
提高55%异地算力利用率,现已开源!响应‘东数西算’AI大基建
共 3139字,需浏览 7分钟
·
2022-03-05 11:16
在 AI 浪潮中,无论是企业还是国家,对算力的需求都日益高涨。近期启动的“东数西算”项目,更是从宏观层面大力打造 AI 基础设施。但位于不同地理位置的计算机之间通信延迟较高,如何统筹兼顾、高效利用不同地区的计算能力,是当下亟待解决的重大议题。
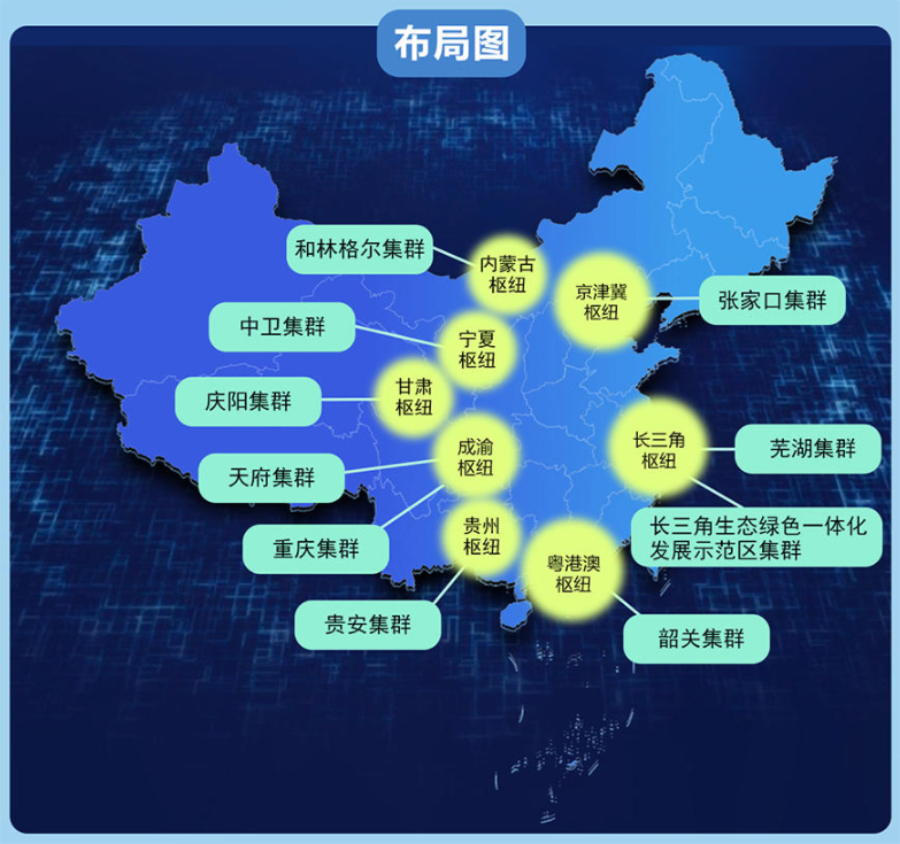
“东数西算”项目布局
与此同时,在大数据时代的背景下,如何保护隐私数据也成为社会热点,国家出台了数据安全、隐私保护的一系列法规。
针对以上难点,开源项目 Sky Computing 成功利用空间异构分布式计算特性,在保证用户数据隐私的前提下,可对联邦学习加速达 55%。
地址:https://github.com/hpcaitech/SkyComputing
空间异构分布式计算
随着深度学习的不断发展,模型的尺寸日益增长,目前的主流模型,例如 BERT 和 GPT-3 都有着数以亿计的参数。尽管这些模型在预测精度和性能提升方面有了长足的进步,但同样也给存储和运算等带来了极大的压力。为了加速AI模型训练的速度,分布式机器学习得以应运而生,它通常使用大量高速互联的同类型处理器,如超级计算机。

超级计算机
而空间异构分布式计算则进一步将拥有不同计算能力、通讯能力的计算资源组合在一起,作为一个大的集群完成大型计算任务。其中参与计算的硬件资源可以是大型专业计算服务器,也可以是小型的智能设备。目前,空间异构分布式计算作为一种新形式的异构计算,正在得到越来越多的关注。以我国为例,随着「东数西算」工作的推行,越来越多的计算资源将广泛地分布到西部各个地区,如何协调这类混合计算集群联合高效工作,也将成为高性能计算应用的研究热点。
近年来,云服务的规模、范围和对象都被不断扩展,越来越多的企业选择将自己的数据存储和数据计算相关业务部署在云端。然而,将所有服务依托于云端环境的缺点在于数据的迁移成本极高;同时,数据的隐私性和可靠性也难以保证;此外,分布在不同地区的云算力之间高昂的通信成本,也使得他们难以有效联合完成高算力任务。
云计算
联邦学习
为保护数据的隐私性,Google 于 2016 年提出联邦学习,这是一种加密的分布式机器学习技术。顾名思义,它通过搭建一个虚拟的「联邦」,将大大小小的数据孤岛联合到一起。每一个数据孤岛都像是这个「联邦」中的一个州,既保持一定的独立自主(比如商业机密,用户隐私),又能在数据不被对外共享的前提下共同建模,提升 AI 模型效果。目前,联邦学习广泛被运用在智能终端的模型训练中,如各个语音助手例如 Siri、Alex 等等。
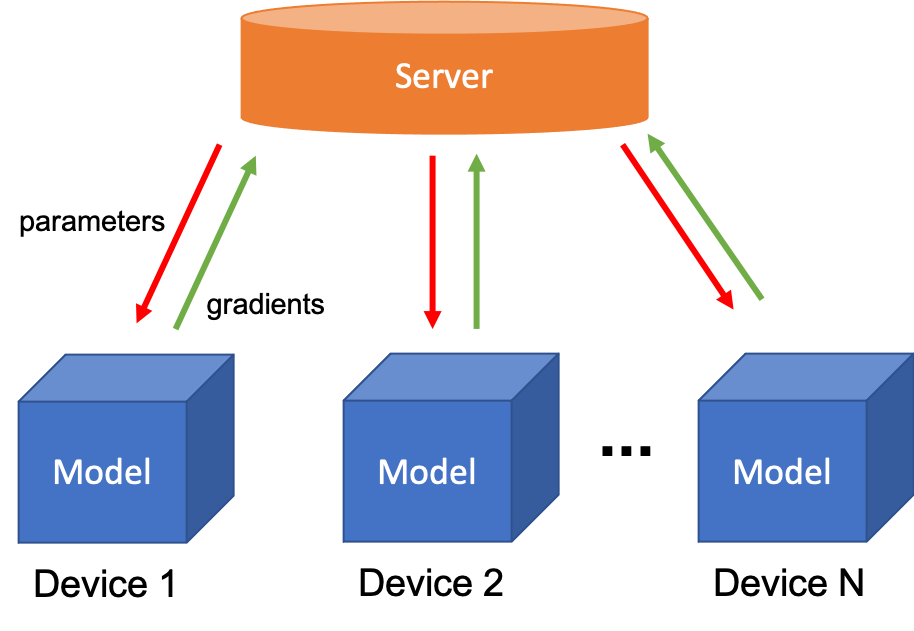
联邦学习
在现有的联邦学习模型并行中,模型被均匀分配给各个训练设备。然而,如前文所述,由于联邦学习的训练设备往往是用户的智能终端,性能差异较大,使用均匀分配,往往会造成通信时间瓶颈。
正如我们都知道木桶效应:木桶的盛水量由最短的那块木板决定。而在传统的联邦学习中,存在类似现象:训练速度由最慢的那个设备决定。
例如,对于处于使用模型并行的同一个联邦学习任务中的智能手机和树莓派,它们会被分配相同的任务量。但由于智能手机的运算能力远超树莓派,智能手机被迫闲置等待树莓派的任务完成。

木桶效应
Sky Computing
Sky Computing 针对以上痛点,通过负载均衡,将不同规模和能力的云服务器智能互联,达到大规模计算的算力需求,同时通过联邦学习的方式,仅在云服务器内部访问用户数据,避免数据迁移和隐私泄露。
负载均衡
要解决负载均衡的问题,首先要了解什么是「负载」。在计算机中,无论进行哪种操作,究其本质,负载都可以理解为「完成任务所需的时间」。由于在联邦学习中,训练模型的计算总量是固定的,因此如果我们能通过自适应的方式智能分配计算任务,便能够使得每个设备完成计算任务的耗时相同,确保整体训练的时间最优。而为了得到一个好的分配方式,我们需要首先得到模型和设备相关信息,然后再进行实际的适当分配操作。因此,对于训练模型,我们需要分为两个阶段:基准测试和分配。
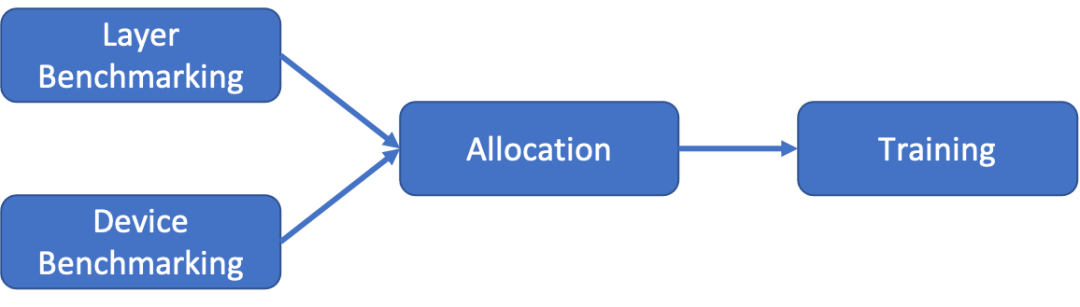
训练过程
基准测试
在基准测试阶段,Sky Computing 需要收集来自两个维度的数据:模型和设备。在模型维度,需要知道模型每一层所需的内存占用和计算量。通过结合模型的预计内存占用和设备的可用内存,可避免内存溢出;而所需计算量越大,同一设备完成该任务的时间就越久。在设备维度,需要知道设备的通讯延时、计算能力和可用内存等,受网络环境、当前运行负载等因素的影响。对于算力强、通信好但可用内存少的设备,应在内存不溢出的前提下,尽量多分配模型层(计算任务)。由于 Sky Computing 是一个负载均衡的联邦学习系统,因此我们在基准测试阶段只关心设备的机器学习的能力。通过在每个设备运行小型的机器学习测试任务,测探设备的 AI 计算能力。
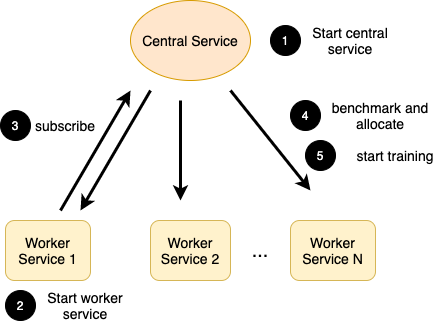
整体流程
分配
在决定任务分配方式时,经数学分析可知,分配方式本质上是一个 NP-hard 的混合整数线性规划问题。因此,在多项式时间内,我们无法得到一个最优解。而随着模型规模的不断增长,和设备数量的不断增多,计算最优解的成本显然是不可接受的。
因此,在实际情况中,我们不会直接计算求得最优解,而是尝试使用启发式算法得到近似解。在 Sky Computing 中,我们设计了一个两阶段的启发式算法:第一阶段为预分配,按照设备的实际可用内存大小进行模型的分配,并且计算每个设备实际的工作负载;第二阶段为分配调整,根据设备的负载量进行动态的调整,迭代降低整个系统的负载量。同时,为了验证 Sky Computing 的优越性,我们在实验中也设置了最优分配作为对比。
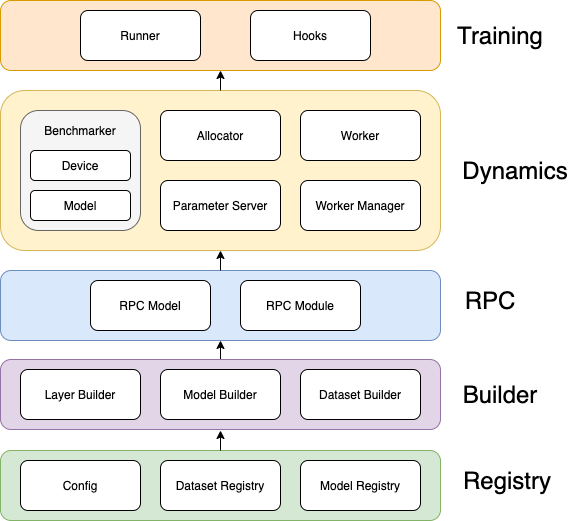
实现架构
性能表现
我们在集群环境中,采用控制关键因素变量的方式,以联邦学习 AI 任务的 forward 和 backward 的时间为指标,对 Sky Computing 的性能进行了验证。
实验结果
我们测试了三种分配方式(even:均匀分配,heuristic:启发式算法,optimal:最优分配)。在不同的计算资源数量规模和不同的模型大小下的表现,并记录了每次完成迭代所花费的时间。可以看到,随着设备数量的增多和模型深度的增加,我们的启发式算法的效果十分显著。在 64 个节点 160 层隐藏层的实验环境下,Sky Computing 比当前的均匀分配模型并行可加速 55%。
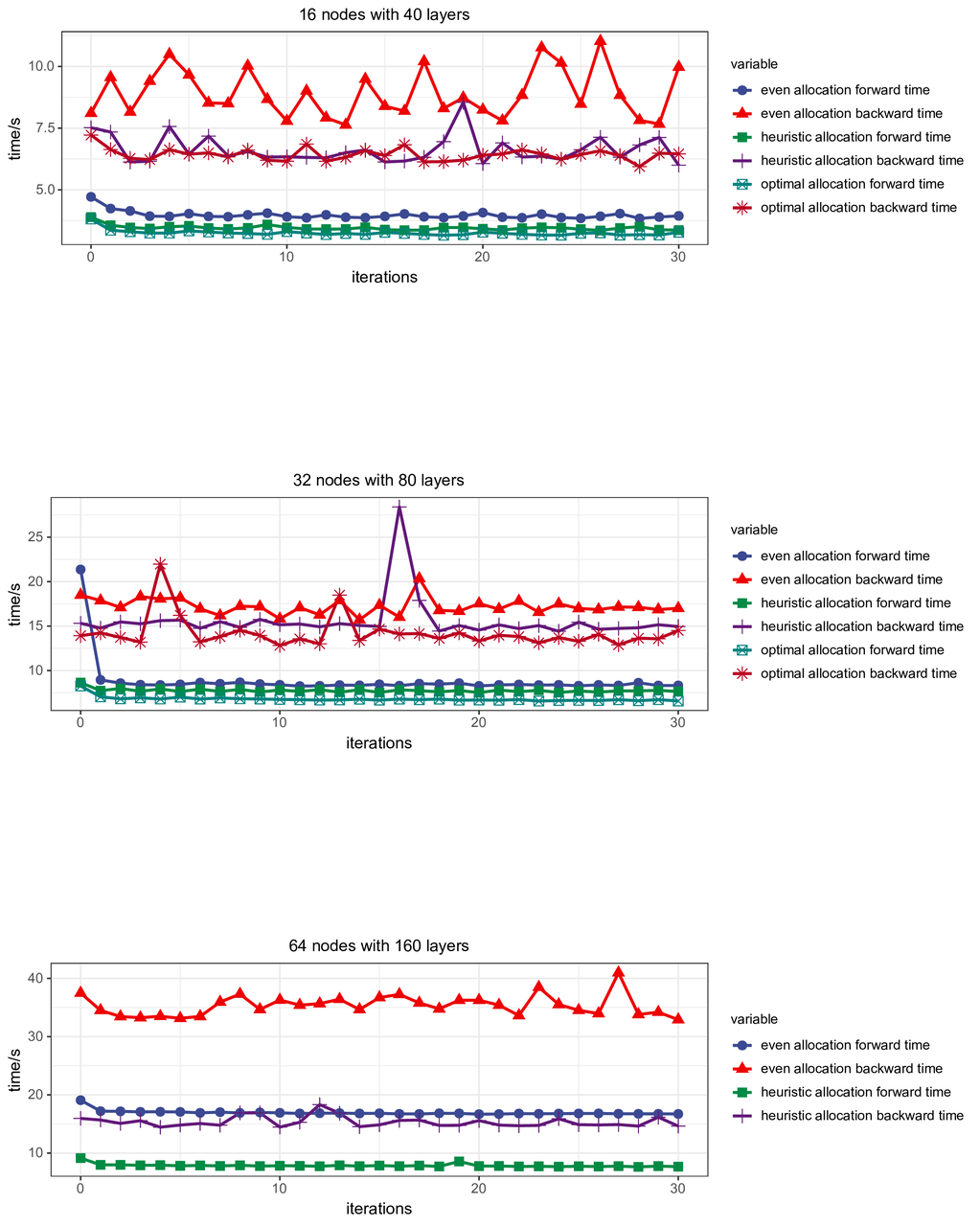
实验结果
其中,由于最优分配计算成本极高,在 64 节点时已难以计算,不适用于实际应用,仅作为小规模时的参考值。
开源共建
Sky Computing 是我们利用空间异构分布式计算特性加速联邦学习的一次成功尝试,获得了高达 55% 的性能提升。目前该项目仍处于开发阶段,未来我们将进行更加充分的实验,早日部署到实际应用中,并提供动态冗余等功能。
论文地址:https://arxiv.org/abs/2202.11836 项目地址:https://github.com/hpcaitech/SkyComputing
欢迎大家积极提 Issue 和 PR,共同为构建这一 AI 基础设施舔砖加瓦,解放 AI 生产力~
参考链接:
https://arxiv.org/abs/2104.05343
https://36kr.com/p/1619922542065412?channel=wechat
https://pdfs.semanticscholar.org/b8dc/bc29485d3ea6c0fe6ddab370ca055b9fb746.pdf