
用Keras实现使用自归一化神经网络来解决梯度消失的问题
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者:Jonathan Quijas
编译:ronghuaiyang
通过非常简单的模型配置,提升深度神经网络的收敛速度和性能。

问题描述
训练深度神经网络是一项具有挑战性的任务,特别是对于深度很深的模型。这些困难的一个主要部分是由于通过backpropagation来计算的梯度的不稳定性造成的。在这篇文章中,我们将学习如何使用Keras创建一个自归一化的深度前馈神经网络。这将解决梯度不稳定的问题,加速训练收敛,提高模型性能。
背景
在他们的2010年里程碑论文中,Xavier gloriot和Yoshua Bengio提供了关于训练深度神经网络困难的宝贵见解。事实证明,当时流行的激活函数和权值初始化技术直接促成了所谓的梯度消失/爆炸问题。
简而言之,这是当梯度开始减少或增加太多时,就无法进行训练了。
饱和的激活函数
在广泛采用现在无处不在的ReLU函数及其变体之前,sigmoid函数(s形)是激活函数最受欢迎的选择。sigmoid激活函数的例子是logistic函数:
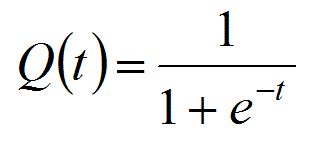
sigmoid函数的一个主要缺点是容易饱和,在logistic函数的情况下,输出容易饱和成0或1。这将导致随着输入的变大,梯度越来越小(非常接近0)。
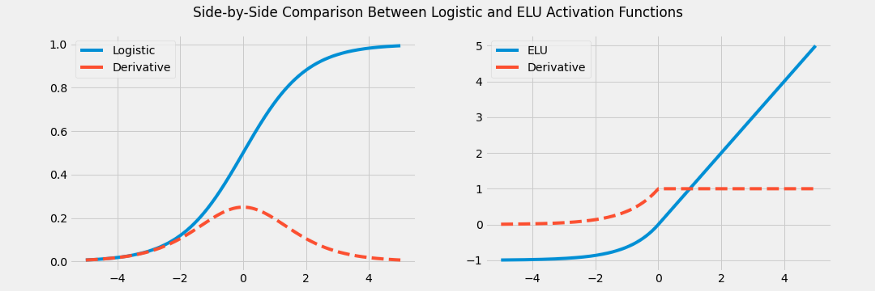
由于ReLU及其变体没有饱和,它们缓解了这种梯度消失的现象。ReLU的改进变种,如ELU函数(如上所示),在所有地方都具有平滑的导数:
对于任何正输入,其导数总是1 对于较小的负数,导数不会接近于零 所有地方都是光滑可导的
注意:因此,输入的期望值为0,且方差较小是有益的。这将有助于在网络中保持较大的梯度。
权值初始化的糟糕的选择
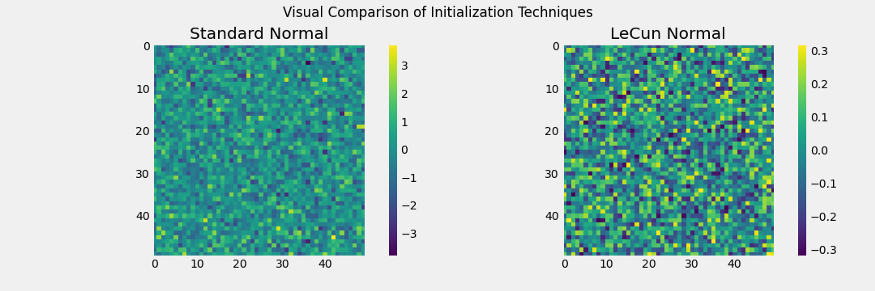
论文中发现的另一个重要观点是使用均值为0,标准偏差为1的正态分布的权值初始化的影响,在作者发现之前,这是一个广泛流行的选择。
作者表明,sigmoid激活和权值初始化(均值为0,标准差为1的正态分布)的特定组合使输出具有比输入更大的方差。这种效应在整个网络中复合,使得更深层次的输入相对于更浅(更早)层次的输入具有更大的量级。这一现象后来被Sergey Ioffe和Christian Szegedy在2015年的一篇里程碑式的论文中命名为内部协变量移位。
正如我们上面看到的,当使用sigmoid激活时,会出现越来越小的梯度。
这个问题在logistic函数中更加突出,因为它的期望值是0.5,而不是0。双曲正切sigmoid函数的期望值为0,因此在实践中表现得更好(但也趋于饱和)。
作者认为,为了使梯度在训练过程中保持稳定,所有层的输入和输出必须在整个网络中保持或多或少相同的方差。这将防止信号在向前传播时死亡或爆炸,以及在反向传播时梯度消失或爆炸。
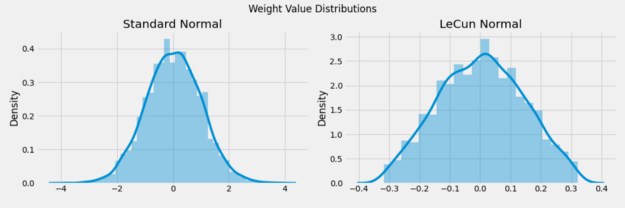
为了实现这一点,他们提出了一种权值初始化技术,以论文的第一作者命名为Glorot(或Xavier)初始化。结果是,通过对Glorot技术做一点修改,我们得到了LeCun初始化,以Yann LeCun命名。
自归一化神经网络(SNNs)
2017年,Günter Klambauer等人介绍了自归一化神经网络 (SNNs)。通过确保满足某些条件,这些网络能够在所有层保持输出接近0的均值和1的标准偏差。这意味着SNN不会受到梯度消失/爆炸问题的困扰,因此比没有这种自归一化特性的网络收敛得更快。根据作者的说法,SNN在论文中报告的所有学习任务中都显著优于其他变体(没有自归一化)。下面是创建SNN所需条件的更详细描述。
结构和层
SNN必须是一个由全连接的层组成的顺序模型。
注意:根据任务的不同,某些类型的网络比其他类型的网络更适合。例如,卷积神经网络通常用于计算机视觉任务,主要是由于其参数效率。确保全连接的层适合你的任务如果是这种情况,那么考虑使用SNN。否则,Batch Normalization是进行归一化的好方法。
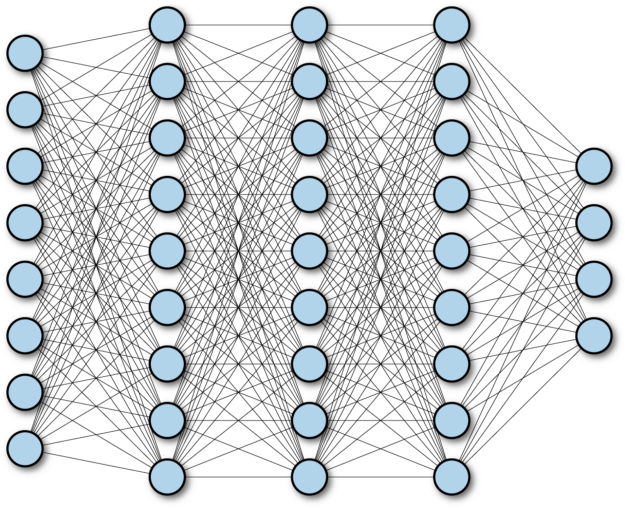
在这种情况下,顺序模型是指各层按照严格的顺序排列的模型。换句话说,对于每个隐藏层l, l接收的唯一输入是层l-1的输出。在Keras中,这种类型的模型实际上被称为顺序模型。
全连接层是指层中的每个单元都与每个输入有连接。在Keras中,这种类型的层称为Dense层。
输入归一化
输入必须归一化。这意味着训练数据的均值应为0,所有特征的标准差为1。
权值初始化
SNN中的所有层必须使用LeCun正则初始化来初始化。正如我们前面看到的,这将确保权重值的范围接近于0。
SELU激活函数
作者引入了Scaled ELU (SELU)函数作为snn的激活函数。只要满足上述条件,SELU就提供了自归一化的保证。
Keras实现
下面的示例展示了如何为10类分类任务定义SNN:
def get_snn(num_hidden_layers=20, input_shape=None, hidden_layer_size=100):
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=input_shape))
for layer in range(num_hidden_layers):
model.add(keras.layers.Dense(hidden_layer_size, activation='selu', kernel_initializer='lecun_normal'))
model.add(keras.layers.Dense(10, activation='softmax'))
return model
实验结果
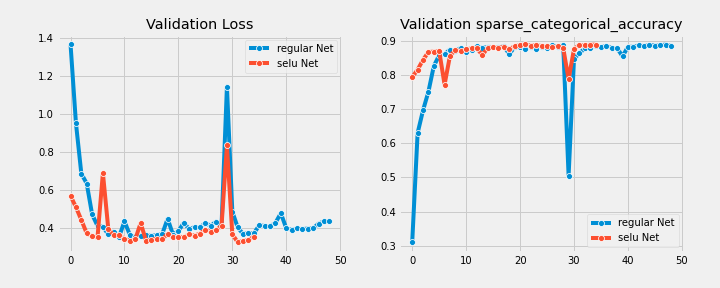
下面是常规前馈神经网络和SNN在三种不同任务上的比较:
图像分类(Fashion MNIST, CIFAR10) 回归(波士顿住房数据集)
两个网络共享以下配置:
20个隐藏层 每隐藏层100个单位 Nadam优化器 7e-4的学习率 50个epochs
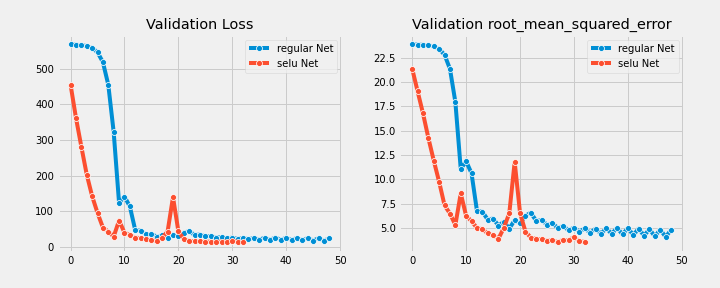
对于这两种模型,学习曲线都停留在获得最佳性能度量的epoch。
Fashion MNIST
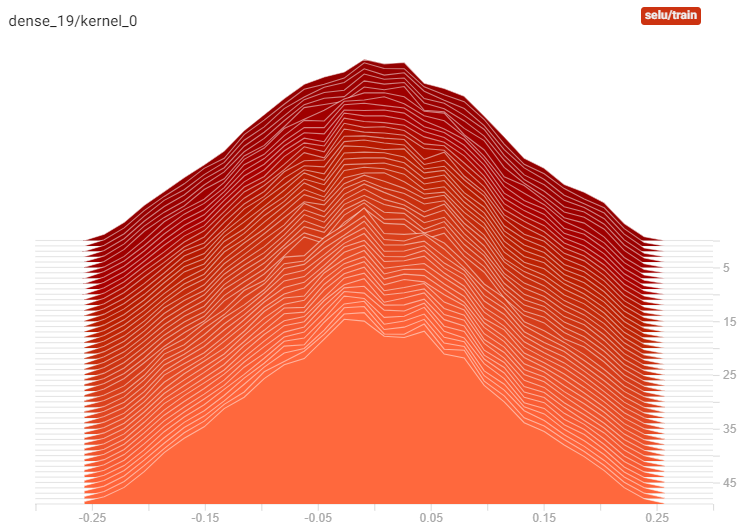
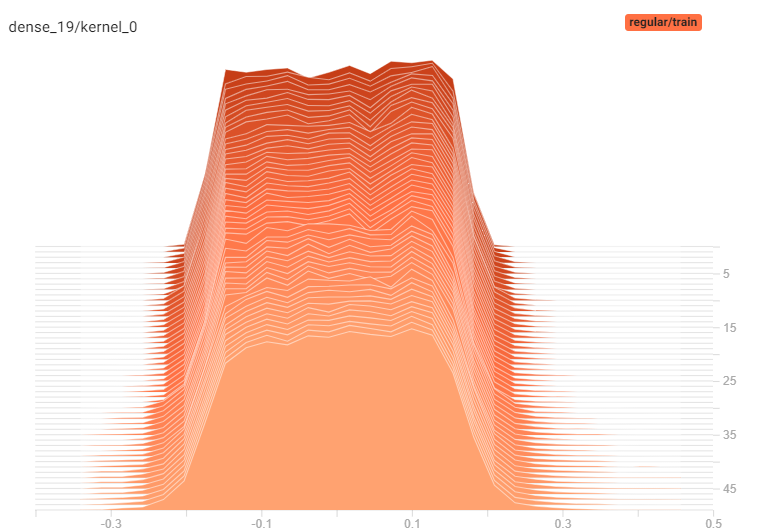
CIFAR10
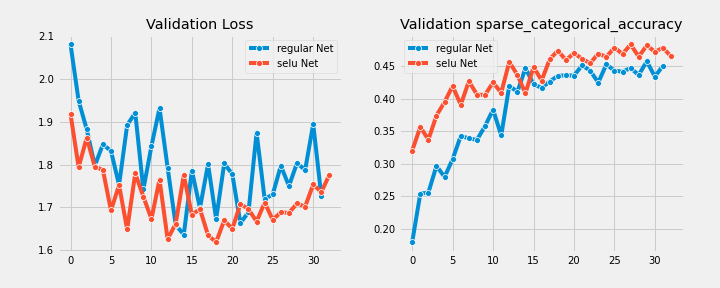
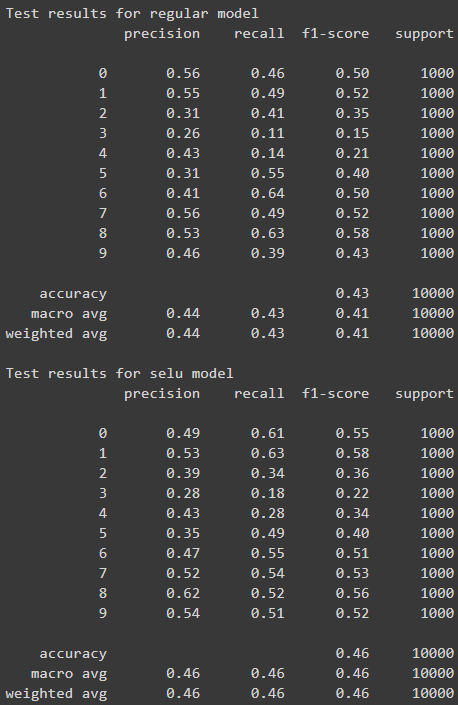
Boston Housing
总结
通过确保我们的前馈神经网络结构满足一组条件,我们可以使它自动规范化。所需条件如下:
模型必须是一个全连接的层序列 使用LeCun normal初始化技术初始化权值 使用SELU激活函数 输入归一化
与没有自归一的模型相比,这几乎总是会导致性能和收敛性的改进。如果你的任务需要一个常规的前馈神经网络,可以考虑使用SNN变体。否则,Batch Normalization是一种优秀的(但需要更多时间和计算成本)规范化策略。

英文原文:https://medium.com/towards-artificial-intelligence/solving-the-vanishing-gradient-problem-with-self-normalizing-neural-networks-using-keras-59a1398b779f
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!