
时间轮在Kafka的实践

桔妹导读:时间轮是一个应用场景很广的组件,在很多高性能中间件中都有它的身影,如Netty、Quartz、Akka,当然也包括Kafka,本文主要介绍时间轮在kafka的应用和实战,从核心源码和设计的角度对时间轮进行深入的讲解 。
1.

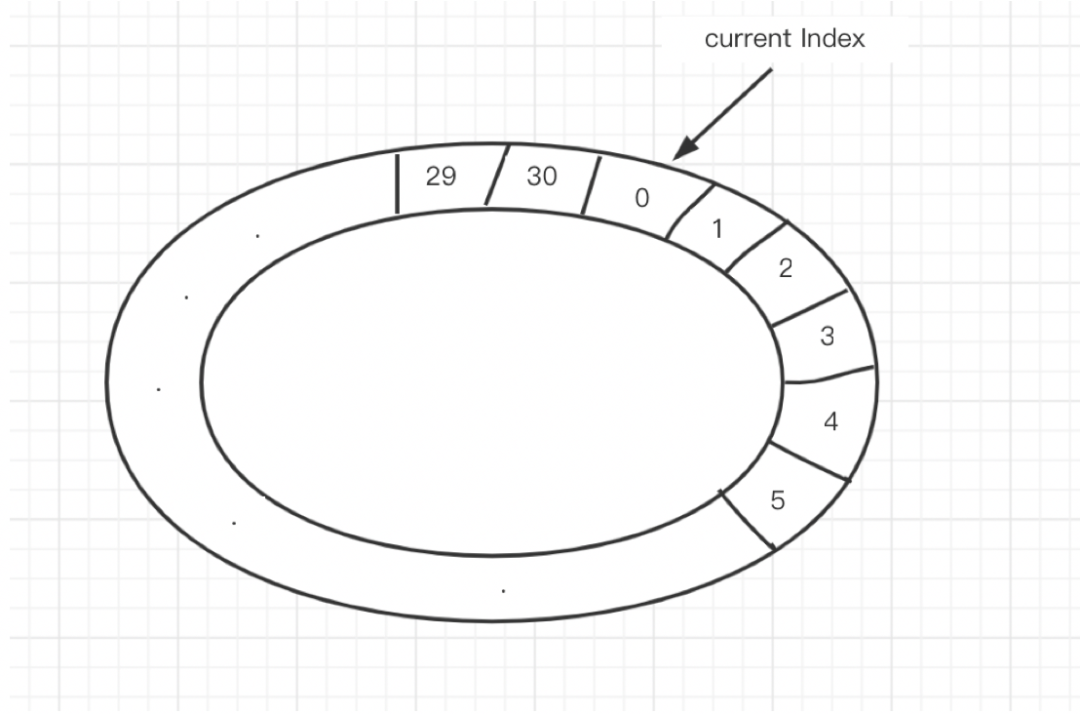
30s超时,就创建一个index从0到30的环形队列(本质是个数组) 环上每一个slot是一个Set<uid>,任务集合 同时还有一个Map<uid, index>,记录uid落在环上的哪个slot里
从Map结构中,查找出这个uid存储在哪一个slot里 从这个slot的Set结构中,删除这个uid 将uid重新加入到新的slot中,具体是哪一个slot呢 => Current Index指针所指向的上一个slot,因为这个slot,会被timer在30s之后扫描到 更新Map,这个uid对应slot的index值
2.
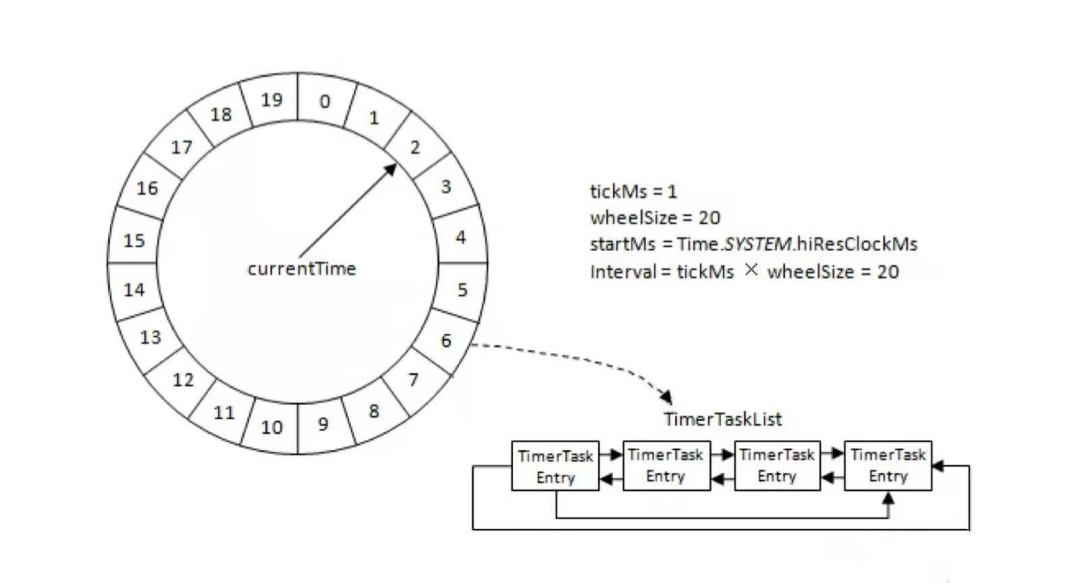 图二
图二tickMs:时间轮由多个时间格组成,每个时间格就是tickMs,它代表当前时间轮的基本时间跨度。 wheelSize:代表每一层时间轮的格数 interval:当前时间轮的总体时间跨度,interval=tickMs × wheelSize startMs:构造当层时间轮时候的当前时间,第一层的时间轮的startMs是TimeUnit.NANOSECONDS.toMillis(nanoseconds()),上层时间轮的startMs为下层时间轮的currentTime。 currentTime:表示时间轮当前所处的时间,currentTime是tickMs的整数倍(通过currentTime=startMs - (startMs % tickMs来保正currentTime一定是tickMs的整数倍),这个运算类比钟表中分钟里65秒分钟指针指向的还是1分钟)。currentTime可以将整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的TimerTaskList的所有任务。
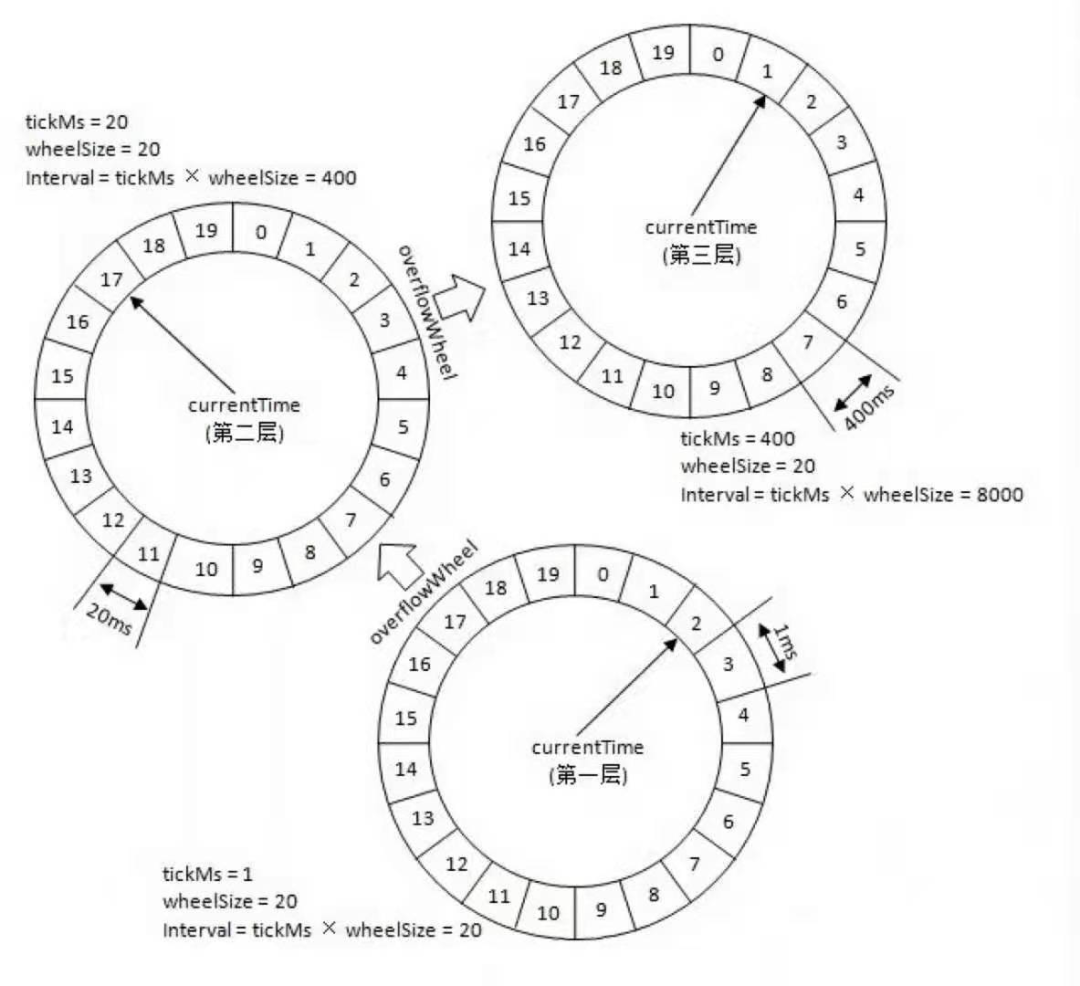
刚才提到的350ms的任务,不会插入到第一层时间轮,会插入到interval=20*20的第二层时间轮中,具体插入到时间轮的哪个bucket呢?先用350/tickMs(20)=virtualId(17),然后virtualId(17) %wheelSize (20) = 17,所以350会放在第17个bucket。如果此时有一个450ms后执行的任务,那么会放在第三层时间轮中,按照刚才的计算公式,会放在第0个bucket。第0个bucket里会包含[400,800)ms的任务。随着时间流逝,当时间过去了400ms,那么450ms后就要执行的任务还剩下50ms的时间才能执行,此时有一个时间轮降级的操作,将50ms任务重新提交到层级时间轮中,那么此时50ms的任务根据公式会放入第二个时间轮的第2个bucket中,此bucket的时间范围为[40,60)ms,然后再经过40ms,这个50ms的任务又会被监控到,此时距离任务执行还有10ms,同样将10ms的任务提交到层级时间轮,此时会加入到第一层时间轮的第10个bucket,所以再经过10ms后,此任务到期,最终执行。
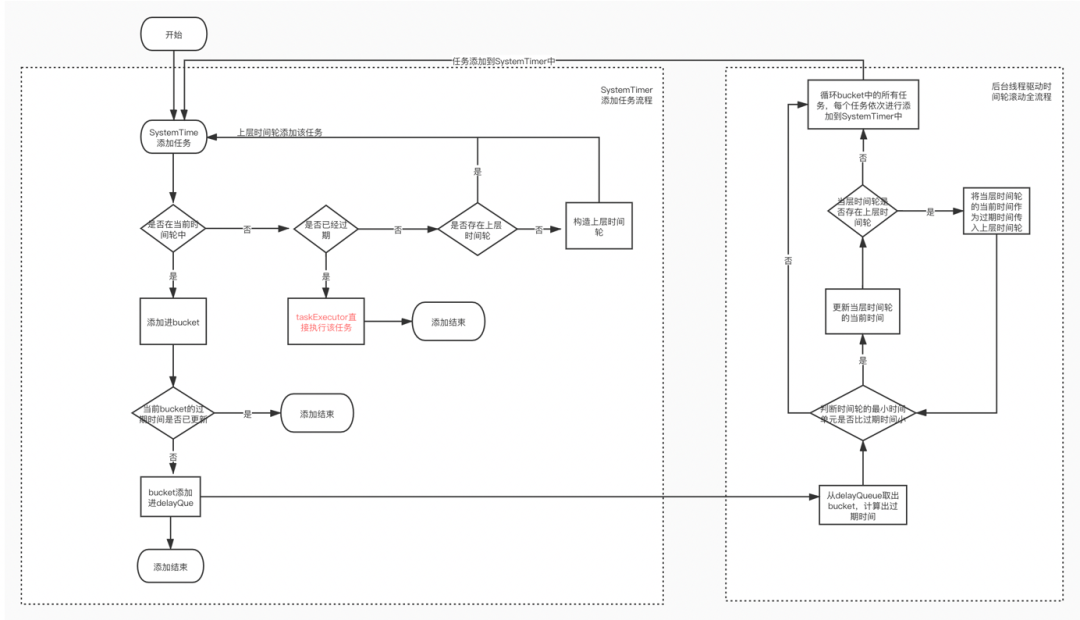
//在Systemtimer中添加一个任务,任务被包装为一个TimerTaskEntryprivate def addTimerTaskEntry(timerTaskEntry: TimerTaskEntry): Unit = {//先判断是否可以添加进时间轮中,如果不可以添加进去代表任务已经过期或者任务被取消,注意这里的timingWheel持有上一层时间轮的引用,所以可能存在递归调用if (!timingWheel.add(timerTaskEntry)) {// Already expired or cancelledif (!timerTaskEntry.cancelled)//过期任务直接线程池异步执行掉taskExecutor.submit(timerTaskEntry.timerTask)}}timingWheel添加任务,递归添加直到添加该任务进合适的时间轮的bucket中def add(timerTaskEntry: TimerTaskEntry): Boolean = {val expiration = timerTaskEntry.expirationMs//任务取消if (timerTaskEntry.cancelled) {// Cancelledfalse} else if (expiration < currentTime + tickMs) {// 任务过期后会被执行false} else if (expiration < currentTime + interval) {//任务过期时间比当前时间轮时间加周期小说明任务过期时间在本时间轮周期内val virtualId = expiration / tickMs//找到任务对应本时间轮的bucketval bucket = buckets((virtualId % wheelSize.toLong).toInt)bucket.add(timerTaskEntry)// Set the bucket expiration time//只有本bucket内的任务都过期后才会bucket.setExpiration返回true此时将bucket放入延迟队列if (bucket.setExpiration(virtualId * tickMs)) {//bucket是一个TimerTaskList,它实现了java.util.concurrent.Delayed接口,里面是一个多任务组成的链表,图2有说明queue.offer(bucket)}true} else {// Out of the interval. Put it into the parent timer//任务的过期时间不在本时间轮周期内说明需要升级时间轮,如果不存在则构造上一层时间轮,继续用上一层时间轮添加任务if (overflowWheel == null) addOverflowWheel()overflowWheel.add(timerTaskEntry)}}
private[this] def addOverflowWheel(): Unit = {synchronized {if (overflowWheel == null) {overflowWheel = new TimingWheel(tickMs = interval,wheelSize = wheelSize,startMs = currentTime,taskCounter = taskCounter,queue)}}}
def advanceClock(timeMs: Long): Unit = {if (timeMs >= currentTime + tickMs) {//把当前时间打平为时间轮tickMs的整数倍currentTime = timeMs - (timeMs % tickMs)// Try to advance the clock of the overflow wheel if present//驱动上层时间轮,这里的传给上层的currentTime时间是本层时间轮打平过的,但是在上层时间轮还是会继续打平if (overflowWheel != null) overflowWheel.advanceClock(currentTime)}}
//循环bucket里面的任务列表,一个个重新添加进时间轮,对符合条件的时间轮进行升降级或者执行任务private[this] val reinsert = (timerTaskEntry: TimerTaskEntry) => addTimerTaskEntry(timerTaskEntry)/** Advances the clock if there is an expired bucket. If there isn't any expired bucket when called,* waits up to timeoutMs before giving up.*/def advanceClock(timeoutMs: Long): Boolean = {var bucket = delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS)if (bucket != null) {writeLock.lock()try {while (bucket != null) {//驱动时间轮timingWheel.advanceClock(bucket.getExpiration())//循环buckek也就是任务列表,任务列表一个个继续添加进时间轮以此来升级或者降级时间轮,把过期任务找出来执行bucket.flush(reinsert)//循环//这里就是从延迟队列取出bucket,bucket是有延迟时间的,取出代表该bucket过期,我们通过bucket能取到bucket包含的任务列表bucket = delayQueue.poll()}} finally {writeLock.unlock()}true} else {false}}
3.
kafka的延迟队列使用时间轮实现,能够支持大量任务的高效触发,但是在kafka延迟队列实现方案里还是看到了delayQueue的影子,使用delayQueue是对时间轮里面的bucket放入延迟队列,以此来推动时间轮滚动,但是基于将插入和删除操作则放入时间轮中,将这些操作的时间复杂度都降为O(1),提升效率。Kafka对性能的极致追求让它把最合适的组件放在最适合的位置。
▬

滴滴车险团队架构师,负责车险核心系统的架构和设计,十年互联网研发架构经验,其中五年中间件与基础架构经验,对高并发,高可用以及分布式应用的架构设计有丰富的实战经验,尤其对分布式消息队列,分布式流程编排引擎、分布式数据库中间件有较深入的研究,热爱技术,崇尚开源,是Kafka、RocketMQ、Conductor等多个知名开源项目的源码贡献者。
团队招聘
▬
滴滴车险团队基于滴滴近百万辆车和海量数据,通过线上化、科技化、数据化的手段,达到车险的降赔付、降发生,降保费,为乘客、司机、以及车队、合作伙伴提供方便快捷高效的车险金融服务。
团队长期招聘java高级工程师和技术专家,欢迎有兴趣的小伙伴加入,可投递简历至 diditech@didiglobal.com,邮件请邮件主题请命名为「姓名-应聘部门-应聘方向」。
扫码了解更多岗位
延伸阅读



