
如何从0到1搭建大数据平台
大数据时代这个词被提出已有10年了吧,越来越多的企业已经完成了大数据平台的搭建。随着移动互联网和物联网的爆发,大数据价值在越来越多的场景中被挖掘,随着大家都在使用欧冠大数据,大数据平台的搭建门槛也越来越低。借助开源的力量,任何有基础研发能力的组织完全可以搭建自己的大数据平台。但是对于没有了解过大数据平台、数据仓库、数据挖掘概念的同学可能还是无法顺利完成搭建,因为你去百度查的时候会发现太多的东西,不知道如何去选择。今天给大家分享下大数据平台是怎么玩的。
架构总览
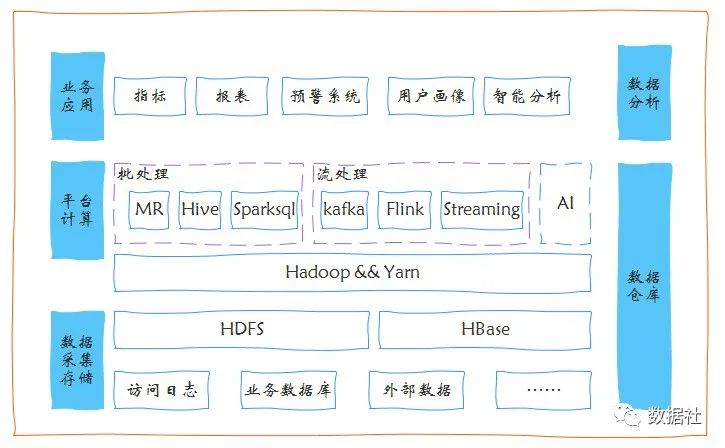
通常大数据平台的架构如上,从外部采集数据到数据处理,数据显现,应用等模块。
数据采集
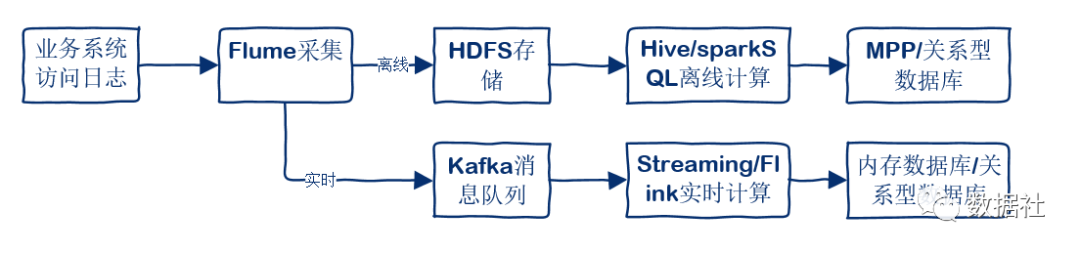
用户访问我们的产品会产生大量的行为日志,因此我们需要特定的日志采集系统来采集并输送这些日志。Flume是目前常用的开源选择,Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。

对于非实时使用的数据,可以通过Flume直接落文件到集群的HDFS上。而对于要实时使用的数据来说,则可以采用Flume+Kafka,数据直接进入消息队列,经过Kafka将数据传递给实时计算引擎进行处理。
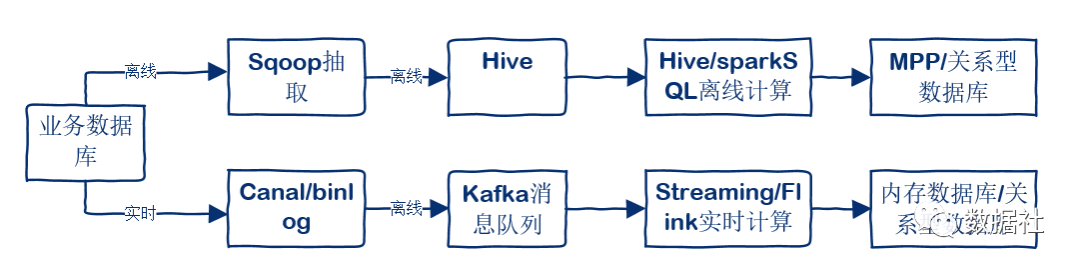
业务数据库的数据量相比访问日志来说小很多。对于非实时的数据,一般定时导入到HDFS/Hive中。一个常用的工具是Sqoop,Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 :MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。而对于实时的数据库同步,可以采用Canal作为中间件,处理数据库日志(如binlog),将其计算后实时同步到大数据平台的数据存储中。
数据存储
无论上层采用何种的大规模数据计算引擎,底层的数据存储系统基本还是以HDFS为主。HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础。具备高容错性、高可靠、高吞吐等特点。
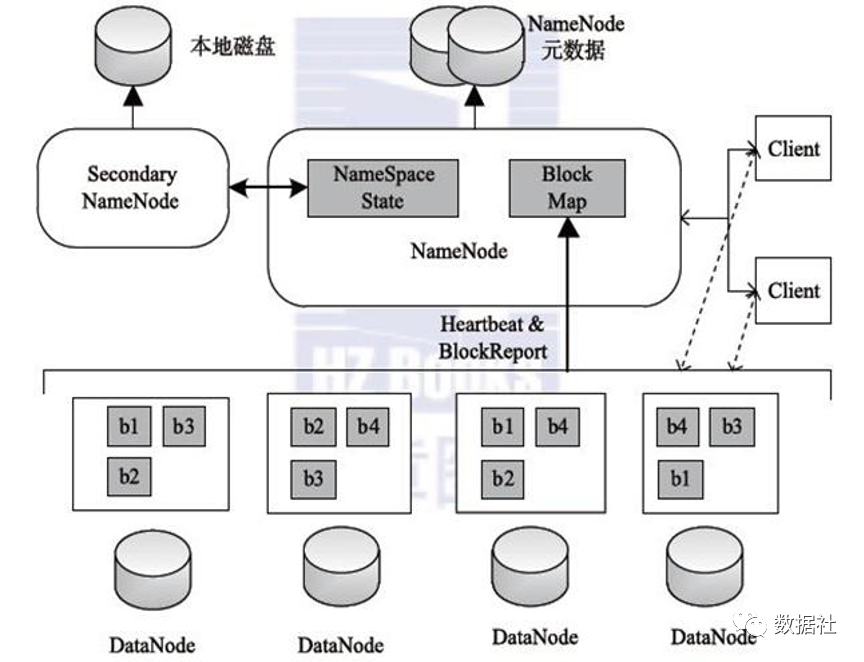
HDFS存储的是一个个的文本,而我们在做分析统计时,结构化会方便需要。因此,在HDFS的基础上,会使用Hive来将数据文件映射为结构化的表结构,以便后续对数据进行类SQL的查询和管理。
数据处理
数据处理就是我们常说的ETL。在这部分,我们需要三样东西:计算引擎、调度系统、元数据管理。
对于大规模的非实时数据计算来讲,目前一样采用Hive和spark引擎。Hive是基于MapReduce的架构,稳定可靠,但是计算速度较慢;Spark则是基于内存型的计算,一般认为比MapReduce的速度快很多,但是其对内存性能的要求较高,且存在内存溢出的风险。Spark同时兼容hive数据源。
从稳定的角度考虑,一般建议以Hive作为日常ETL的主要计算引擎,特别是对于一些实时要求不高的数据。Spark等其他引擎根据场景搭配使用。
实时计算引擎方面,目前大体经过了三代,依次是:storm、spark streaming、Flink。Flink已被阿里收购,大厂一直在推,社区活跃度很好,国内也有很多资源。
调度系统上,建议采用轻量级的Azkaban,Azkaban是由Linkedin开源的一个批量工作流任务调度器。https://azkaban.github.io/
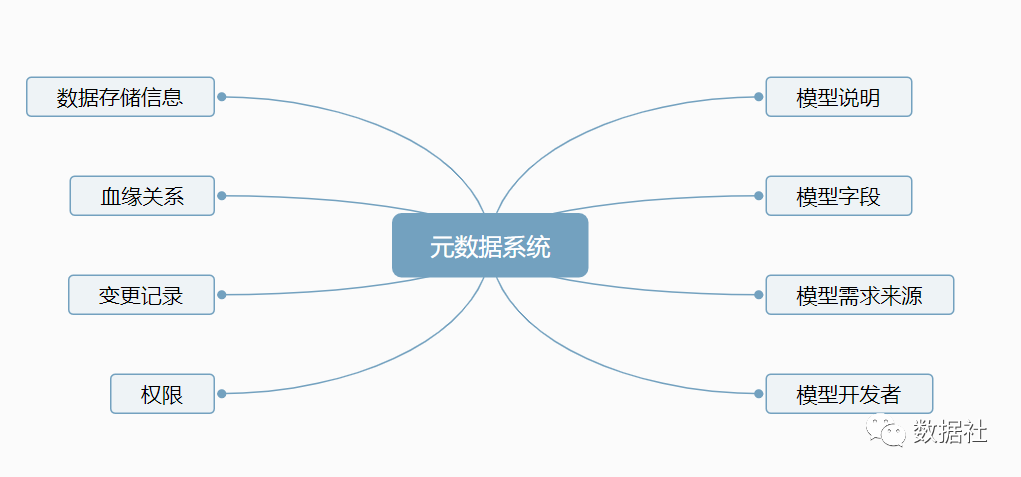
一般需要自己开发一套元数据管理系统,用来规划数据仓库和ETL流程中的元数据。元数据分为业务元数据和技术元数据。
业务元数据,主要用于支撑数据服务平台Web UI上面的各种业务条件选项,比如,常用的有如下一些:移动设备机型、品牌、运营商、网络、价格范围、设备物理特性、应用名称等。这些元数据,有些来自于基础数据部门提供的标准库,比如品牌、价格范围等,可以从对应的数据表中同步或直接读取;而有些具有时间含义的元数据,需要每天通过ETL处理生成,比如应用信息。为支撑应用计算使用,被存储在MySQL数据库中;而对于填充页面上对应的条件选择的数据,则使用Redis存储,每天/月会根据MySQL中的数据进行加工处理,生成易于快速查询的键值对类数据,存储到Redis中。
数据流转
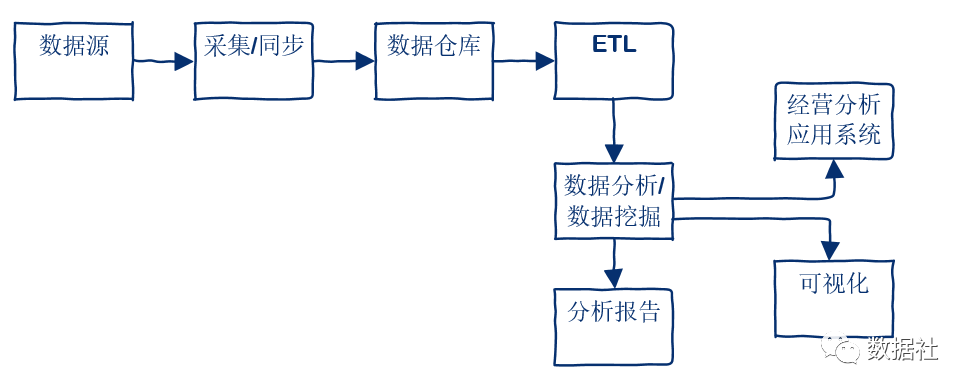
通过上面一张图了解数据采集,数据处理,到数据展现的数据流转。通常我们在实际工作中,从数据源到分析报告或系统应用的过程中,主要包括数据采集同步、数据仓库存储、ETL、统计分析、写入上层应用数据库进行指标展示。这是最基础的一条线,现在还有基于数据仓库进行的数据分析挖掘工作,会基于机器学习和深度学习对已有模型数据进一步挖掘分析,形成更深层的数据应用产品。
数据应用
俗话说的好,“酒香也怕巷子深”。数据应用前面我们做了那么多工作为了什么,对于企业来说,我们做的每一件事情都需要体现出价值,而此时的数据应用就是大数据的价值体现。数据应用包括辅助经营分析的一些报表指标,商城上基于用户画像的个性化推送,还有各种数据分析报告等等。

好的数据应用一定要借助可视化显现,比如很多传统企业买的帆软。开源界推荐一款可视化工具Superset,可视化种类很多,支持数据源也不少,使用方便。最近数砖收购的redash,也为了自己能一统大数据处理平台。可以看出可视化对于企业数据价值体现是很重要的。
结尾
通过本文,可以对大数据平台处理做初步了解,知道包含哪些技术栈,数据怎么流转,想要真正从0到1搭建起自己的大数据平台,还是不够的。了解了流程,你还需要真正的上手搭建Hadoop集群,Spark集群,数据仓库建设,数据分析流程规范化等等都需要很多工作。
Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
长按扫码添加“Python小助手”
▼点击成为社区会员 喜欢就点个在看吧