
元数据管理在数据仓库的实践应用
如果一本书是一个“数据",那么它的书名、封面、出版社、作者、总页码就是它的“元数据”。 如果一个电影是一个“数据”,那么它的总时长、制作人、总导演、演员列表就是它的“元数据”。 如果数据库中某个表是一个”数据”,那么它的列名、列类型、列长度、表注释就是它的"元数据"。
2、什么是数据仓库?
3、什么是数据仓库的元数据管理?
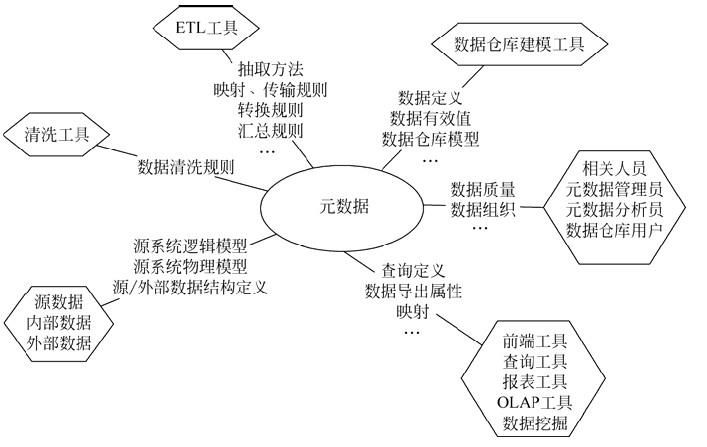
1、建设数据仓库所必须
2、帮助快速理解数仓系统
3、高效精准沟通
4、保证数据质量
5、降低数据系统建设成本
6、快速分析变更影响
7、为未来做好准备
1、业务元数据
主题定义:每段 ETL、表背后的归属业务主题。 业务描述:每段代码实现的具体业务逻辑。 标准指标:类似于 BI 中的语义层、数仓中的一致性事实;将分析中的指标进行规范化。 标准维度:同标准指标,对分析的各维度定义实现规范化、标准化。
2、技术元数据
数据清洗元数据:数据清洗,主要目的是为了解决掉脏数据及规范数据格式。因此此处元数据主要为:各表各列的"正确"数据规则;默认数据类型的"正确"规则。 数据处理元数据:数据处理,例如常见的表输入表输出;非结构化数据结构化;特殊字段的拆分等。源数据到数仓、数据集市层的各类规则。比如内容、清理、数据刷新规则。
3、管理元数据
CWM (CommonWarehouseMetamodel公共仓库元模型)是 OMG 组织在数据仓库系统中定义了一套完整的元模型体系结构,用于数据仓库构建和应用的元数据建模。公共仓库元模型指定的接口,可用于启用交换仓库之间元数据仓库和业务智能工具、仓库平台、应用的元数据建模和仓库元数据存储在分布式异构环境 CWM 元模型由一系列子元模型构成。 由于 CWM 制定时间是 2001 年,且过于细节深入,因此笔者认为其更适合作为开发参考而非开发标准。
在建设数据仓库系统的初期,只需确定源系统的元数据构成和 数仓我们想要实现的元数据内容:比如,我们只想通过元数据来管理数据仓库中数据的转换过程,以及有关数据的抽取路线,以使数据仓库开发和使用人员明白仓库中数据的整个历史过程。 确定源系统和元数据构成后,先将源系统的元数据整理并记录,可以用文档记录;也可以存入关系型数据库中。 随着数据仓库系统的建设,逐步将需要的元数据补充录入——例如 DM 的语义层、ETL 的同步规则。 数据仓库建设完成后,对元数据进行结构化、标准化储存。
1、影响分析
如果我要改动某个表、ETL,会造成怎样的影响?
2、血缘分析
血缘分析是 data science 非常重要的应用,未来笔者会单独展开介绍。
3、ETL 自动化管理
以上的规则其实就属于一部分元数据。
4、数据质量管理
数据质量管理,属于 数据治理 与 元数据管理 交集,更偏向数据治理方面。未来也会展开更详细介绍。
5、数据安全管理
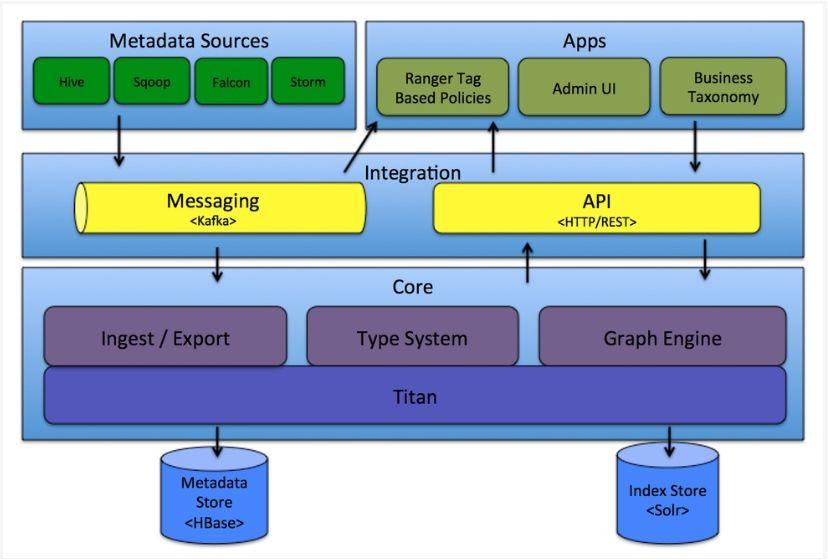
2、wherehows

支持元数据历史版本及对比分析。 一站式的元数据分析管理系统。
支持的源系统比较少 开源版本仅支持 Azkaban 调度任务的血缘分析。其他调度任务仅能获得元数据信息,而没有血缘信息。 血缘分析较粗,不支持列级血缘。如 HDFS 仅能显示数据文件之间的血缘。 Web UI 仅提供查询能力,相关配置需要调用 API 接口。 缺乏用户、权限管理能力。
3、其他
整个公司数据的集成——数据仓库的搭建 整个公司业务流程的完善——"业务中台"的实现 整个公司技术开发的统一——"技术中台"的实现
阿里所推崇的数据中台,理念上比较接近 数据仓库+元数据管理。
用 ETL 的开发举一个例子。
全部用 SQL 解决——开发很快,结果也很少出错。但未来可能要读一个上千行的 SQL。 全部用 python 解决——开发、维护的代码门槛较高,且性能相比 SQL 相差何止百倍。 python 来调度 SQL ——笔者较为推崇的方法,将处理逻辑变为 python 的函数、类,但底层逻辑使用 SQL 实现。从而达到一个相对平衡的角度。
HDFS的快照讲解
Hadoop 数据迁移用法详解
Hbase修复工具Hbck
数仓建模分层理论
一文搞懂Hive的数据存储与压缩
大数据组件重点学习这几个
评论