
CV和NLP中的无监督预训练(生成式BERT/iGPT和判别式SimCLR/SimCSE)
共 5406字,需浏览 11分钟
·
2021-06-03 10:24

极市导读
本文归纳了一下CV和NLP各自领域的生成式和判别式的代表作及设计思路。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
在之前的文章中讲过unsupervised learning主要分为生成式和判别式,那么unsupervised pretrain自然也分为生成式和判别式。目前CV和NLP都出现了非常强大的无监督预训练,并且在生成式和判别式都各有造诣,本文主要想归纳一下CV和NLP各自领域的生成式和判别式的代表作及设计思路。其中CV的生成式以iGPT为例,判别式以SimCLR为例;NLP的生成式以BERT为例,判别式以SimCSE为例。有意思的是,iGPT的灵感来源于BERT,而SimCSE的灵感来源于SimCLR,这充分展现了CV和NLP两个方向相互哺育,相辅相成的景象。
BERT
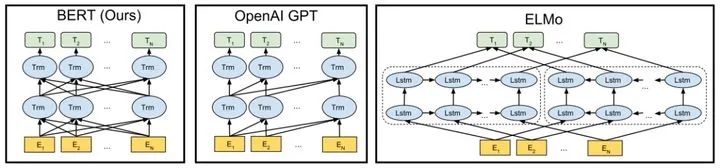
BERT之前主要有两种主流的无监督预训练方法:feature-based和fine-tuning。
feature-based方法
之前的ELMo无监督预训练属于feature-based的方法,先独立训练从左到右和从右到左的LSTM,然后将两部分输出conate得到的features直接应用于下游任务。
fine-tuning方法
GPT和BERT属于fine-tuning方法,fine-tuning方法预训练的features不直接应用于下游任务,需要针对下游任务进行fine-tuning。
GPT使用从左到右的单向Transformer进行预训练,然后针对下游任务进行fine-tuning。
BERT使用双向Transformer进行预训练,相较于GPT,更加充分的利用上下文信息,然后针对下游任务进行fine-tuning。
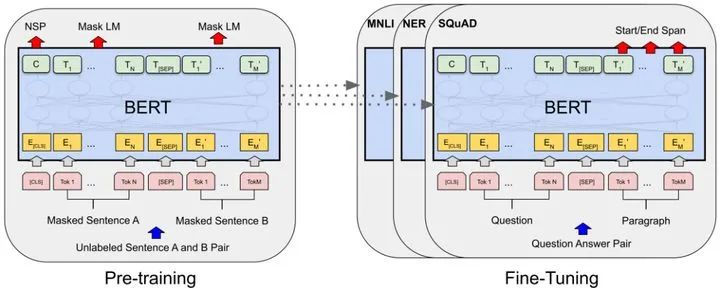
Input/Output Representations
为了BERT更好的应用于下游任务,BERT预训练的时候输入可以模糊表示,比如既可以表示成单个句子也可以表示成一对句子(<Question,Answer>)。输入的第一个token总是特指classification token [CLS],对应的输出位置用来做分类任务。一对句子作为输入时,表示成单个序列,通过特殊的token [SEP]来分开不同句子,并且对每个输入token加上一个可学习的embedding来指示属于句子A还是属于句子B。如上面左图所示,将input embedding表示为E,token [CLS]对应的输出向量是C,第i个input token的输出是。
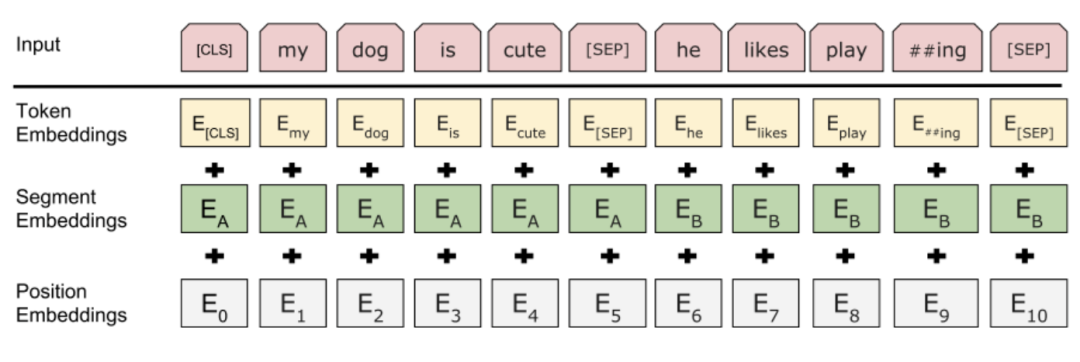
其中input embedding由Position Embeddings、Segment Embeddings和Token Embeddings三部分相加得到。Position Embeddings指示不同token的顺序,Segment Embeddings指示不同token属于哪个句子,Token Embeddings指示不同token的语义信息。
Pre-training BERT
BERT设计了两种无监督任务进行预训练,可以更好的应用到下游任务。
Task #1:Masked LM
为了训练一个深度双向的Transformer,BERT以一定比例随机mask掉一些输入tokens,然后对这些masked tokens进行预测,这个任务称之为Masked LM(MLM),灵感来源于完形填空任务,通过上下文预测masked的word是什么,最终BERT采用了随机mask掉15%的输入tokens。
虽然Masked LM任务可以获得一个双向的预训练模型,但是预训练和fine-tuning存在着gap,因为fine-tuning的时候,输入是不存在[MASK]token的,为了缓解这种问题,实际训练的时候不总是采用[MASK] token来替换。其中[MASK] token有80%的概率被选中,random token有10%的概率被选中,还有10%的概率不改变token。
Task #2:Next Sentence Prediction(NSP)
很多下游任务是需要理解句子对之间的关系的,为了帮助下游任务更好的理解句子对之间的关系,BERT还设计了另一个预训练任务next sentence prediction(NSP)。具体的,选择句子A和句子B作为预训练的输入,有50%的概率B是A的下一个句子(标记为IsNext),有50%的概率B不是A的下一个句子(标记为NotNext),实际上就是一个二分类模型。如上面左图所示,C被用于NSP任务进行二分类。
iGPT
iGPT和BERT思路非常类似,只不过iGPT是在图像上进行的。
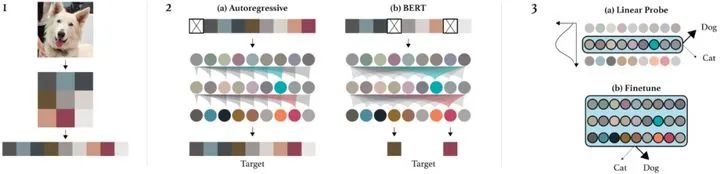
iGPT首先将输入图片resize然后reshape成1维序列。然后选择两种方法进行预训练,其中Autoregressive的目标是预测next pixel prediction(类似GPT单向模型),BERT的目标是masked pixel prediction(类似BERT的MLM任务)。最后,iGPT用linear probes(直接使用feature,类似feature-based的方法)或着fine-tuning两种方法来评估学习到的特征。
iGPT可以通过图像的上下文信息预测出masked的pixel,跟BERT有着异曲同工之妙。
看一下iGPT的生成效果,iGPT可以通过已知的上下文内容对缺失部分进行补充,看起来非常的逻辑自洽啊,tql

SimCLR
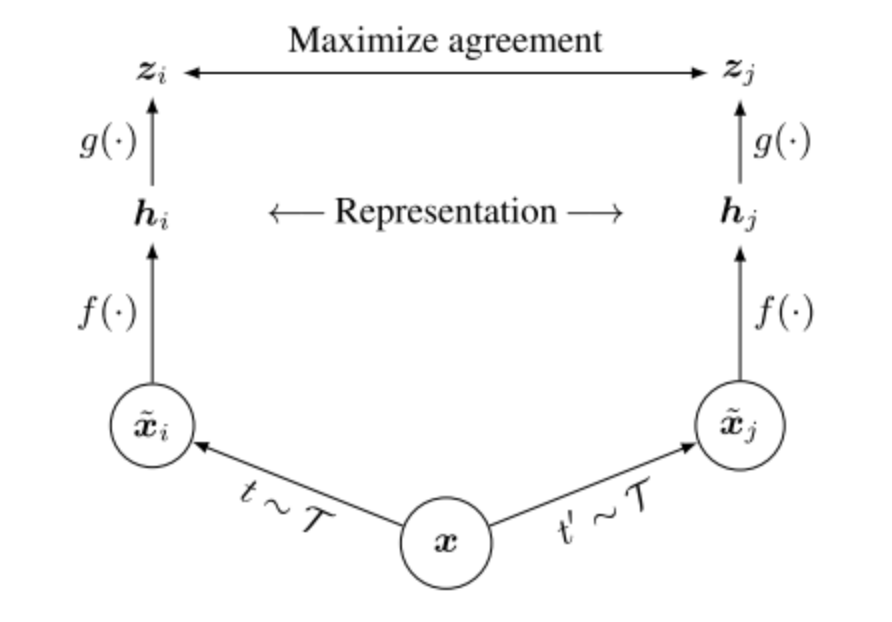
SimCLR是一种非常简单直接的self-supervised方法。SimCLR框架流程如下:
1.对于每张输入图片随机进行数据增强得到两个不同的views,同一张图的两个views可以认为是positive pair。
2.每张输入图片的两个views通过相同的encoder产生两个表示向量。
3.每张输入图片的两个表示向量通过相同的projection head产生两个最终的向量。
4.最后对一个batch得到的最终向量进行对比学习,拉近positive pair,排斥negative pair。
对比学习的函数如下:
伪代码如下:

一个batch有N个图片,通过不同的数据增强产生2N个views,一个positive pair可以交换位置得到两个loss,因此可以将一对positive pair的loss写成positive pair交换位置的两个loss之和的平均值,那么总的loss则是2N个views的loss的平均值。
SimCSE
看到计算机视觉的self-supervised大获成功之后,自然语言处理也开始尝试self-supervised。其中SimCSE的方法非常的简单有效,在Sentence Embeddings的任务中大幅度超过之前的方法。
SimCSE名字应该是借鉴了SimCLR。SimCSE提出了两种方法,一种是Unsupervised SimCSE,另一种是Supervised SimCSE。
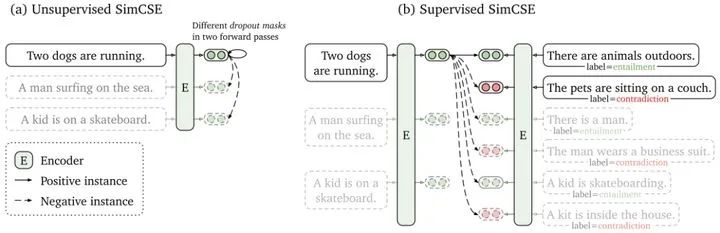
Unsupervised SimCSE的整体框架和SimCLR基本上保持一致。如图(a)所示,将同一个句子通过两种随机的mask得到两个postive pair(实线),不同句子的mask句子是negative pair(虚线),然后通过对比学习的方法,拉近positive pair,排斥negative pair。其中随机mask句子其实就是句子的数据增强,SimCSE实验发现随机mask掉10%效果最好。
Supervised SimCSE的positive pair和negative pair是有标注的。其中不同句子的entailment和contradiction都是negative pair,只有相同句子的entailment是positive pair。如图(b)所示,第一个句子跟自己的entailment是positive pair(实线),跟其他句子的entailment/contradiction都是positive pair(虚线)。
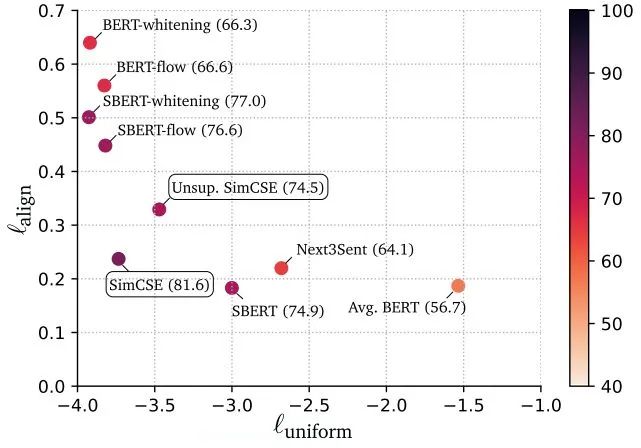
上图align表示positive pair拉近的能力(越小越好),uniform表示negative pair排斥的能力(越小越好)。最终SimCSE可视化分析发现,Unsup. SimCSE可以得到更好的align和uniform,SimCSE通过有标注的监督信号,可以进一步的提升align和uniform。
另外,SimCSE还有各种消融实验和可视化分析,非常精彩,建议看原文细细品味
总结
下面引用lecun的一张图,谈一谈对CV和NLP中无监督预训练的看法
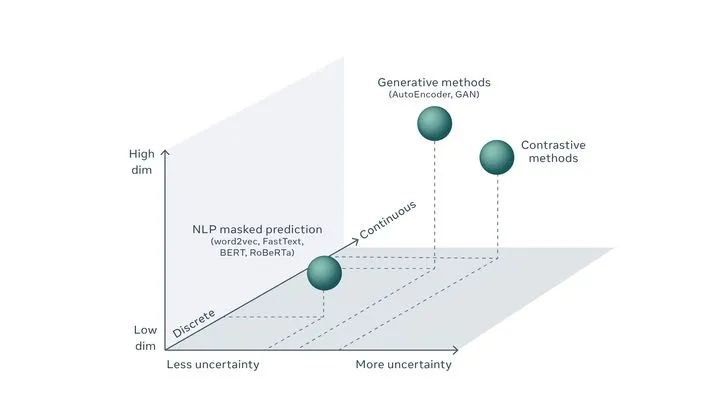
lecun通过Low dim -> High dim、Discrete -> Continuous和Less uncertainty -> More uncertainty三个维度来表示CV和NLP中不同无监督方法的位置。文本是离散的,不确定性低,维度低;而图像是连续的,不确定性高,维度高。模态的不同,导致了无监督的处理方式上的不同。
NLP任务因为确定性更高,生成式无监督预训练方法可以非常好进行预测(如BERT),而由于CV任务不确定性更高,导致需要设计更自由灵活的方法,对比方法相比于生成方法自由度更高,可能更加适合CV任务作为无监督预训练方法。
猜测未来NLP领域生成式和判别式会出现并存的局面,sentence级别任务倾向于使用判别式,word级别任务倾向于使用生成式。而CV领域判别式会占主导地位,一方面由于图像是二维的,生成式计算量会更庞大,另一方面判别式的自由度会更高一些。
Reference
[1] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[2] Generative Pretraining from Pixels
[3] A Simple Framework for Contrastive Learning of Visual Representations
[4] SimCSE: Simple Contrastive Learning of Sentence Embeddings
[5] Self-supervised learning: The dark matter of intelligence (facebook.com)
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“83”获取朱思语:基于深度学习的视觉稠密建图和定位直播链接~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
