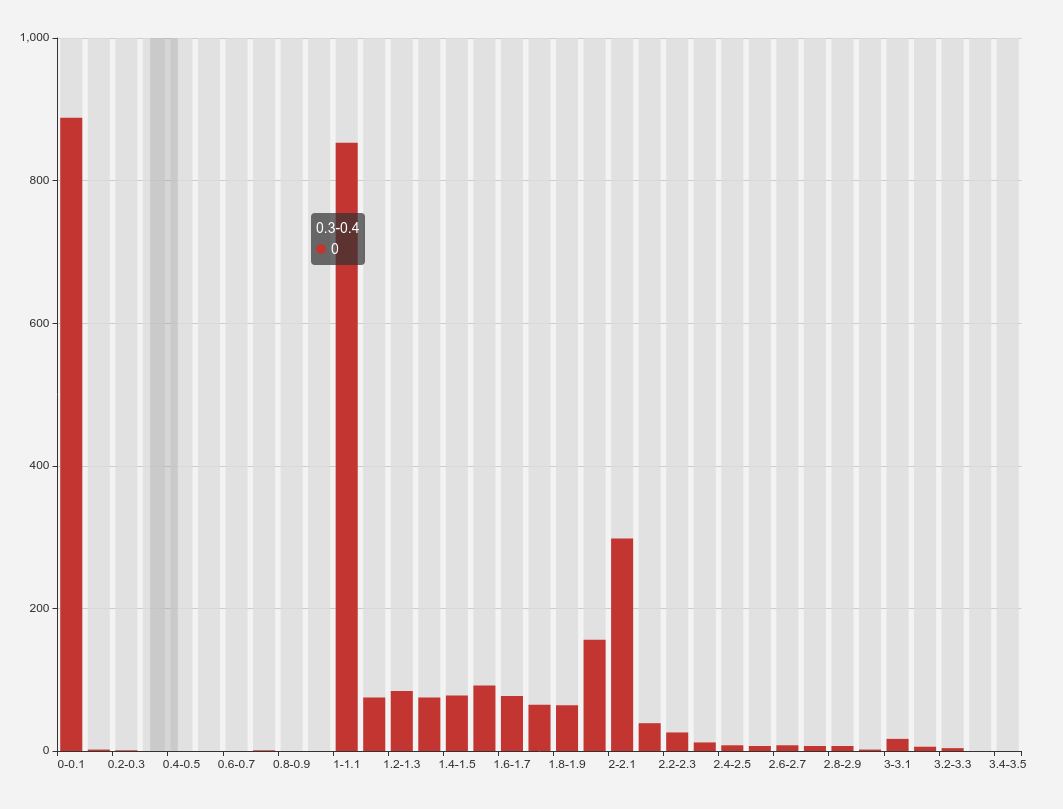
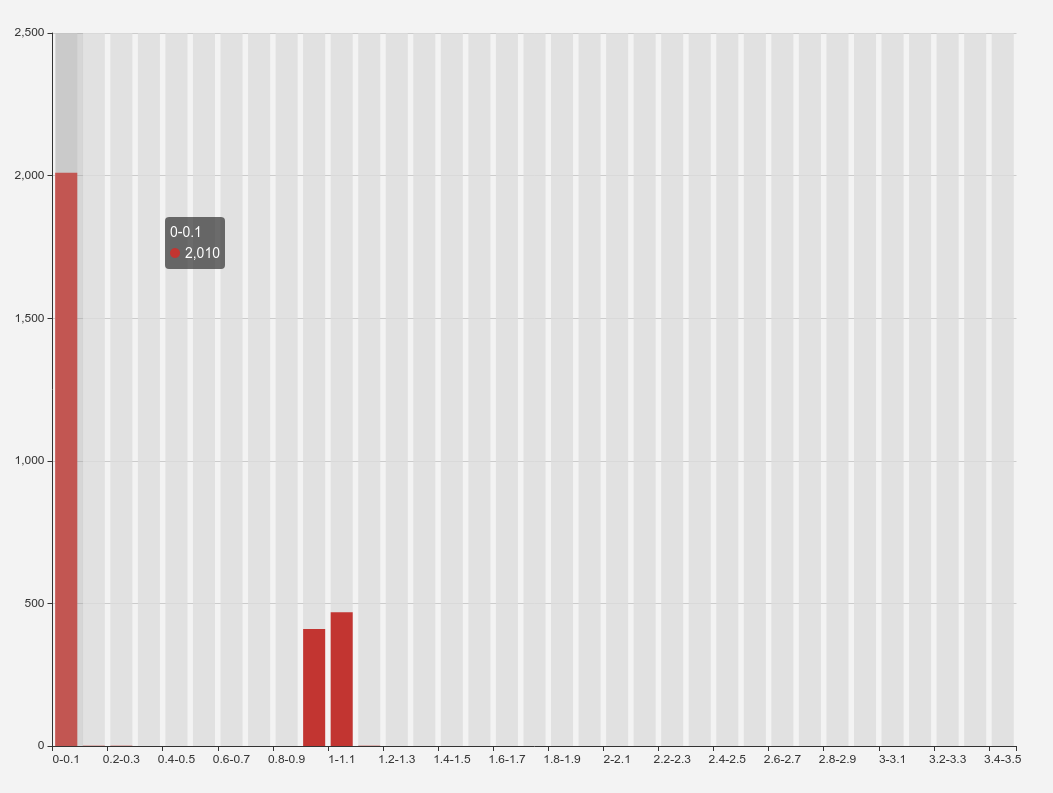
最后的统计结果大概如下:
结果分析
我们总共有约 3000 条数据!
图一: 超过半数的请求落在 11.1s 区间, 1s2s 的请求比较均匀, 之后越来越少了.
图二: 大约 1/4 的请求其实已经在 0.1s 内返回了, 但是 1~1.1s 也有 1/4 的请求落上去了, 随后的结果与图一类似.
从图 1 图 2 结合来看, 部分请求在 Ingress 侧处理的时间其实比较短的,
图三: 比较明显了, 2/3 的请求在响应时间方面能够保持一致, 1/3 的请求会有 1s 左右的延迟.
总结
从统计结果来看, Nginx => Ingress 以及 Ingress => upstream, 都存在不同程度的延迟, 超过 1s 的应用, 大约有 2/3 的延迟来自 Ingress=>upstream, 1/3 的延迟来自 Nginx=>Ingress.
再深入调查 - 抓包处理
抓包调查主要针对Ingress=>uwsgi, 由于数据包延迟的情况只是偶发性现象, 所以需要抓取所有的数据包再进行过滤… 这是一条请求时间较长的数据, 本身这个接口返回应该很快.
{
"_source": {
"INDEX": "51",
"path": "/app/v1/media/",
"referer": "",
"user_agent": "okhttp/4.8.1",
"upstream_connect_time": "1.288",
"upstream_response_time": "1.400",
"TIMESTAMP": "1605776490465",
"request": "POST /app/v1/media/ HTTP/1.0",
"status": "200",
"proxy_upstream_name": "default-prod-XXX-80",
"response_size": "68",
"client_ip": "XXXXX",
"upstream_addr": "172.32.18.194:6000",
"request_size": "1661",
"@source": "XXXX",
"domain": "XXX",
"upstream_status": "200",
"@version": "1",
"request_time": "1.403",
"protocol": "HTTP/1.0",
"tags": ["_dateparsefailure"],
"@timestamp": "2020-11-19T09:01:29.000Z",
"request_method": "POST",
"trace_id": "87bad3cf9d184df0:87bad3cf9d184df0:0:1"
}
}
Ingress 侧数据包
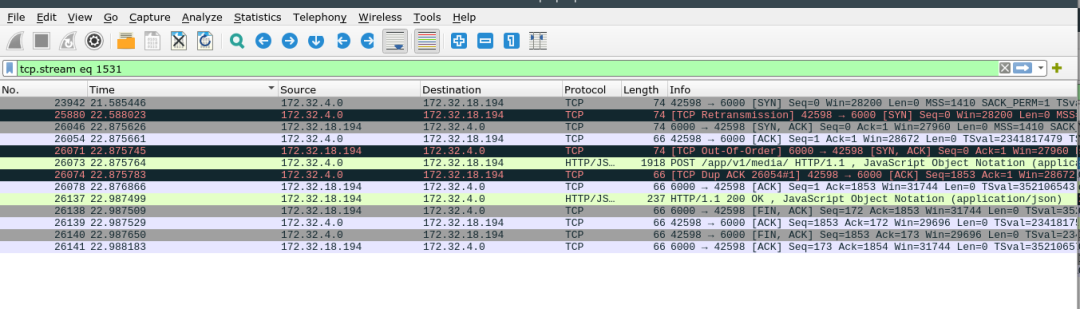
uwsgi 侧数据包
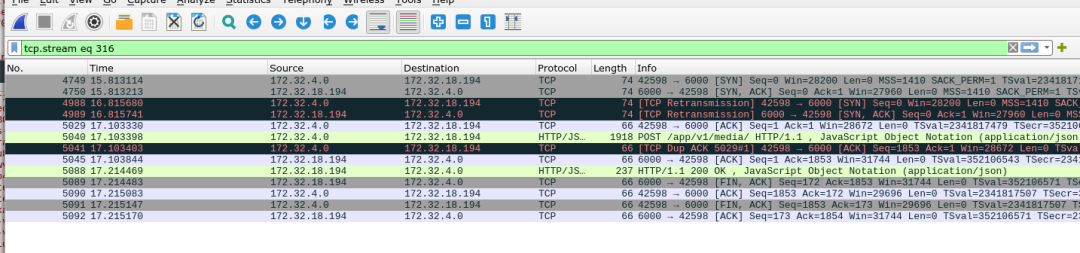
数据包流转情况
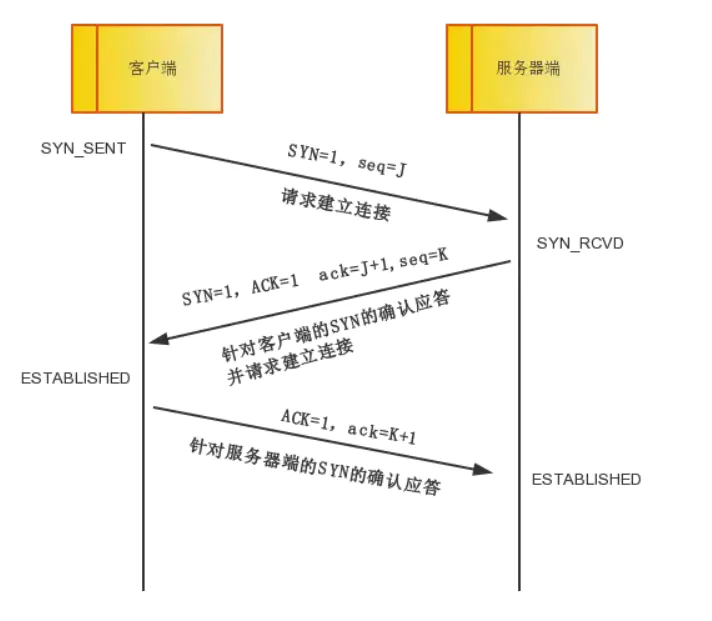
回顾一下 TCP 三次握手:
首先从 Ingress 侧查看, 连接在21.585446开始, 22.588023时, 进行了数据包重新发送的操作.
从 Node 侧查看, node 在 ingress 数据包发出后不久马上就收到了 syn, 也立刻进行了 syn 的返回, 但是不知为何 1s 后才出现在 ingress 处.
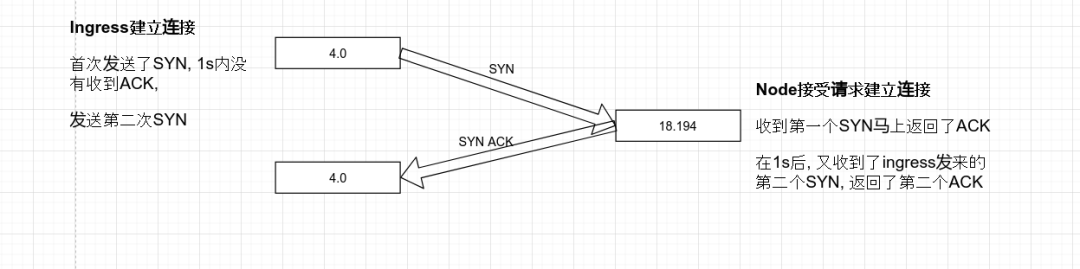
有一点比较令人在意, 即便是数据包发生了重传, 但是也没有出现丢包的问题, 从两台机器数据包的流转来看, 此次请求中, 大部分的时间是因为数据包的延迟到达造成的, 重传只是表面现象, 真正的问题是发生了数据包的延迟.
不止是 ack 数据包发生了延迟
从随机抓包的情况来看, 不止是SYN ACK发生了重传:

有些FIN ACK也会, 数据包的延迟是有概率的行为!!!
总结
单单看这个抓包可能只能确认是发生了丢包, 但是如果结合 Ingress 与 Nginx 的日志请求来看, 如果丢包发生在 tcp 连接阶段, 那么在 Ingress 中, 我们就可以查看upstream_connect_time 这个值来大致估计下超时情况. 当时是这么整理的记录:
我初步猜测这部分时间主要消耗在了 TCP 连接建立时, 因为建立连接的操作在两次 Nginx 转发时都存在, 而我们的链路全部使用了短连接, 下一步我准备增加
$upstream_connect_time变量, 记录建立连接花费的时间. http://nginx.org/en/docs/http/ngx_http_upstream_module.html
后续工作
既然可以了解到 tcp 连接的建立时间比较久, 我们可以用它来作为一个衡量指标, 我把 wrk 也修改了下, 增加了对于连接时间的测量, 具体的 PR 见这里(https://github.com/wg/wrk/pull/447), 我们可以利用这一项指标衡量后端的服务情况.
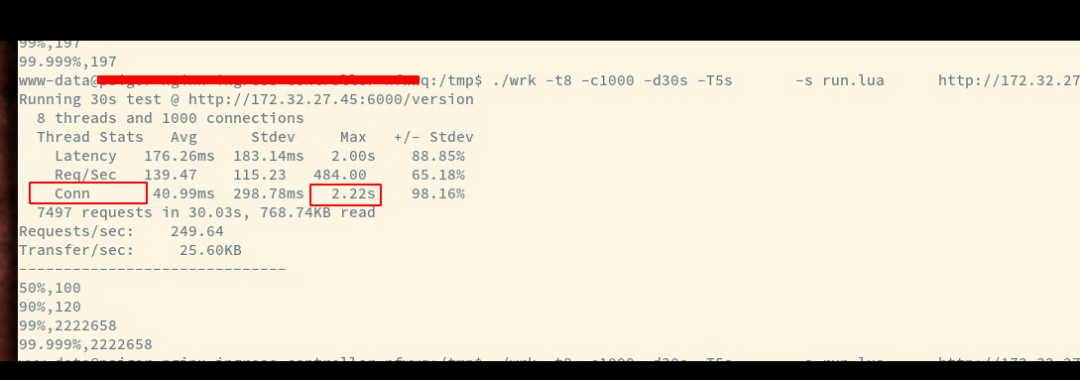
寻找大佬, 看看是否遇到类似问题
上面的工作前前后后我进行了几次, 也没有什么头绪, 遂找到公司的其他 K8S 大佬咨询问题, 大佬提供了一个思路:
宿主机延迟也高的话,那就暂时排除宿主机到容器这条路径。我们这边此前排查过一个延迟问题, 是由于 k8s 的监控工具定期 cat proc 系统下的 cgroup 统计信息, 但由于 docker 频繁销毁重建以及内核 cache 机制,使得每次 cat 时间很长占用内核导致网络延迟, 可否排查一下你们的宿主机是否有类似情形?不一定是 cgroup,其他需要频繁陷入到内核的操作都可能导致延迟很高
这个跟我们排查的 cgroup 太像了,宿主机上有一些周期性任务,随着执行次数增多,占用的内核资源越来越多,达到一定程度就影响了网络延迟
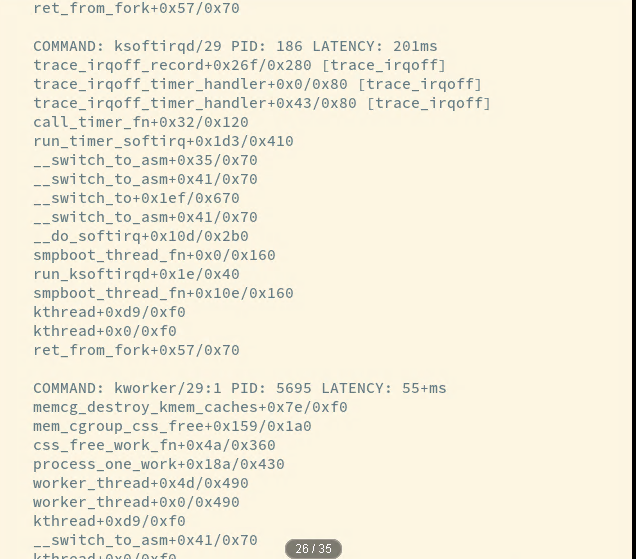
大佬们也提供了一个内核检查工具(可以追踪和定位中断或者软中断关闭的时间):
https://github.com/bytedance/trace-irqoff
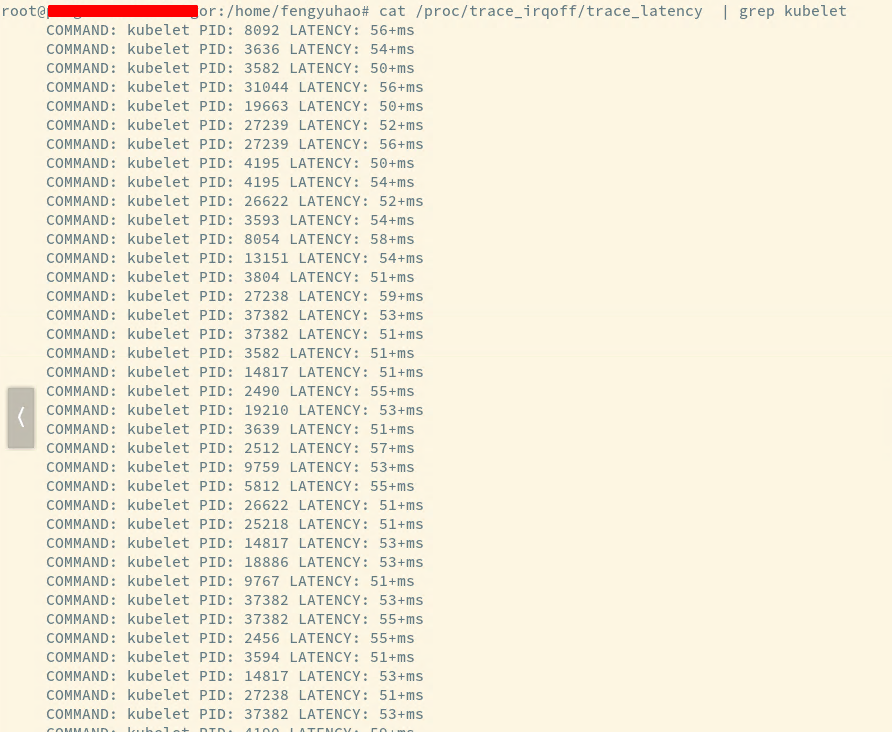
有问题的 ingress 机器 的 latency 特别多,好多都是这样的报错, 其他机器没有这个日志:
而后, 我针对机器中的 kubelet 进行了一次追踪, 从火焰图中可以确认, 大量的时间耗费在了读取内核信息中.
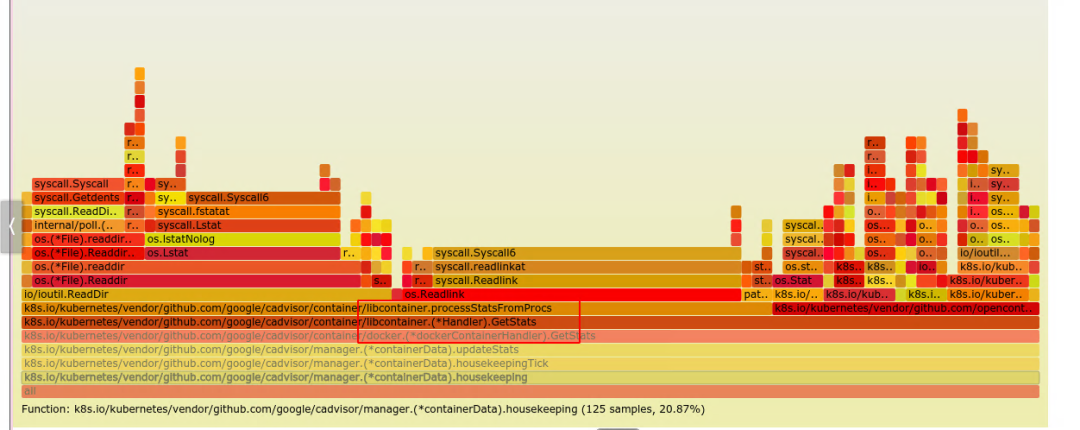
其中具体的代码如下:
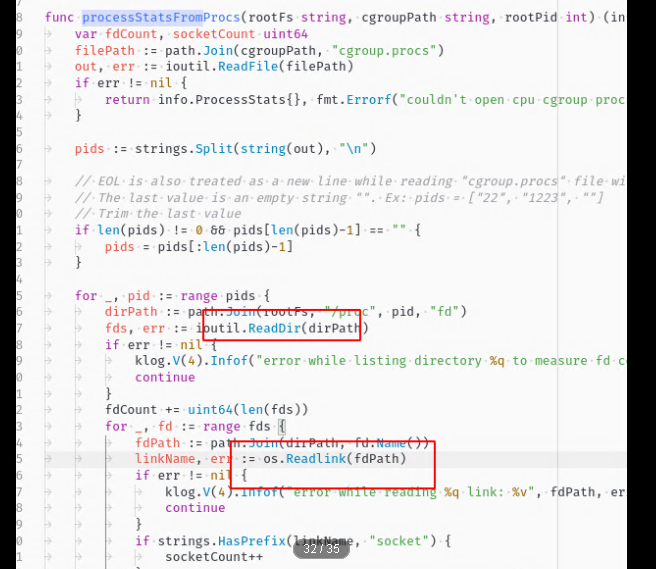
总结
根据大佬所给的方向, 基本能够确定问题发生的真正原因: 机器上定时任务的执行过多, 内核缓存一直增加, 导致内核速度变慢了. 它一变慢, 引发了 tcp 握手时间变长, 最后造成用户体验下降. 既然发现了问题, 解决方案也比较容易搜索到了, 增加任务, 检查内核是否变慢, 慢了的话就清理一次:
$ sync && echo 3 > /proc/sys/vm/drop_caches
总结
这次的排查过程是由于应用层出现了影响用户体验的问题后, 进一步延伸到了网络层, 其中经历了漫长的抓包过程, 也增加了自己的脚本用于指标衡量, 随后又通过内核工具定位到了具体应用, 最后再根据应用的pprof工具制作出的火焰图定位到了更加精确的异常位置, 期间自己一个人没法处理问题, 遂请其他大佬来帮忙, 大佬们见多识广, 可以给出一些可能性的猜想, 还是很有帮助的.
当你发现某台机器无论做什么都慢, 而 cpu 和内核却不是瓶颈的时候, 那有可能是内核慢了.
希望本文能对大家未来排查集群问题时有所帮助.
- END -
公众号后台回复「加群」加入一线高级工程师技术交流群,一起交流进步。
推荐阅读 Kubernetes 运维架构师实战集训营 31天拿下K8s含金量最高的CKA证书! Shell 脚本进阶,经典用法及其案例 Kubernetes 集群网络从懵圈到熟悉 一个完整的、全面 k8s 化的集群稳定架构 JAVA应用运维,线上故障排查全套路 K8s常见问题:Service 不能访问排查流程 记一次 Linux服务器被入侵后的排查思路
点亮,服务器三年不宕机

