
Kafka 和 DistributedLog 技术对比
因为两者都是处理日志,数据模型也类似,所以这篇文章主要从技术角度讨论 Apache Kafka 与 DistributedLog 的不同点。我们会尽量做到客观,但由于我们不是 Apache Kafka 的专家,因此我们可能会对 Apache Kafka 存在误解。如果发现有错,也请大家直接指出。
首先,让我们简单地介绍一下 Kafka 和 DistributedLog 的概况。
Kafka 是什么?
Kafka 是最初由 Linkedin 开源出来的一套分布式消息系统,现在由 Apache 软件基金会管理。这是一套基于分区的发布 / 订阅系统。Kafka 中的关键概念就是 Topic。一个 Topic 下面会有多个分区,每个分区都有备份,分布在不同的代理服务器上。生产者会把数据记录发布到一个 Topic 下面的分区中,具体方式是轮询或者基于主键做分区,而消费者会处理 Topic 中发布出来的数据记录。所有数据都是发布给相应分区的主代理进程,再复制到从代理进程,所有的读数据请求也都是依次由主代理处理的。从代理仅仅用于数据的冗余备份,并在主代理无法继续提供服务时顶上。图一的左边部分显示了 Kafka 中的数据流。
DistributedLog 是什么?
与 Kafka 不同,DistributedLog 并不是一个基于分区的发布 / 订阅系统,它是一个复制日志流仓库。DistributedLog 中的关键概念是持续的复制日志流。一个日志流会被分段成多个日志片段。每个日志片段都在 Apache BookKeeper 中存储成 Apache BooKeeper 中的一个账目,其中的数据会在多个Bookie(Bookie 就是Apache BookKeeper 的存储节点)之间复制和均衡分布。一个日志流的所有数据记录都由日志流的属主排序,由许多个写入代理来管理日志流的属主关系。应用程序也可以使用核心库来直接追加日志记录。这对于复制状态机一类对于顺序和排他写有着非常高要求的场景非常有用。每个追加到日志流末尾的日志记录都会被赋予一个序列号。读者可以从任何指定的序列号开始读日志流的数据。读请求也会在那个流的所有存储副本上做负载均衡。图一的右半部分显示了DistributedLog 中的数据流。
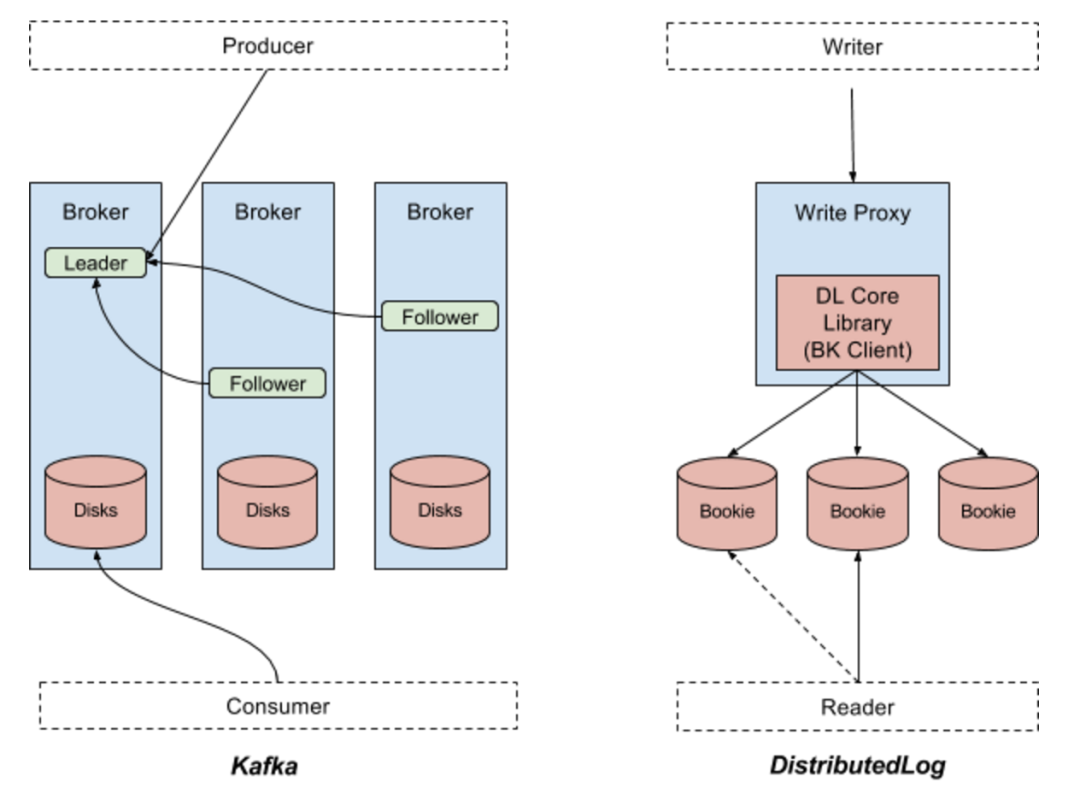
图一:Apache Kafka 与Apache DistributedLog
Kafka 与 DistributedLog 有什么不同?
因为同类事物才有可比较的基础,所以我们只在本文中把 Kafka 分区和 DistributedLog 流相对比。下表列出了两套系统之间最显著的不同点。

数据模型
Kafka 分区是存储在代理服务器磁盘上的以若干个文件形式存在的日志。每条记录都是一个键 - 值对,但对于轮询式的数据发布可以省略数据的主键。主键用于决定该条记录会被存储到哪个分区上以及用于日志压缩功能。一个分区的所有数据只存储在若干个代理服务器上,并从主代理服务器复制到从代理服务器。
DistributedLog 流是以一系列日志分片的形式存在的虚拟流。每个日志分片都以一条 BookKeeper 账目的形式存在,并被复制到多个 Bookie 上。在任意时刻都只有一个活跃的日志分片接受写入请求。在特定的时间段过后,或者旧日志分片达到配置大小(由配置的日志分片策略决定)之后,或者日志的属主出故障之后,旧的日志分片会被封存,一个新的日志分片会被开启。
Kafka 分区和 DistributedLog 流在数据分片和分布的不同点决定了它们在数据持久化策略和集群操作(比如集群扩展)上的不同。
图二显示了 DistributedLog 和 Kafka 数据模型的不同点
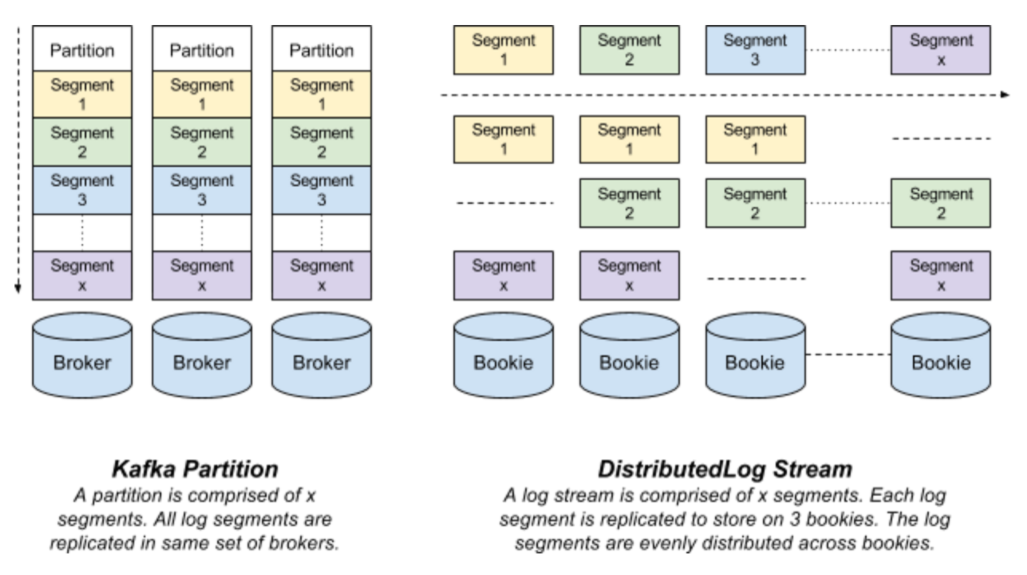
图二:Kafka 分区与DistributedLog 流
数据持久化
一个Kafka 分区中的所有数据都保存在一个代理服务器上(并被复制到别的代理服务器上)。在配置的有效期过后数据会失效并被删除。另外,也可以配置策略让Kafka 的分区保留每个主键的最新值。
与Kafka 相似,DistributedLog 也可以为每个流配置有效期,并在超时之后将相应的日志分片失效或删除。除此之外,DistributedLog 还提供了显示的截断机制。应用程序可以显式地将一个日志流截断到流的某个指定位置。这对于构建可复制的状态机非常有用,因为可复制的状态机需要在删除日志记录之前先将状态持久化。Manhattan 就是一个用到了这个功能的典型系统。
操作
数据分片和分布机制的不同也导致了维护集群操作上的不同,扩展集群操作就是一个例子。
扩展 Kafka 集群时,通常现有分区都要做重新分布。重新分布操作会将 Kafka 分区挪动到不同的副本上,以此达到均衡分布。这就要把整个流的数据从一个副本拷到另一个副本上。我们也说过很多次了,执行重新分布操作时必须非常小心,避免耗尽磁盘和网络资源。
而扩展 DistributedLog 集群的工作方式则截然不同。DistributedLog 包含两层:存储层(Apache BooKeeper)和服务层(写入和读出代理)。在扩展存储层时,我们只需要添加更多的 Bookie 就好了。新的 Bookie 马上会被写入代理发现,并立刻用于写入新的日志分片。在扩展数据存储层时不会有任何的重新分布操作。只在增加服务层时会有重新分布操作,但这个重新分布也只是移动日志流的属主权,以使网络代宽可以在各个代理之间均衡分布。这个重新分布的过程只与属主权相关,没有数据迁移操作。这种存储层和服务层的隔离不仅仅是让系统具备了自动扩展的机制,更让各种不同类型的资源可以独立扩展。
写与生产者
如图一所示,Kafka 生产者把数据一批批地写到 Kafka 分区的主代理服务器上。而 ISR (同步复制)集合中的从代理服务器会从主代理上把记录复制走。只有在主代理从所有的 ISR 集合中的副本上都收到了成功的响应之后,一条记录才会被认为是成功写入的。可以配置让生产者只等待主代理的响应,还是等待 ISR 集合中的所有代理的响应。
DistributedLog 中则有两种方式把数据写入 DistributedLog 流,一是用一个 Thrift 的瘦客户端通过写代理(众所周知的多写入)写入,二是通过 DistributedLog 的核心库来直接与存储节点交互(众所周知的单独写入)。第一种方式很适合于构建消息系统,第二种则适用于构建复制状态机。你可以查阅 DistributedLog 文档的相关章节来获取更多的信息和参考,以找到你需要的方式。
日志流的属主会并发地以BookKeeper 条目的形式向Bookie 中写入一批记录,并等待多个Bookie 的Quorum 结果。Quorum 的大小取决于BookKeeper 账目的_ack_quorum_size_ 参数,并且可以配置到DistributedLog 流的级别。它提供了和Kafka 生产者相似的在持久性上的灵活性。在接下来的“复制”一节我们会对比两者在复制算法上的更多不同之处。
Kafka 和 DistributedLog 都支持端到端的批量操作和压缩机制。但两者之间的一点微妙区别是对 DistributedLog 的写入操作都是在收到响应之前都先通过 fsync 刷到硬盘上的,而我们并没发现 Kafka 也提供了类似的可靠性保证。
读与消费者
Kafka 消费者从主代理服务器上读出数据记录。这个设计的前提就是主代理上在大多数情况下最新的数据都还在文件系统页缓存中。从充分利用文件系统页缓存和获得高性能的角度来说这是一个好办法。
DistributedLog 则采用了完全不同的方法。因为各个存储节点之间没有明确的主从关系,DistributedLog 可以从任意存储着相关数据的存储节点上读出数据。为了获得可预期的低延迟,DistributedLog 引入了一个推理式读机制,即在超出了配置的读操作时限之后,它会在不同的副本上再次尝试获取数据。这就可能会对存储节点导致比 Kafka 更高的读压力。不过,如果将读超时时间配成可以让 99% 的存储节点的读操作都不会超时,那就可以极大程度地解决延迟问题,只带来 1% 的额外读压力。
对于读的考虑和机制上的不同主要源于复制机制和存储节点的 I/O 系统的不同,在下文会继续讨论。
复制
Kafka 用的是 ISR 复制算法:将一个代理服务器选为主。所有写操作都被发送到主代理上,所有处于 ISR 集合中的从代理都从主代理上读取和复制数据。主代理会维护一个高水位线(HW,High Watermark),即每个分区最新提交的数据记录的偏移量。高水位线会不断同步到从代理上,并周期性地在所有代理上记录检查点,以备恢复之用。在所有 ISR 集合中的副本都把数据写入了文件系统(并不必须是磁盘)并向主代理发回了响应之后,主代理才会更新高水位线。
ISR 机制让我们可以增加或减少副本的数量,在可用性和性能之间做出权衡。可是扩大或缩小副本的集合的副作用是增大了丢失数据的可能性。
DistributedLog 使用的是 Quorum 投票复制算法,这在 Zab、Raft 以及 Viewstamped Replication 等一致性算法中都很常见。日志流的属主会并发地把数据记录写入所有存储节点,并在得到超过配置数量的存储节点投票确认之后,才认为数据已成功提交。存储节点也只在数据被显式地调用 flush 操作刷入磁盘之后才会响应写入请求。日志流的属主也会维护一个日志流的最新提交的数据记录的偏移量,就是大家知道的 Apache BookKeeper 中的 LAC(LastAddConfirmed)。LAC 也会保存在数据记录中(来节省额外的 RPC 调用开销),并不断复制到别的存储节点上。DistributedLog 中复本集合的大小是在每个流的每个日志分片级别可配置的。改变复制参数只会影响新的日志分片,不会影响已有的。
存储
每个 Kafka 分区都以若干个文件的形式保存在代理的磁盘上。它利用文件系统的页缓存和 I/O 调度机制来得到高性能。Kafka 也是因此利用 Java 的 sendfile API 来高效地从代理中写入读出数据的。不过,在某些情况下(比如消费者处理不及时、随机读写等),页缓存中的数据淘汰很频繁,它的性能也有很大的不确性性。
DistributedLog 用的则是不同的 I/O 模型。图三表示了 Bookie(BookKeeper 的存储节点)的 I/O 机制。写入(蓝线)、末尾读(红线)和中间读(紫线)这三种常见的 I/O 操作都被隔离到了三种物理上不同的 I/O 子系统中。所有写入都被顺序地追加到磁盘上的日志文件,再批量提交到硬盘上。在写操作持久化到磁盘上之后,它们就会放到一个 Memtable 中,再向客户端发回响应。Memtable 中的数据会被异步刷新到交叉存取的索引数据结构中:记录被追加到日志文件中,偏移量则在分类账目的索引文件中根据记录 ID 索引起来。最新的数据肯定在 Memtable 中,供末尾读操作使用。中间读会从记录日志文件中获取数据。由于物理隔离的存在,Bookie 节点可以充分利用网络流入带宽和磁盘的顺序写入特性来满足写请求,以及利用网络流出代宽和多个磁盘共同提供的 IOPS 处理能力来满足读请求,彼此之间不会相互干扰。
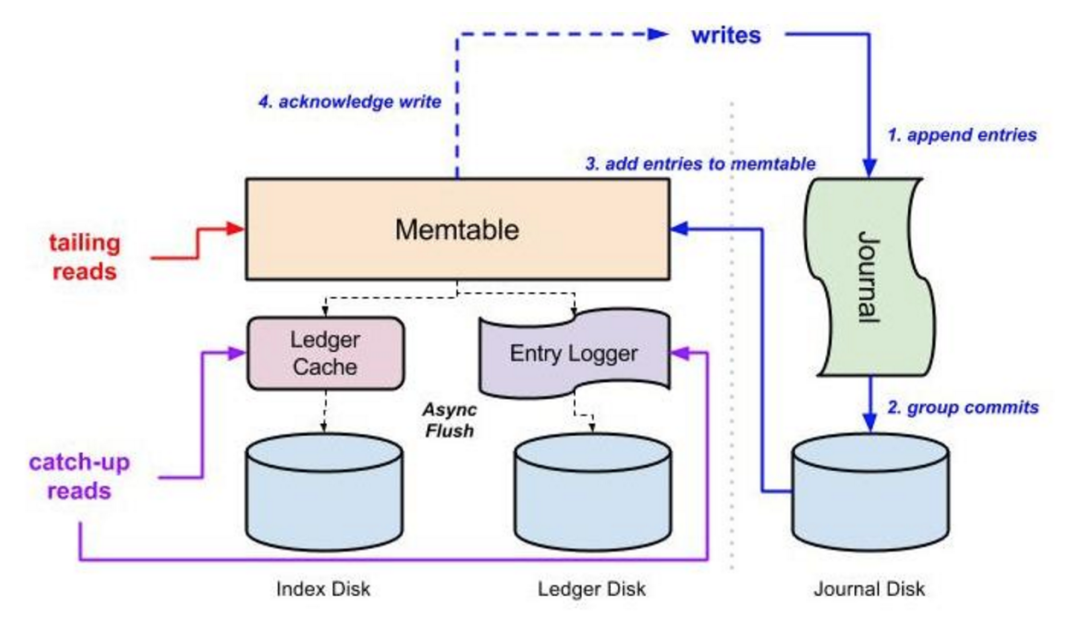
图三:BookKeeper 的 I/O 隔离
小结
Kafka 和 DistributedLog 都是设计来处理日志流相关问题的。它们有相似性,但在存储和复制机制上有着不同的设计理念,因此有了不同的实现方式。希望这篇文章能从技术角度解释清楚它们的区别,回答一些问题。