机器学习 太 枯 燥 了 !!!
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
大数据文摘出品 来源:medium 编译:睡不着的iris

设计(占5-10%时间)
编程(占20-70%时间,取决于你的开发角色)
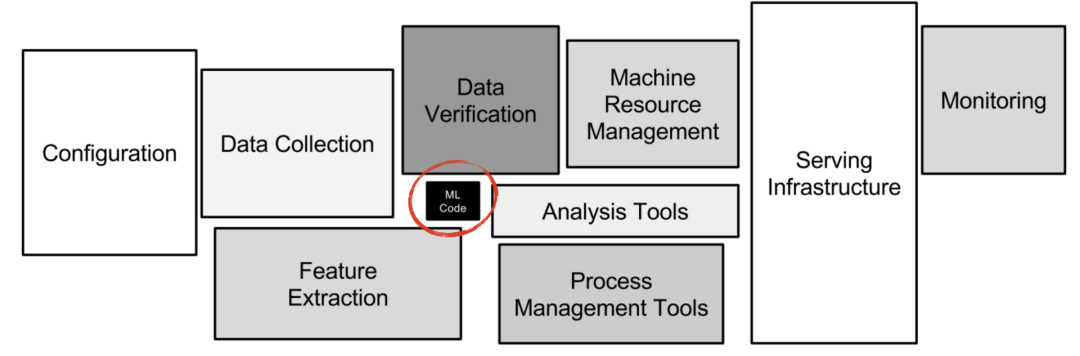
质量评估、调试和修复问题(起码占65%时间)
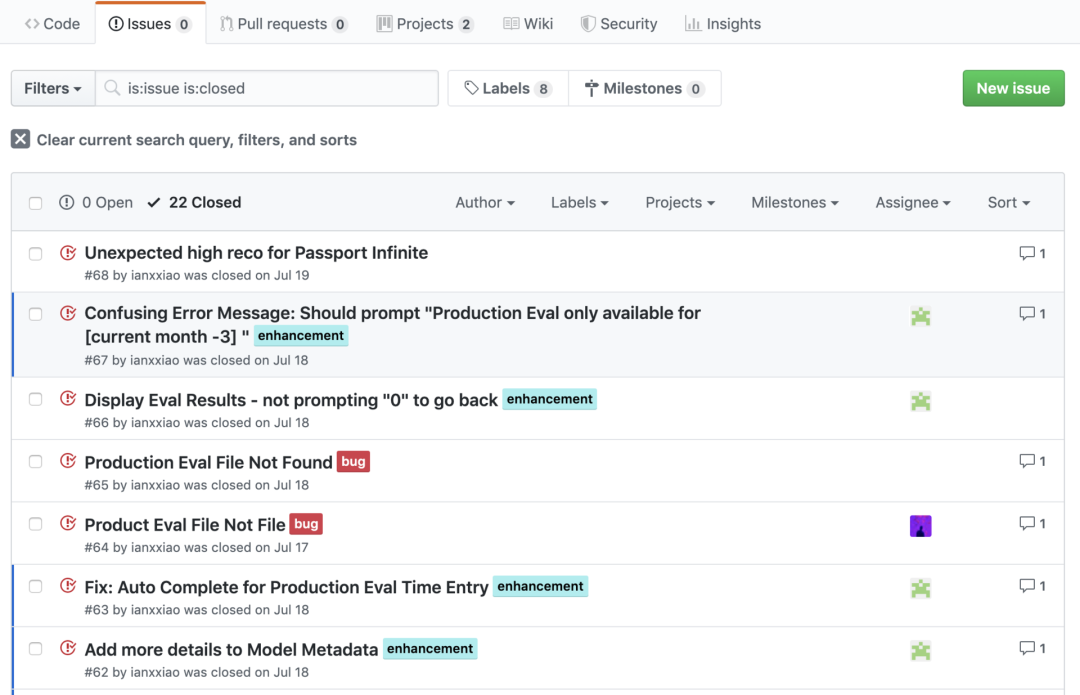
救火(占10-50%时间)
https://towardsdatascience.com/data-science-is-boring-1d43473e353e

评论
 下载APP
下载APP↑↑↑点击上方蓝字,回复资料,10个G的惊喜
https://towardsdatascience.com/data-science-is-boring-1d43473e353e