
Git目录为什么这么大
目录
1、介绍
2、Git 存储原理
2.1 目录结构
2.2 提交内容
2.3 如何彻底删除一个文件
3、解析 Object 存储方式
4、处理大文件
4.1 大文件的产生
4.2 寻找大文件的 ID
4.3 删除大文件
4.4 按照 pack 文件直接操作
5、大文件存储的正确方式
6、其他解决方案
7、小结

1、介绍
Git作为一个分布式的版本控制工具,在每天高频次的使用中难免遇到一些问题
本文围绕git的目录过大,从git进行版本控制底层存储出发,简要分析Git目录过大的原因,以及如何处理
2、Git 存储原理
2.1 目录结构
使用版本控制的人都会知道,不管是svn还是更为流行的git,整个工程目录下,除了项目代码外,与版本控制相关的就是.svn或.git目录
以git为例,.git下的目录结构如下
tree -L 1 .git
.git
├── COMMIT_EDITMSG
├── FETCH_HEAD
├── HEAD
├── ORIG_HEAD
├── config
├── description
├── hooks
├── index
├── info
├── logs
├── objects
├── packed-refs
├── refs
└── sourcetreeconfig
其中一些目录的说明
HEAD:表示当前本地签出的分支
hooks:
git钩子目录,关于钩子的使用可以参考我之前的文章 利用 Git 钩子实现代码发布[1]index:存储缓冲区
GitExtensions中的stage的内容objects:存储对象的目录,
git中对象分为commit对象,tree对象(多叉树),blob对象refs:存储指向
branch的最近一次commit对象的指针,也就是commit对象的sha-1值,其中heads存储branch对应的commit,tags存储tag对应的commitconfig:仓库配置,比如远程的
url,邮箱和用户名等
2.2 提交内容
git的一次提交包含4个部分:
工作目录快照名称(一个哈希值)
一条评论/注释
提交者信息
父提交的哈希值
每一个提交Commit相当于一个Patch应用在之前的项目上,借此一个项目可以回到任何一次提交时的文件状态
于是在Git中删除一个文件时,Git只是记录了该删除操作,该记录作为一个Patch存储在 .git 中。删除前的文件仍然在Git仓库中保存着。直接删除文件并提交起不到给Git仓库瘦身的效果
在Git仓库彻底删除一个文件只有一种办法:重写Rewrite涉及该文件的所有提交。借助 git filter-branch 便可以重写历史提交,当然这也是Git中最危险的操作
2.3 如何彻底删除一个文件
以一个文件的提交为例,这个文件可能会关联很多次提交,只有将每一次与该文件有关的的提交记录进行重写,才能真正实现删除这个文件,具体做法如下
# git filter-branch -f --prune-empty --index-filter 'git rm -rf --cached --ignore-unmatch api/app/test.py' --tag-name-filter cat -- --all
Rewrite 2771f50d45a0293668a30af77983d87886441640 (264/982)rm 'api/app/test.py'
Rewrite 1a98ecb3f39e1f200e31754714eec18bc92848ce (265/982)rm 'api/app/test.py'
Rewrite d4e61cfb1d88187b0561d283e663b81b738df2c7 (270/982)rm 'api/app/test.py'
Rewrite 4ba0df06b26cf86fd39c2cda6b012c521cbc4dc1 (271/982)rm 'api/app/test.py'
Rewrite 242ae98060c77863f5e826ba7e1ec47
这里要删除的文件位置是api/app/test.py
--index-filter 参数用来指定一条Bash命令,--all 参数告诉Git我们需要重写所有分支(或引用)
Git会检出checkout所有的提交, 执行该命令,然后重新提交。我们在提交前移除了 test.py 文件, 这个文件便从Git的所有记录中完全消失了
3、解析 Object 存储方式
为了一步步熟悉Object存储的方式,这里在本地创建一个空的git仓库,且objects目录中还没有任何内容,创建一个文件并提交
# mkdir git-test && cd git-test && mkdir src
# git init .
Initialized empty Git repository in /Users/ssgeek/Git-workspace/git-test/.git/
# echo "test project" > README.md
# echo "hello world" > src/demo1.txt
# git add .
# git commit -sm "first commit"
[master (root-commit) ca1114d] first commit
2 files changed, 2 insertions(+)
create mode 100644 README.md
create mode 100644 src/demo1.txt
从输出可以看到,上面的命令创建了一个commit对象,该commit包含两个文件
查看.git/objects目录,可以看到该目录下增加了4个子目录 32,3b, 4c, ca,d2,每个子目录下有一个以一长串字母数字命名的文件
# tree .git/objects
.git/objects
├── 32
│ └── 73e239f79eacf09654a5ecc18498bda0d2e7eb
├── 3b
│ └── 18e512dba79e4c8300dd08aeb37f8e728b8dad
├── 4c
│ └── 3ced11d9e650d74fa5e518b26b311f06d7069c
├── ca
│ └── 1114de8da76527ec73cdf52100eb7ba58e1878
├── d2
│ └── df53f517e6e2c85ff2b0c6b0970428889f265f
├── info
└── pack
前面提到object目录下存放的是Git为对象生成一个文件,并根据文件信息生成一个SHA-1哈希值作为文件内容的校验和,创建以该校验和前两个字符为名称的子目录,并以 (校验和) 剩下38个字符为文件命名 ,将该文件保存至子目录下
可以通过 git cat-file命令查看Git Object中存储的内容及对象类型,命令参数为Git Object的SHA-1哈希值,即目录名+文件名。一般不用输入整个Hash,输入前几位即可
当前分支的对象引用保存在HEAD文件中,可以查看该文件得到当前HEAD对应的branch,并通过branch查到对应的commit对象
# cat .git/HEAD
ref: refs/heads/master
# cat .git/refs/heads/master
ca1114de8da76527ec73cdf52100eb7ba58e1878
使用-t参数查看文件类型,使用-p参数可以查看文件内容
# git cat-file -t ca1114
commit
# git cat-file -p ca1114
tree d2df53f517e6e2c85ff2b0c6b0970428889f265f
author ssgeek <ssgeek@ssgeek.com> 1622445604 +0800
committer ssgeek <ssgeek@ssgeek.com> 1622445604 +0800
first commit
Signed-off-by: ssgeek <ssgeek@ssgeek.com>
这是一个commit对象,commit对象中保存了commit的作者,commit的描述信息,签名信息以及该commit中包含哪些tree对象和blob对象,继续看该tree对象中的内容
# git cat-file -p d2df53
100644 blob 4c3ced11d9e650d74fa5e518b26b311f06d7069c README.md
040000 tree 3273e239f79eacf09654a5ecc18498bda0d2e7eb src
# git cat-file -p 4c3ced
test project
# git cat-file -p 3273e2
100644 blob 3b18e512dba79e4c8300dd08aeb37f8e728b8dad demo1.txt
# git cat-file -p 3b18e5
hello world
因此可以得知,git 中存储了三种类型的对象,commit,tree和blob,三者分别对应git commit,此commit中的目录和文件,这些对象之间的关系如下图
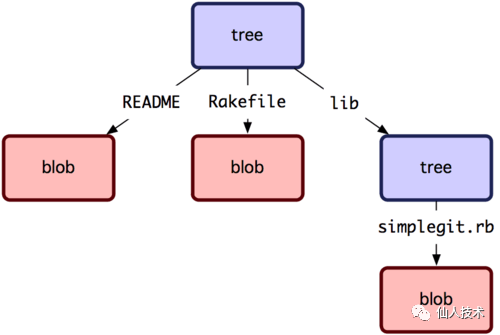
4、处理大文件
4.1 大文件的产生
由上面的详细分析流程可以看出,git会为每一个提交到版本控制的文件进行追踪,那么大文件究竟如何产生呢?
在上面的object目录下还存在着pack和info文件夹。Git往磁盘保存对象时默认使用的格式叫松散对象loose object格式,当你对同一个文件修改哪怕一行,git都会使用全新的文件存储这个修改了的文件,放在了objects中。Git时不时地将这些对象打包至一个叫packfile的二进制文件以节省空间并提高效率,当版本库中有太多的松散对象,或者你手动执行 git gc 命令,或者你向远程服务器执行推送时,Git都会这样做
因此,往往在向git中提交了大文件,会造成pack文件过大,到这里“元凶”终于出现了
4.2 寻找大文件的 ID
以我的博客代码为例操作
首先查找出大文件
# git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | sort -k 3 -n | tail -5 | awk '{print$1}')"
385321b5a0be589af4436ddc6dd0d08a687f8d80 pdf/test/1.gif
21224e779a19dfe7f716eb031d7c69ad65fb684c pdf/test/2.gif
b615ba62e75bdb1c1faca8c43a82c5ef810d7e20 pdf/test/3.gif
cd5762af542f724ca44656f02936940cf6de6525 zip/1.zip
089977cb9de0105969d57bb070f6df0240b9da63 pdf/test/search_index.json
参数说明:
rev-list 命令用来列出 Git 仓库中的提交,我们用它来列出所有提交中涉及的文件名及其 ID。该命令可以指定只显示某个引用(或分支)的上下游的提交 --objects 列出该提交涉及的所有文件 ID --all 所有分支的提交,相当于指定了位于/refs 下的所有引用 verify-pack 命令用于显示已打包的内容,我们用它来找到那些大文件 -v(verbose)参数是打印详细信息
4.3 删除大文件
# git filter-branch --force --prune-empty --index-filter 'git rm -rf --cached --ignore-unmatch YOU-FILE-NAME' --tag-name-filter cat -- --all
参数说明:
filter-branch 命令可以用来重写 Git 仓库中的提交 --index-filter 参数用来指定一条 Bash 命令,然后 Git 会检出(checkout)所有的提交, 执行该命令,然后重新提交 –all 参数表示我们需要重写所有分支(或引用) YOU-FILE-NAME 你查找出来的大文件名字
也可以将上面查找出的大文件输出重定向输入到某个文件,这样更便于操作
# 定向到文件
# git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | sort -k 3 -n | tail -5 | awk '{print$1}')" >> large-files.txt
# 得到文件路径并批量删除
# cat large-files.txt| awk '{print $2}' | tr '\n' ' ' >> large-files-inline.txt
# git filter-branch -f --prune-empty --index-filter "git rm -rf --cached --ignore-unmatch `cat large-files-inline.txt`" --tag-name-filter cat -- --all
# 或者直接删除目录下的所有文件
# git filter-branch --force --index-filter 'git rm -rf --cached --ignore-unmatch gitbook/**' --prune-empty --tag-name-filter cat -- --all
强制推送
# git push --force --all
本地的repo里面仍然保留了这些objects, 等待GC垃圾回收,因此需要彻底清除并收回空间
# rm -rf .git/refs/original/
# git reflog expire --expire=now --all
# git gc --prune=now
Enumerating objects: 40395, done.
Counting objects: 100% (40395/40395), done.
Delta compression using up to 8 threads
Compressing objects: 100% (5546/5546), done.
Writing objects: 100% (40395/40395), done.
Total 40395 (delta 19454), reused 35405 (delta 16700), pack-reused 0
Removing duplicate objects: 100% (256/256), done.
4.4 按照 pack 文件直接操作
除了上面的方式,也可以通过直接找到大的pack文件,基于这些文件进行快速操作
# 找到pack文件,重建索引
git filter-branch --index-filter 'git rm -r --cached --ignore-unmatch .git/objects/pack/xxxxx.pack' --prune-empty
# 删除和重建的索引
# git for-each-ref --format='delete %(refname)' refs/original | git update-ref --stdin
# 设置reflog过期
git reflog expire --expire=now --all
# 清理垃圾
git gc --aggressive --prune=now
5、大文件存储的正确方式
大文件一般是不建议直接存储到git仓库中的,git仓库是代码仓库,存放的应该是n个代码文件(其实也可以认为是文本文件)
如果是作为仓库管理员,应该有意识的将git仓库设置一个允许的文件大小限制
如果是非变化性的大文件,可以存储到专用的文件服务器、对象存储等
如果非要在版本库中存储大文件,更好的方式是通过git-lfs,及时使用 lfs 来追踪、记录和管理大文件。这样大文件既不会污染我们的 .git 目录,也可以让我们更方便的使用,这里不多做原理展开,
简单来说操作方法如下
# 1.开启lfs功能
# git lfs install
# 2.追踪所有后缀名为“.psd”的文件
# git lfs track "*.iso"
# 3.追踪单个文件
git lfs track "logo.png"
# 4.提交存储信息文件
# git add .gitattributes
# 5.提交并推送到GitHub仓库
# git add .
# git commit -m "Add some files"
# git push origin master
关于git-lfs的使用及原理说明可以参考国内的gitee官方帮助说明文档Git LFS 操作指南[2]
6、其他解决方案
除了上面的操作,还可以利用更为好用的开源效率工具bfg进行清理,参考`bfg`文档[3],配置好java环境后,操作如下
# 下载封装好的jar包
$ wget https://repo1.maven.org/maven2/com/madgag/bfg/1.13.0/bfg-1.13.0.jar
# 克隆的时候需要--mirror参数
$ git clone --mirror git://example.com/big-repo.git
# 运行BFG来清理存储库
$ java -jar bfg.jar --strip-blobs-bigger-than 100M big-repo.git
# 去除脏数据
$ cd big-repo.git
$ git reflog expire --expire=now --all
$ git gc --prune=now --aggressive
# 推送上去
# 此推将更新远程服务器上的所有refs分支
$ git push
其他用法
# 删除所有的名为'id_dsa'或'id_rsa'的文件
$ java -jar bfg.jar --delete-files id_{dsa,rsa} my-repo.git
# 删除所有大于50M的文件
$ java -jar bfg.jar --strip-blobs-bigger-than 50M my-repo.git
# 删除文件夹下所有的文件
$ java -jar bfg.jar --delete-folders doc my-repo.git
7、小结
本文分析了git底层版本控制的存储实现,分析了版本控制系统中大文件的产生,并通过一定手段进行解决。
要提到的是,上面的操作难免也会出现风险,如果是作为一个规范的代码仓库,应该在前期就做好规划,避免大文件提交到仓库,规范每一次的提交记录,做好code review及仓库管理
See you ~
参考资料
利用 Git 钩子实现代码发布: https://www.ssgeek.com/post/li-yong-git-gou-zi-shi-xian-dai-ma-fa-bu/
[2]Git LFS 操作指南: https://gitee.com/help/articles/4235#article-header9
[3]bfg文档: https://rtyley.github.io/bfg-repo-cleaner/
https://harttle.land/2016/03/22/purge-large-files-in-gitrepo.html#header-6