
DeepMind重磅宣告:通用人工智能(AGI)实现,Reward is enough!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
编辑:小舟、陈萍
通用人工智能,用强化学习的奖励机制就能实现吗?


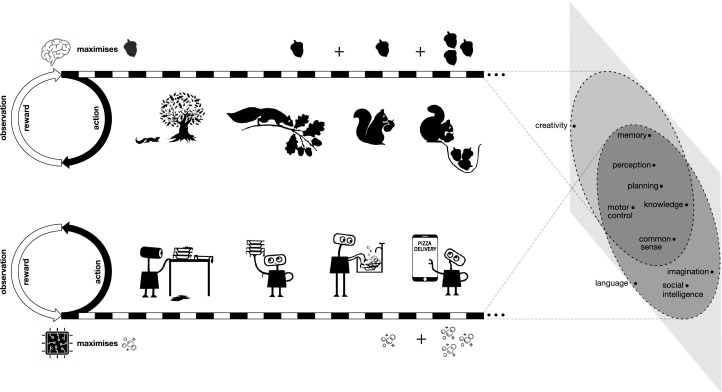
动作和观察通常交织在多种感知形式中,例如触觉感知、视觉扫视、物理实验、回声定位等;
感知的效用通常取决于智能体的行为;
获取信息可能具有显式和隐式成本;
数据的分布通常依赖于上下文,在丰富的环境中,潜在数据多样性可能远远超过智能体的容量或已存在数据的数量——这需要从经验中获取感知;
感知的许多应用程序无法获得有标记的数据。
语言通常是上下文相关的,不仅与所说的内容相关,还与智能体周围环境中正在发生的其他事情有关,有时需要通过视觉和其他感官模式感知。此外,语言经常穿插其他表达行为,例如手势、面部表情、音调变化等。
语言是有目的并能对环境产生影响的。例如,销售人员学习调整他们的语言以最大化销售额。
语言的具体含义和效用因智能体的情况和行为而异。例如,矿工可能需要有关岩石稳定性的语言,农民可能需要有关土壤肥力的语言。此外,语言可能存在机会成本,例如讨论农业的人并不一定是从事农业工作)。
在丰富的环境中,语言处理不可预见事件的潜在用途可能超出任何语料库的能力。在这些情况下,可能需要通过经验动态地解决语言问题。例如开发一项新技术或找到一种方法来解决一个新的问题。
其他智能体可能是智能体的环境的组成部分(例如婴儿观察其母亲),而无需假设存在包含教师数据的特殊数据集;
智能体可能需要学习它自己的状态与另一个智能体的状态之间的关联,或者智能体自己的动作和另一个智能体的观察结果,这可能会产生更高的抽象级别;
其他智能体可能只能被部分观察到,因此他们的行为或目标可能只是被不完美地推断出来;
其他智能体可能会表现出应避免的不良行为;
环境中可能有许多其他智能体,表现出不同的技能或不同的能力水平。

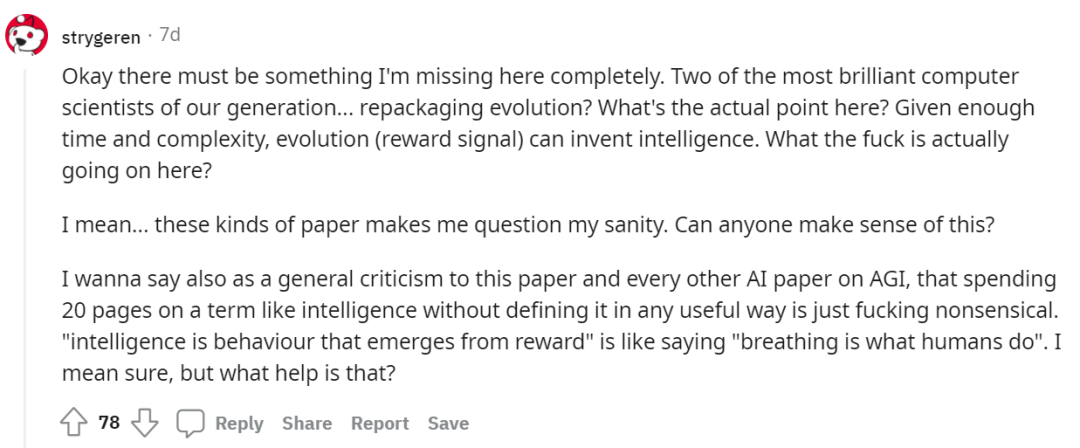
如此优秀的两位计算机科学家这是在重新包装进化论?这里的实际意义是什么?如果有足够的时间和复杂性,进化(奖励信号)可以发明智能。这有什么意义?智能需要从奖励中获得就像是在表述「人会呼吸」,这似乎是句废话。



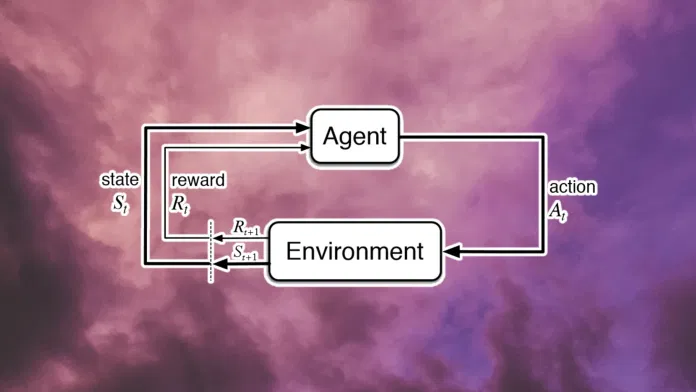
最终目标奖励是否会产生一般的智能,或者是否会产生一些额外的信号?纯奖励信号是否会陷入局部最大值?他们的论点是,对于一个非常复杂的环境,它不会。 但如果你有一个足够复杂的环境,模型有足够的参数,并且你不会陷入局部最大值,那么一旦系统解决了问题中的琐碎,简单的部分,唯一的方法是提高性能,创建更通用的解决方案,即变得更智能。
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
