
斯坦福最新LLM排行榜发布!自家Alpaca垫底,华人团队WizardLM开源第一,GPT-4、Claude稳居前二
新智元
共 1940字,需浏览 4分钟
·
2023-06-19 18:33

新智元报道
新智元报道
【新智元导读】最近,来自斯坦福的研究人员提出一个基于大语言模型的全新自动评估系统——AlpacaEval。不仅速度快、成本低,而且还经过了2万个人类标注的验证。

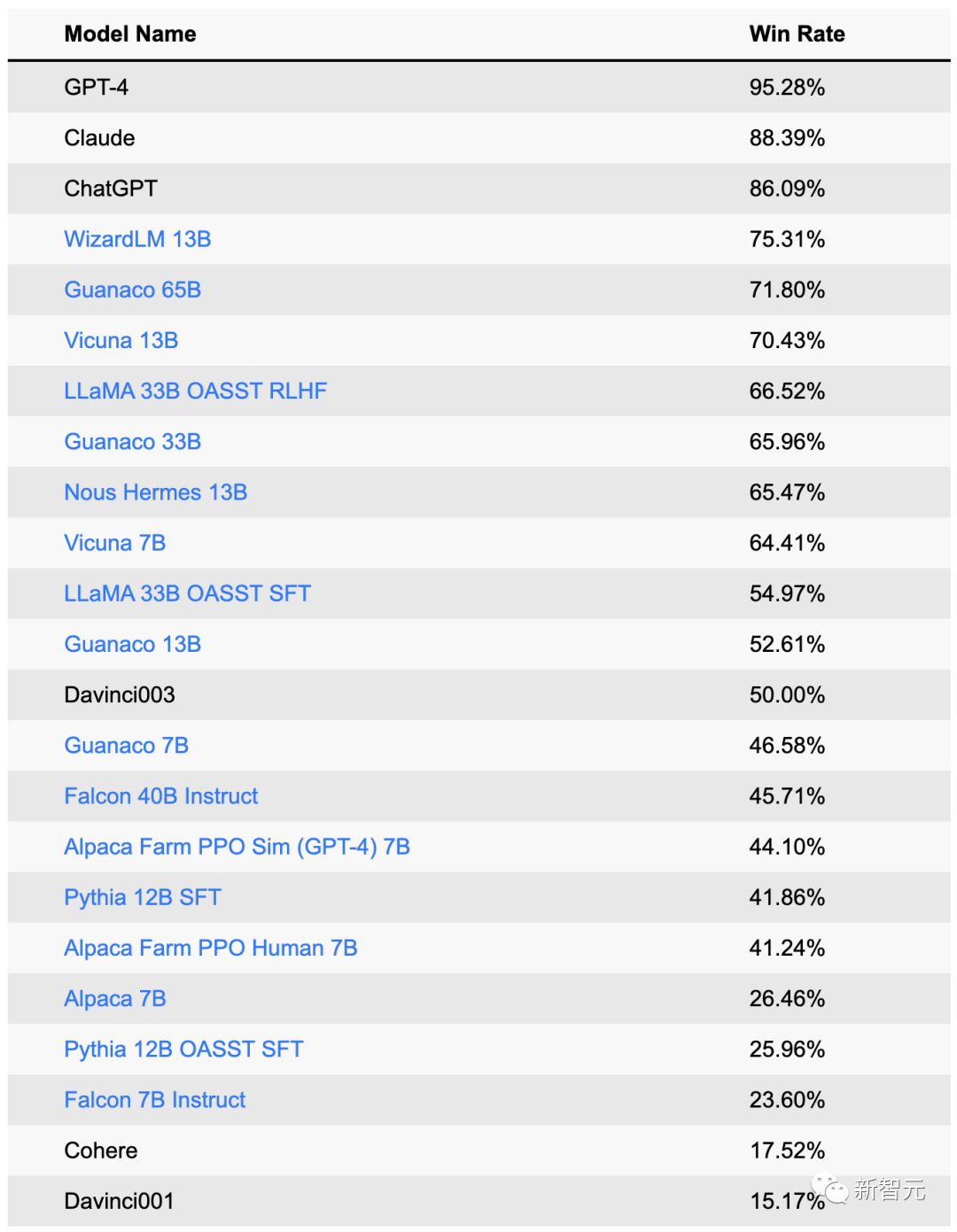

AlpacaEval:易使用、速度快、成本低、经过人类标注验证
AlpacaEval把AlpacaFarm和Aviary进行了结合。
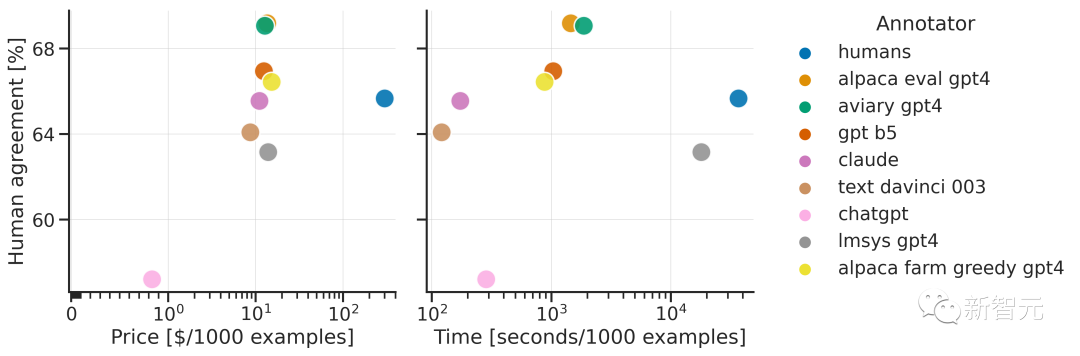
与人类多数票的一致性,高于单个人类标注者 胜率与人类标注高度相关(0.94) 相比于lmsys评测器,有显著提升(从63%提高到69%)
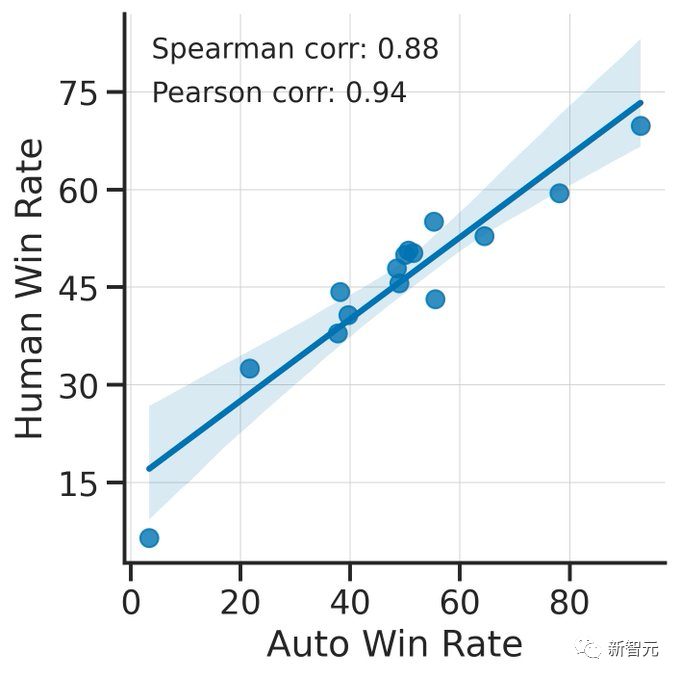
胜率

标准误差
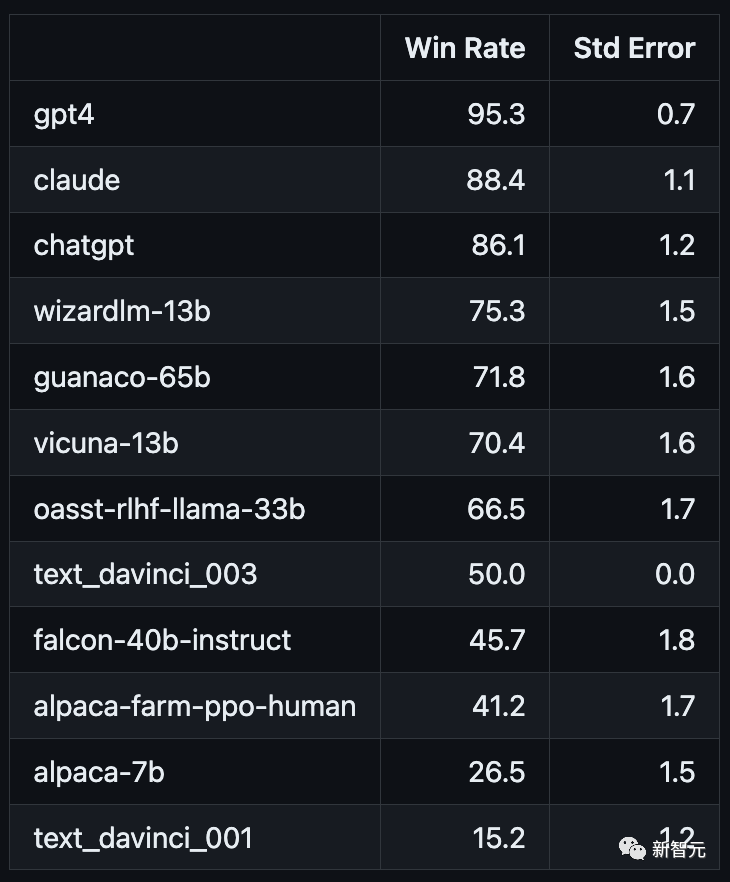
不同评测器的对比
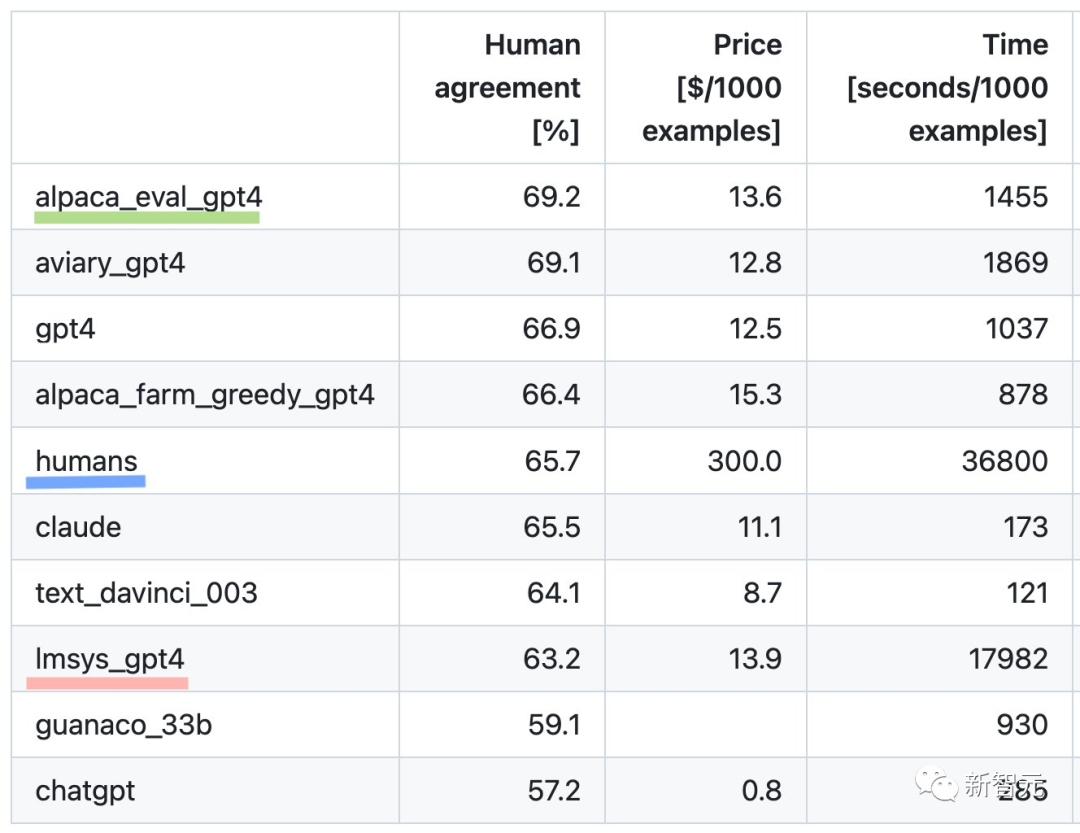
人类一致性:标注者与交叉标注集中人类多数票之间的一致性
价格:每1000个标注的平均价格
时间:计算1000个标注所需的平均时间
一个易于定制的流程 模型和自动评测器的排行榜 分析自动评测器的工具包 18K人类标注 2K人类交叉标注
局限性
指令比较简单 评分时可能更偏向于风格而非事实 没有衡量模型可能造成的危害


评论