
更好的Python对象序列化方式

许多Python标准库都有一些未被赏识的精华。其中之一是允许简单优雅的基于参数类型的函数分发。这一特性对于任意对象的序列化而言是非常完美的——例如对于web API的JSON或结构化日志而言。

谁应该都见过这个:

虽然这不是什么大问题。json模块(API继承自simplejson)提供了两种方式来序列化对象:
1. 实现一个default()函数,它接收一个对象作为参数并且返回可以被JSONEncoder理解的东西;
2. 你自己实现或子类化一个JSONEncoder,并且把它作为cls传递给dump方法。你可以自己实现它或者简单地重写JSONEncoder.default()方法。
由于一些第三方的实现希望能够被大多数程序兼容,所以他们都不同程度的模仿了json模块的API1。
扩展性
所有上述方法的共性是它们不具有扩展性:不提供对新类型的支持。你的default()函数需要知道所有你想要序列化的自定义类型。这意味着你或者像这样写你的函数:
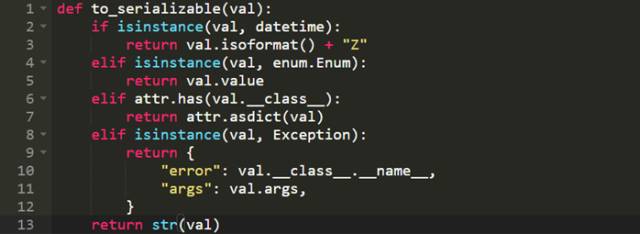
这看起来非常痛苦,因为你需要在一个地方为所有不同类型对象增加序列化结果2。
或者另一种方法,你可以自己尝试提出一种一般性的解决方案,就像Pyramid的JSON渲染器在JSON.add_adapter中做的一样,它使用了被广泛低估的zope.interface的适配器注册表3。
另一方面,Django自己实现了一个DjangoJSONEncoder,它是json.JSONEncoder的子类,它知道如何去编码日期,时间,UUID和premise等。但是除此之外,你又需要依靠自己了。如果你想深入研究Django和web API,那么你可能已经准备好使用Django的REST框架了。它们实现了一整套序列化系统,它比仅仅让数据进行json.dump()做了更多的工作。
最后,为了完整性,我感觉我不得不提到我自己在我第一天开始就极其讨厌的structlog中的解决方案:为你的类增加一个__structlog__方法,它会像__str__一样返回一个序列化后的表示方法。请不要重复我的错误。标签:software clown。
JSON已经很流行了,然而很奇怪的是我们对于序列化的解决方案却仍旧不够完善。我个人想要的是能够注册一个中心化的序列化工具,但是却以一个去中心化的方式来使用,这样可以不需要对我的类(或者更糟的,第三方类)进行任何修改。
进入PEP443
Python3.4以PEP 443的形式给出了对这个问题的一个好的解决方案:functools.singledispatch(老式Python版本也可以在PyPI上找到)。
简单说,你可以定义一个默认的函数然后根据第一个参数的类型注册一个该函数的额外版本:
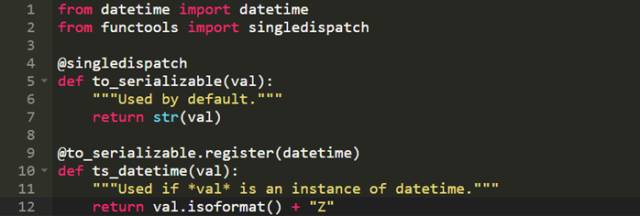
现在你也可以对datetime实例调用to_serializable()方法,singledispatch会选择正确的函数

这一方法让你能够把你的序列化器放在任何你想放的位置:放在类里,在一个独立的模块里,或者放在JSON相关的代码里。你自己选!但是你的类要保持干净,并且你不需要巨大的繁琐的if-elif-else分支。
更深入一点
显然,@singledispatch的使用比JSON更加深入。一般而言,为不同类型的对象绑定不同的行为以及独立的序列化方式是普遍适用的4。我的一些校对员提到了他们尝试了采用字典类近似替代可调用对象以及其他一些类似的“残暴的”做法。
换句话说,@singledispatch就是一个长久以来就存在的但是却被你忽略的函数。
P.S. 当然,PyPI中也有一个*multiple*dispatch。
脚注
1. 然而,对于非常出名的一个:UltraJSON一点都不支持自定义对象的序列化,此外,python-rapidjson仅仅支持default()函数。
2. 利用attrs是可以很好管理的!也许你应当使用attrs!
3. 不幸的是Pyramid使用的API自从zope.component移植过来之后还没有形成文档。
4. 我听说将singlepatch加进标准库的最原始动力来自于对pprint的一个更优雅的实现(虽然从来没有实现过)
原文链接:https://hynek.me/articles/serialization/
文章转载:Python编程学习圈
(版权归原作者所有,侵删)
![]()

点击下方“阅读原文”查看更多