
ViT:视觉Transformer backbone网络ViT论文与代码详解
机器学习实验室
共 9157字,需浏览 19分钟
·
2021-06-08 15:24
Visual Transformer
Author:louwill
Machine Learning Lab
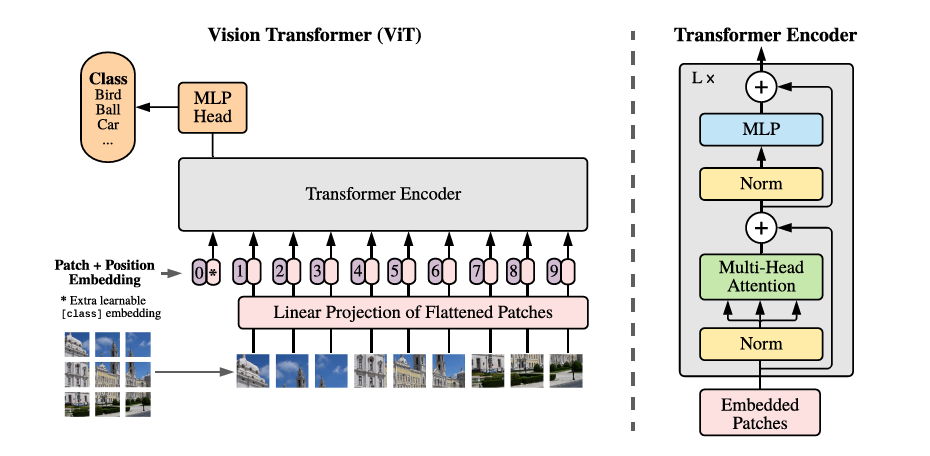
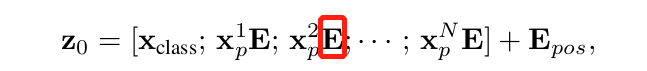
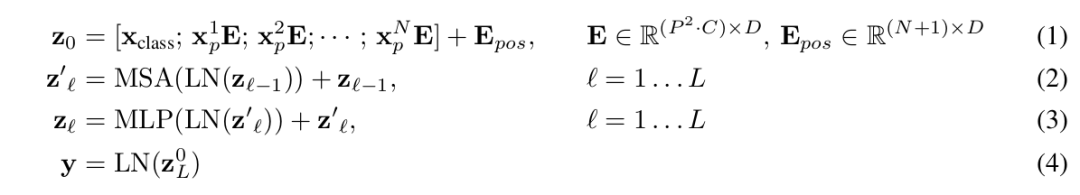
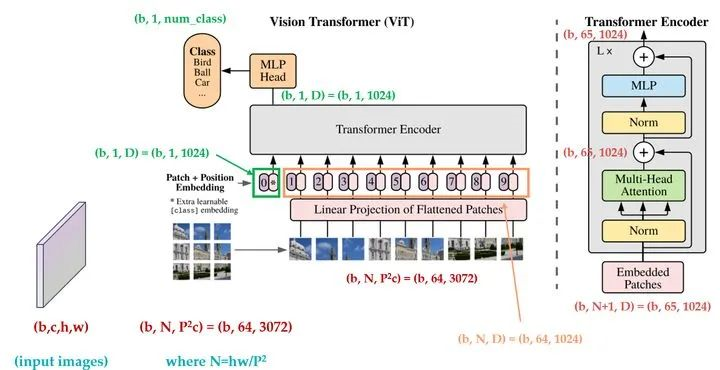
ILSVRC-2012 ImageNet dataset:1000 classes ImageNet-21k:21k classes JFT:18k High Resolution Images
CIFAR-10/100 Oxford-IIIT Pets Oxford Flowers-102 VTAB
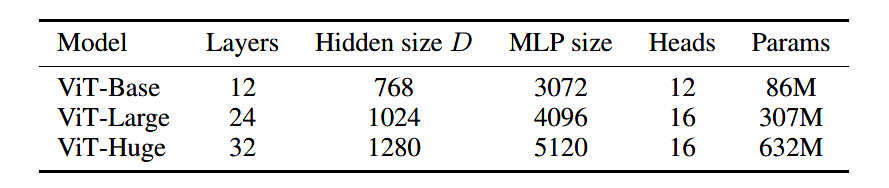
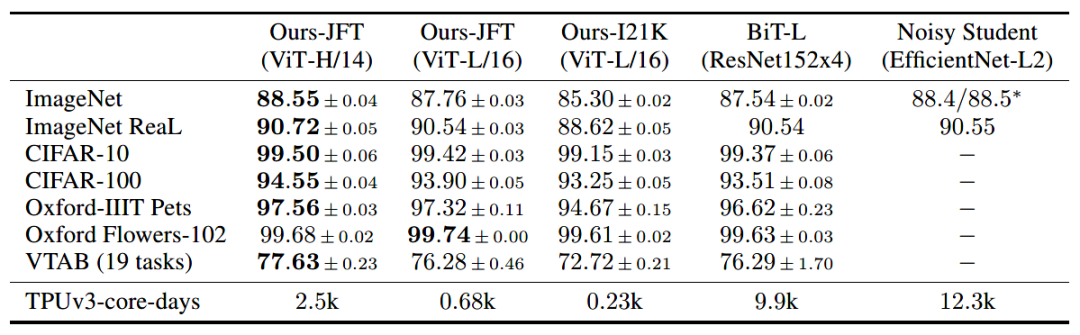
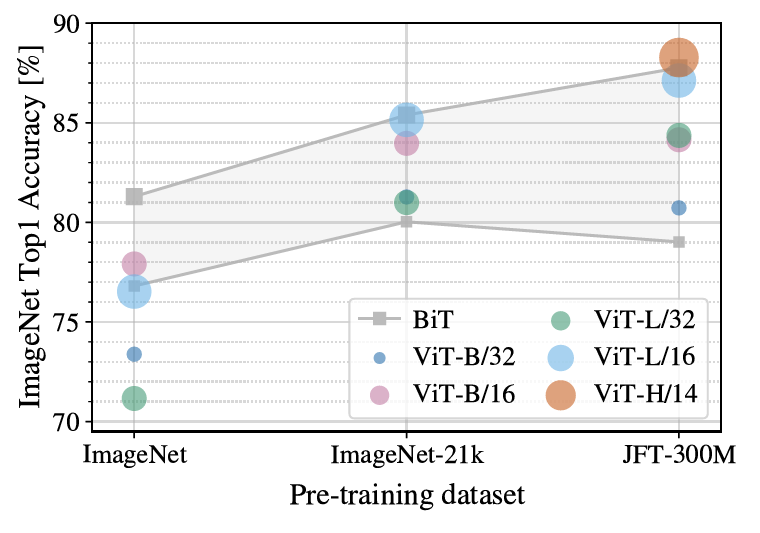
pip install vit-pytorchimport torchfrom vit_pytorch import ViT# 创建ViT模型实例v = ViT(image_size = 256,patch_size = 32,num_classes = 1000,dim = 1024,depth = 6,heads = 16,mlp_dim = 2048,dropout = 0.1,emb_dropout = 0.1)# 随机化一个图像输入img = torch.randn(1, 3, 256, 256)# 获取输出preds = v(img) # (1, 1000)
image_size:原始图像尺寸
patch_size:图像块的尺寸
num_classes:类别数量
dim:Transformer隐变量维度大小
depth:Transformer编码器层数
Heads:MSA中的head数
dropout:失活比例
emb_dropout:嵌入层失活比例
# 导入相关模块import torchfrom torch import nn, einsumimport torch.nn.functional as Ffrom einops import rearrange, repeatfrom einops.layers.torch import Rearrange# 辅助函数,生成元组def pair(t):return t if isinstance(t, tuple) else (t, t)# 规范化层的类封装class PreNorm(nn.Module):def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)# FFNclass FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout = 0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)# Attentionclass Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):b, n, _, h = *x.shape, self.headsqkv = self.to_qkv(x).chunk(3, dim = -1)q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scaleattn = self.attend(dots)out = einsum('b h i j, b h j d -> b h i d', attn, v)out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)
# 基于PreNorm、Attention和FFN搭建Transformerclass Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn x
(3) 搭建ViT
class ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):super().__init__()image_height, image_width = pair(image_size)patch_height, patch_width = pair(patch_size)assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'# patch数量num_patches = (image_height // patch_height) * (image_width // patch_width)# patch维度patch_dim = channels * patch_height * patch_widthassert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'# 定义块嵌入self.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),nn.Linear(patch_dim, dim),)# 定义位置编码self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))# 定义类别向量self.cls_token = nn.Parameter(torch.randn(1, 1, dim))self.dropout = nn.Dropout(emb_dropout)self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)self.pool = poolself.to_latent = nn.Identity()# 定义MLPself.mlp_head = nn.Sequential(nn.LayerNorm(dim),nn.Linear(dim, num_classes))# ViT前向流程def forward(self, img):# 块嵌入x = self.to_patch_embedding(img)b, n, _ = x.shape# 追加类别向量cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)x = torch.cat((cls_tokens, x), dim=1)# 追加位置编码x += self.pos_embedding[:, :(n + 1)]# dropoutx = self.dropout(x)# 输入到transformerx = self.transformer(x)x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]x = self.to_latent(x)# MLPreturn self.mlp_head(x)
小结
参考资料:
An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale
https://github.com/lucidrains/vit-pytorch
https://mp.weixin.qq.com/s/ozUHHGMqIC0-FRWoNGhVYQ
往期精彩:
求个在看
评论