
由 Babel 理解前端编译原理
大厂技术 坚持周更 精选好文
背景
我们知道编程语言主要分为「编译型语言」和「解释型语言」,编译型语言是在代码运行前编译器将编程语言转换成机器语言,运行时不需要重新翻译,直接使用编译的结果就行了。而解释型语言也是需要将编程语言转换成机器语言,但是是在运行时转换的。
通常我们都将 JavaScript 归类为「解释型语言」,以至于很多人都误以为前端代码是不需要编译的,但其实 JavaScript 引擎进行编译的步骤和传统的编译语言非常相似,只不过与传统的编译语言不同,它不是提前编译的。并且随着现代浏览器和前端领域的蓬勃发展,编译器在前端领域的应用越来越广泛,就日常工作而言,包括但不限于以下几个方面:
v8 引擎、typescript 编译器(tsc)
webpack loader 编译器(acorn[19]),babel、SWC 等编译工具。
angular、Vue 等框架的模板编译器、jsx
作为前端开发,我们没必要对这些编译器或者底层的编译原理了如指掌,但是如果能对编译原理有一些基本的认识,也能够对今后的日常开发很有帮助。本文就带领大家学习下编译原理的一些基本概念,并以 Babel 为例讲解下前端编译的基本流程。
概述
我们先来回顾下编译原理的基本知识,从宏观上来说,编译本质上是一种转换技术,从一门编程语言转换成另一门编程语言,或者从高级语言转换成低级语言,或者从高级语言到高级语言,所谓的高级语言和低级语言主要是指下面的区分:
高级语言:有很多用于描述逻辑的语言特性,比如分支、循环、函数、面向对象等,接近人的思维,可以让开发者快速的通过它来表达各种逻辑。比如 c++、javascript。
低级语言:与硬件和执行细节有关,会操作寄存器、内存,具体做内存与寄存器之间的复制,需要开发者理解熟悉计算机的工作原理,熟悉具体的执行细节。比如汇编语言、机器语言。
无论是怎样的编译过程,基本都会是下面的一个过程:
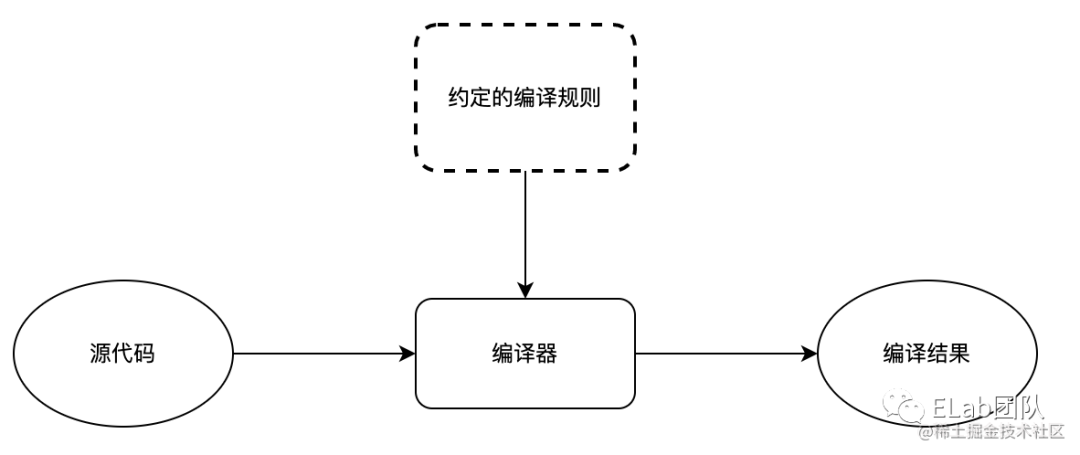 上面的约定的编译规则,就是指各种编程语言的语法规则,不同的编译器会产出不同的“编译结果”,例如
上面的约定的编译规则,就是指各种编程语言的语法规则,不同的编译器会产出不同的“编译结果”,例如 C/C++ 语言经过编译得到二进制的机器码,然后交给操作系统,例如当我们运行 tsc 命令就会将 TS 代码编译为 js 代码,再比如执行 babel 命令会将 es6+ 的代码编译为指定目标(es5)的 js 代码。
一般来说,整个编译过程主要分为两个阶段:编译 前端和编译后端,大致分为下面的几个过程:
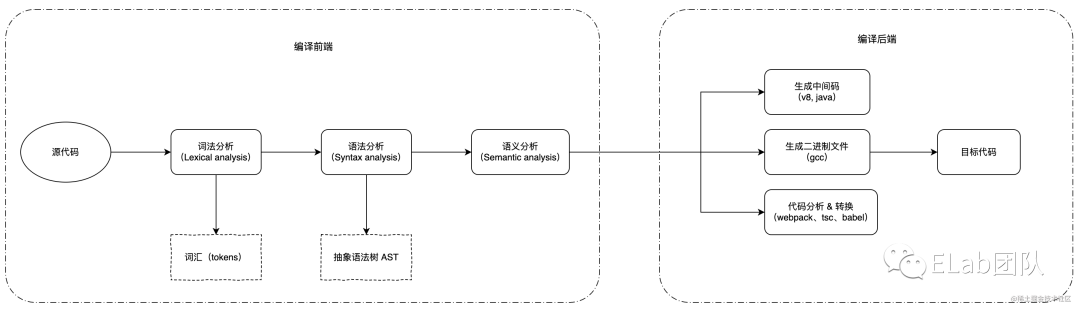 从上图可以看到,编译前端主要就是帮助计算机阅读源代码并理解源代码的结构、含义、作用等,将源代码由一串无意义的字符流解析为一个个的有特定含义的构件。通常情况下,编译前端会产生一种用于给编译后端消费的中间产物,比如我们常见的抽象语法树 AST,而编译后端则是在前端解析的结果和基础上,进一步优化和转换并生成最终的目标代码。
从上图可以看到,编译前端主要就是帮助计算机阅读源代码并理解源代码的结构、含义、作用等,将源代码由一串无意义的字符流解析为一个个的有特定含义的构件。通常情况下,编译前端会产生一种用于给编译后端消费的中间产物,比如我们常见的抽象语法树 AST,而编译后端则是在前端解析的结果和基础上,进一步优化和转换并生成最终的目标代码。
上下文无关文法
前面提到编译器会根据「约定的编译规则」进行编译,这里「约定的编译规则」就是指「上下文无关文法(CFG)[20]」。CFG 用于在理论上的形式化定义一门语言的语法,或者说,用于系统地描述程序设计语言的构造(比如表达式和语句)。
实际上,几乎所有程序设计语言都是通过上下文无关文法来定义的,与正则表达式比较像,但是比正则表达式功能更强大,它能表达非常复杂的文法,比如 C 语言语法用正则表达式来表示不可能做到,但是可以用 CFG 的一组规则来表达。
要理解上下文无关文法,需要先理解下面几个概念:
终结符:可以理解为基础符号,词法符号,是不可替代的,是固定存在的,不能通过文法规则生成的。
非终结符:句法变量,是可以替代的
产生式规则:语法是由终结符集、非终结符集和产生式规则共同组成。产生式规则定义了符号之间如何转换替代。规则的左侧是规则头,即非终结符,是可以被替代的符号;右侧是产生式,是具体的内容。
例如下面 a, b, c, d 为终结符(用小写表示),(S, A) 为非终结符(用大写表示)。S -> cAd, A -> a | ab 表示产生式规则。S->cAd,然后可以产生"cad",“cabd” 等符合文法的内容
S -> cAd
A -> a | ab
上下文无关文法比较抽象,不是这里学习的重点,感兴趣的话可以专门深入了解下,这里知乎上也有篇回答可以参考下 应该如何理解「上下文无关文法」?[21]
下面我们来简单模拟下如何用 CFG 来定义一门语言的语法, 我们假设一个极其简单的语言,这个语言只能像 js 那样声明整数型常量,以及声明不接受任何参数且只能直接返回常量加法的箭头函数。
const a = 10
const b = 20
const c = () => a + b
这个语言的文法表达如下:
program :: statement+
statement :: declare | func
declare :: CONST VARIABLE ASSIGN INTEGER
func :: CONST LPAREN RPAREN ARROW expression
expression :: VARIABLE + VARIABLE
CONST :: "const"
ASSIGN :: "="
LPAREN :: "("
RPAREN :: ")"
ARROW :: "=>"
INTEGER :: \d+
VARIABLE :: \w[\w\d$_]*
可以看出,整个文法的表达,涵盖了很多正则表达式的概念。该表达是一种自顶向下的规范:
首先入口约束了程序(program)是由一条(及以上)的表达式(statement)构成,
而表达式又可以由声明语句(declare)或函数语句(func)构成。
声明语句依次由 const、关键字、符号 =、整数 从左到右排列构成。
整数的定义则直接使用正则表达式来约束。函数语句也是类似。
大家可以观察到,上述的文法分成了上下两个大的部分。上半部分定义了语句以及由语句递归构造的表达,通常称为「语法规则」(grammar rules);下半部分定义了可通过排列构成语句的基本词汇,通常称为「词法规则」(lexer rules)。

在实践中,词法规则往往没有单独罗列,而是直接写入到语法规则中。比如上述文法可简化为:
program :: statement+
statement :: declare | func
declare :: "const" variable "=" integer
func :: "const" variable "=" "(" ")" "=>" expression
expression :: variable + variable
variable :: \w[\w\d$_]*
integer :: \d+
上面的文法表达形式叫做 BNF[22],它是用来描述上下文无关文法的一种描述语言,形式为<符号> ::= <使用符号的表达式>,这里的 <符号> 是非终结符,而表达式由一个符号序列,或用指示选择的竖杠 '|' 分隔的多个符号序列构成,每个符号序列整体都是左端的符号的一种可能的替代。从未在左端出现的符号就是终结符。
有了 BNF,我们就可以实现语言文法的具体化、公式化,甚至可以自己实现一个语言来解决特定领域的问题。再来看个例子,用 BNF 来描述四则运算:
result ::= number ("+"|"-") exp | number // 非终结符
exp ::= number("*"|"/") exp | number // 非终结符
number ::= [0-9]+ // 终结符
另外,我们也可以窥探下 ECMA 和 JSON 的 BNF:
JSON Schema 的 BNF:Syntax - JSON Schema[23]
ECMA 的 BNF:function&class bnf[24]
编译器工作流程
接下来我们就相对深入的来看一下编译的各个阶段。
词法分析
就像我们学习一门语言的第一步是学习单词一样,编译器识别源代码的第一步就是要要进行分词,识别出每一个单词或符号。这个阶段,词法分析器会将源代码拆分成一组 token 串:
首先,通过对源代码的字符串从左到右进行扫描,以空白字符(空格、换行、制表符等)为分隔符,拆分为一个个无类型的 token 。
其次,再根据词法规则,利用「有限状态机[25]」对第一步拆分的 Token 进行字符串模式匹配,以识别每一个 Token 的类型(v8 token.h[26])。
一般而言,token 是一个有类型和值的数据结构,而 token 流简单理解可以是 token 数组。以下面一行代码为例:
const name = 'xujianglong';
// 根据 js 的语法规则, 大致会生成如下的 token 流
[
{ type: "CONST", value: "const" },
{ type: "IDENTIFIER", value: "name" },
{ type: "ASSIGN", value: "=" },
{ type: "STRING", value: "xujianglong" },
{ type: "SEMICOLON", value: ";" },
]
那么有限状态机是个什么概念呢?它是怎么把字符串代码转化为 token 的呢?
首先我们想一下,词法描述的是最小的单词格式,比如上面例子的那一行代码为例,利用空白字符拆分成这几个 token:['const','name','=','xujianglong',';'],但是怎么去识别每种 token 的类型呢,最简单粗暴的方式我们可以写个 if else语句或者写个正则,但是这样貌似不太优雅且不容易维护,而使用状态机是许多编程语言都使用的方式。
有限状态机(英语:finite-state machine,缩写:FSM)又称有限状态自动机(英语:finite-state automation,缩写:FSA),简称状态机,是表示有限个状态以及在这些状态之间的转移和动作等行为的数学计算模型。
如图所示,用户从其他状态机进入 S1 状态机,如果用户输入 1,则继续进入 S1 状态机,如果用户输入了 0,则进入下一个状态机 S2。在 S2 状态机中,如果用户继续输入 1,则继续进入 S2 状态机,如果用户输入了 0,则回到 S1 状态机。这是一个循环的过程。
听起来有点抽象,对比到代码分词中来说,我们可以把每个单词的处理过程当成一种状态,将整体的输入(源代码)按照每个字符依次去读取,根据每次读取到的字符来更改当前的状态,每个 token 识别完了就可以抛出来。我们举个简单的四则运算的例子:10 + 20 - 30
 首先我们定义了三种状态机,分别是
首先我们定义了三种状态机,分别是 NUMBER 代表数值,ADD 代表加号,SUB 代表减号:
当分析到 "1" 时,因为本次输入我们需要改变状态机内部状态为 NUMBER,继续迭代下一个字符 “0”,此时因为 "1" 和 "0" 是一个整体可以不被分开的。
当分析到 "+" 时,状态机中输入为 “+”, 显然 “+” 是一个运算符号,它并不能和上一次的 “10” 拼接在一起。所以此时状态改变,我们将上一次的 currentToken 也就是 "10" 推入 tokens 中,同时改变状态机状态为 ADD。
依次类推,最终会输出如下 tokens 数组:
[
{ type: "NUMBER", value: "10" },
{ type: "ADD", value: "+" },
{ type: "NUMBER", value: "20" },
{ type: "SUB", value: "-" },
{ type: "NUMBER", value: "30" },
]
语法分析
在这个阶段,语法分析器(parser)会将词法分析中得到的 token 数组转化为 抽象语法树 AST 。比如前面定义变量的那行代码可以在这个在线工具 AST explorer[27] 中查看生成的 AST:
{
"type": "Program",
"start": 0,
"end": 28,
"body": [
{
"type": "VariableDeclaration",
"start": 1,
"end": 28,
"declarations": [
{
"type": "VariableDeclarator",
"start": 7,
"end": 27,
"id": {
"type": "Identifier",
"start": 7,
"end": 11,
"name": "name"
},
"init": {
"type": "Literal",
"start": 14,
"end": 27,
"value": "xujianglong",
"raw": "'xujianglong'"
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
对于 JavaScript 语言来说,AST 也有一套约定的规范:GitHub - estree/estree: The ESTree Spec[28],社区称之为 estree,借助这个规范,整个前端社区的一些工具便可以产出一套统一的数据格式而无需关心下游,下游的消费类工具统一使用这个统一的格式进行处理而无需关心上游,这样就做到了上下游的解耦。以 webpack 为例,其底层是 acorn[29] 工具,acorn 会把 js 源码转化为上述的标准 estree,而 webpack 作为下游便可以消费该 estree,比如遍历,提取和分析 require/import 依赖,转换代码并输出。
生成 AST 的过程需要遵循语法规则(用上下文无关文法表示),在上面代码中,我们用到了「VariableDeclaration」,其语法规则可以表示为:
VariableDeclaration :: Kind Identifier Init?;
Kind :: Const | Let | Var;
Init :: '=' Expression | Identifier | Literal;
Expression :: BinaryExpression | ConditionalExpression | ...;
Literal :: StringLiteral | ...;
有了语法规则之后,我们就需要思考编译器是如何将 token 流,在语法规则的约束下,转换成 AST 的呢?生成 AST 也主要是两大方向:
一是将文法规则的约束硬编码到编译器的代码逻辑中,这种是特定语言的编译器使用的常见方案,这种方案往往是人工编写 parse 代码,对输入源码的各种错误和异常可以更细致地报告和处理。比如前面提到的 arorn,以及 tsc,babel,以及熟悉的 vue,angular 的模板编译器等,都主要是这种方法。
二是使用自动生成工具将文法规则直接转换成语法 parse 代码。这种更常用于非特定的编程语言,比如一些业务中自定义的简单但易变的语法,或仅仅只是字符串文本的复杂处理规则。
我们这里以第一种方式最基础的 「递归下降算法」(递归下降的编译技术,是业界最常使用的手写编译器实现编译前端的技术之一,感兴趣可以专门去深入研究下)为例,简单描述示例代码生成 AST 的过程:
尝试匹配 VariableDeclaration
匹配到 Const
匹配到 Identifier
尝试匹配 Init,递归下降
匹配到 '='
尝试匹配 Expression,递归下降
匹配失败,回溯
匹配到 Literal,回溯
VariableDeclaration 匹配成功,构造相应类型节点插入 AST
语义分析
并不是所有的编译器都有语义分析,比如 Babel 就没有。不过对于其它大部分编程语言(包括 TypeScript)的编译器来说,是有语义分析这一步骤的,特别是静态类型语言,类型检查就属于语义分析的其中一个步骤
语义分析阶段,编译器开始对 AST 进行一次或多次的遍历,检查程序的语义规则。主要包括声明检查和类型检查,如上一个赋值语句中,就需要检查:
语句中的变量 name 是否被声明过
const 类型变量是否被改变
加号运算的两个操作数的类型是否匹配
函数的参数数量和类型是否与其声明的参数数量及类型匹配
语义检查的步骤和人对源代码的阅读和理解的步骤差不多,一般都是在遍历 AST 的过程中,遇到变量声明和函数声明时,则将变量名--类型、函数名--返回类型--参数数量及类型等信息保存到符号表里,当遇到使用变量和函数的地方,则根据名称在符号表中查找和检查,查找该名称是否被声明过,该名称的类型是否被正确的使用等等。
语义检查时,也会对语法树进行一些优化,比如将只含常量的表达式先计算出来,如:
a = 1 + 2 * 9;
会被优化成:
a = 19;
语义分析完成后,源代码的结构解析就已经完成了,所有编译期错误都已被排除,所有使用到的变量名和函数名都绑定到其声明位置(地址)了,至此编译器可以说是真正理解了源代码,可以开始进行代码生成和代码优化了。

中间代码生成与优化
一般的编译器并不直接生成目标代码,而是先生成某种中间代码,然后再生成目标代码。之所以先生成中间代码,主要有以下几个原因:
为了降低编译器开发的难度,将高级语言翻译成中间代码、将此中间代码再翻译成目标代码的难度都比直接将高级语言翻译成目标代码的难度要低。
为了增加编译器的模块化、可移植性和可扩展性,一般来说,中间代码既独立于任何高级语言,也独立于任何目标机器架构,这就为开发出适应性广泛的编译器提供了媒介
为了代码优化,一般来说,计算机直接生成的代码比人手写的汇编要庞大、重复很多,计算机科学家们对一些具有固定格式的中间代码的进行大量的研究工作,提出了很多广泛应用的、效率非常高的优化算法,可以对中间代码进行优化,比直接对目标代码进行优化的效果要好很多。
JavaScript 的编译器 v8 引擎早期是没有中间代码生成的,直接从 AST 生成本地可执行的代码,但由于缺少了转换为字节码这一中间过程,也就减少了优化代码的机会。为了提高性能, v8 开始采用了引入字节码的架构,先把 AST 编译为字节码,再通过 JIT 工具转换成本地代码。
v8 引擎的编译过程这里不做过多介绍,后续可作为单独的分享。
V8 引擎详解(三)——从字节码看 V8 的演变[30]
理解 V8 的字节码「译」[31]
生成目标代码
有了中间代码后,目标代码的生成是相对容易的,因为中间代码在设计的时候就考虑到要能轻松生成目标代码。不同的高级语言的编译器生成的目标代码不一样,如:
C、C++、Go,目标代码都是汇编语言(可能目标代码不一样),在经过汇编器最终得到机器码;
Java 经过 javac 编译后,生成字节码,只经过了编译的词法分析、语法分析、语义分析和中间代码生成,运行时再由解释器逐条将字节码解释为机器码来执行;
JavaScript,在运行时经过整个编译流程,不过也是先生成字节码,然后解析器解析字节码执行;
至于 webpack、babel 这些前端工具则是最终编译成相应的 js 代码。
Babel 的编译流程
前面我们提到,一般编译器是指高级语言到低级语言的转换工具,特殊地像前端的一些工具类型的转换,如 ts 转 js,js 转 js 等这些都是高级语言到高级语言的转换工具,通常被叫做转换编译器,简称转译器 (Transpiler),所以 Babel 就是是一个 JavaScript 编译器。
Babel 主要用于将采用 ECMAScript 2015+ 语法编写的代码转换为向后兼容的 JavaScript 语法,并且还可以把目标环境不支持的 api 进行 polyfill。以便能够运行在当前和旧版本的浏览器或其他环境中。例如下面的例子:
// Babel 输入:ES2015 箭头函数
[1, 2, 3].map(n => n + 1);
// Babel 输出:ES5 语法实现的同等功能
[1, 2, 3].map(function(n) {
return n + 1;
});
Babel 的工作流程可分为如下几个步骤:
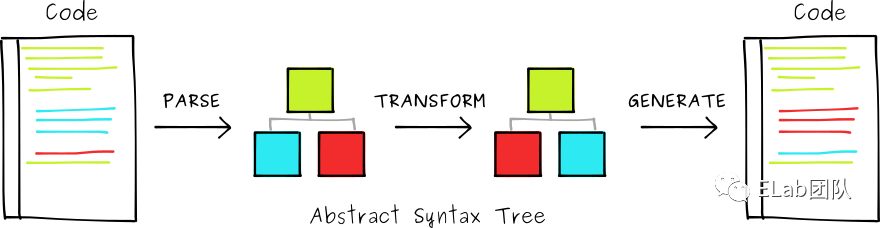
下面详细介绍下 babel 工作流程的各个阶段。
parse(解析)
parse 这个阶段将原始代码字符串转为 AST 树,parse 广义上来说包括了我们前面编译流程中讲到的 词法分析、语法分析这两个阶段。parse 过程中会有一些 babel 插件,让 babel 可以解析出更多的语法,比如 jsx。
parse(sourceCode) => AST
parse 阶段,主要通过 @babel/parser这个包进行转换,之前叫 babylon,是基于 acorn 实现的,扩展了很多语法,可以支持 esnext(现在支持到 es2020)、jsx、flow、typescript 等语法的解析,其中 jsx、flow、typescript 这些非标准的语法的解析需要指定语法插件。
我们可以手动调用下 parser 的方法进行转换,便会得到一份 AST:
const parser = require("@babel/parser");
const fs = require('fs');
const code = `function square(n) {
return n * n;};`
const result = parser.parse(code)
console.log(result);
最终输出的 AST 如下所示:
{
type: "FunctionDeclaration",
id: {
type: "Identifier",
name: "square"
},
params: [{
type: "Identifier",
name: "n"
}],
body: {
type: "BlockStatement",
body: [{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "*",
left: {
type: "Identifier",
name: "n"
},
right: {
type: "Identifier",
name: "n"
}
}
}]
}
}
可以看到 AST 的每一层都拥有相似的结构,这样的每一层结构也被叫做 节点(Node), 一个 AST 可以由单一的节点或是成百上千个节点构成,它们组合在一起可以描述用于静态分析的程序语法。每个节点都有个字符串的 type 类型,用来表示节点的类型,babel 中定义了包含所有 JavaScript 语法的类型,如:
声明语句:如 FunctionDeclaration、VaraibaleDeclaration、ClassDeclaration等声明;
标识符: Identifier,变量或函数参数。
字面量: StringLiteral、NumbericLiteral、BooleanLiteral等字面量类型;
语句: WhileStatement、ReturnStatement等语句;
表达式: FunctionExpression、BinaryExpression、AssignmentExpression等。
所有的这些节点通过嵌套形成了 AST 树,例如一个变量赋值语句形成的树形结构如下所示:
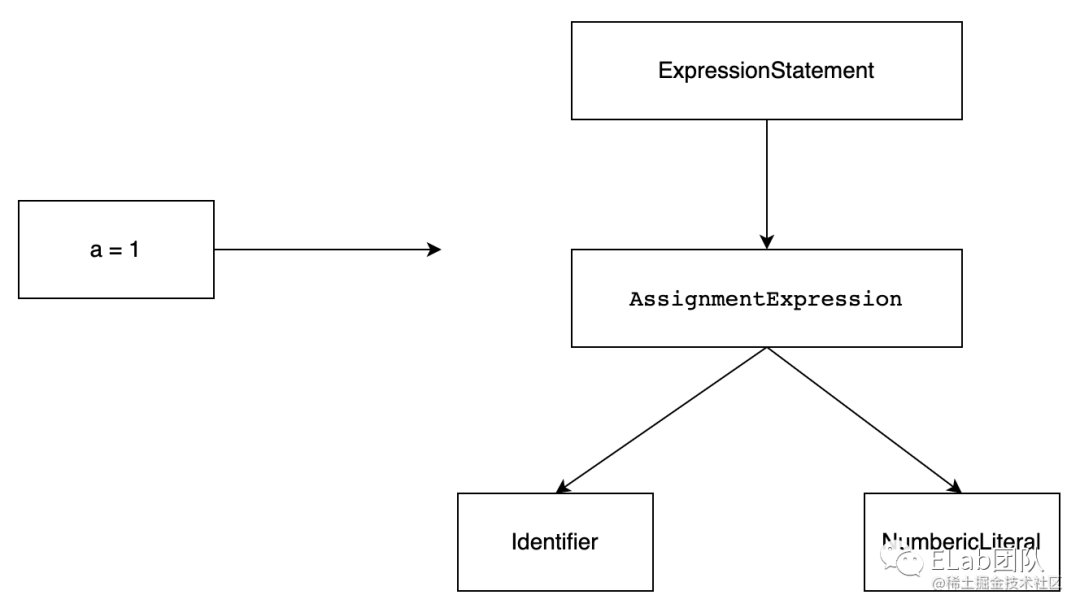
transform(转化)
transform 阶段主要是对上一步 parse 生成的 AST 进行深度优先遍历,从而对于匹配节点进行增删改查来修改树形结构。在 babel 中会用所配置的 plugin 或 presets 对 AST 进行修改后,得到新的 AST,我们的 babel 插件大部分用于这个阶段。
transform(AST, BabelPlugins) => newAST
babel 中通过 @babel/traverse 这个包来对 AST 进行遍历,找出需要修改的节点再进行转换,这个过程有点类似我们操作 DOM 树。当我们谈及“进入”一个节点,实际上是说我们在访问它们, 之所以使用这样的术语是因为有一个访问者模式(visitor)[32]的概念。访问者 visitor 是一个用于 AST 遍历的跨语言的模式。简单的说它就是一个对象,定义了用于在一个树状结构中获取具体节点的方法。
visitor 是一个由各种 type 或者是 enter 和 exit 组成的对象,完成某种类型节点的"进入"或"退出"两个步骤则为一次访问,在其中可以定义在遍历 AST 的过程中匹配到某种类型的节点后该如何操作,目前支持的写法如下:
traverse(ast, {
/* VisitNodeObject */
enter(path, state) {},
exit(path, state) {},
/* [Type in t.Node["type"]] */
Identifier(path, state) {}, // 进入 Identifier(标识符节点) 节点时调用
StringLiteral: { // 进入 StringLiteral(字符串节点) 节点时调用
enter(path, state) {}, // 进入该节点时的操作
exit(path, state) {}, // 离开该节点时的操作
},
'FunctionDeclaration|VariableDeclaration'(path, state) {}, // // 进入 FunctionDeclaration 和 VariableDeclaration 节点时调用
})
访问一个节点的过程如下:
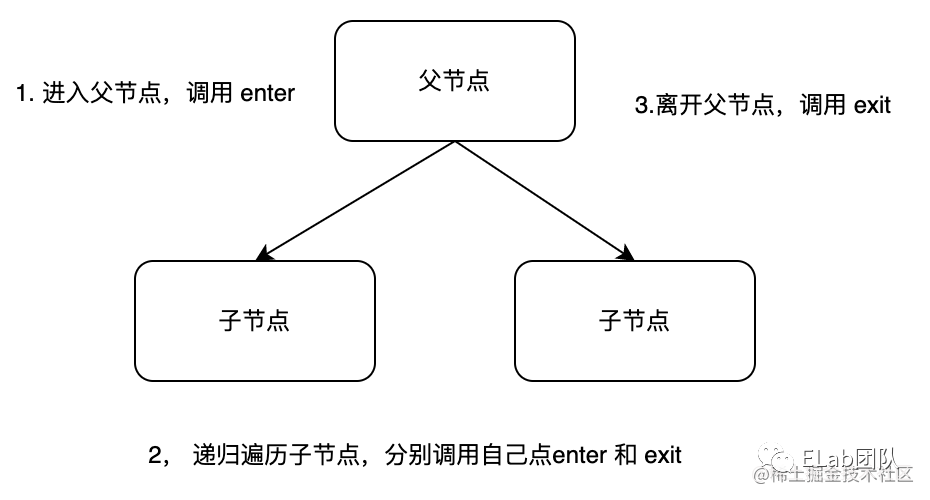 下面我们看一个简单的例子:
下面我们看一个简单的例子:
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const fs = require('fs');
const code = `function square(n) {
return n * n;
}`;
const ast = parser.parse(code);
const newAst = traverse(ast, {
enter(path) {
if (path.isIdentifier({
name: "n"
})) {
path.node.name = "x";
}
},
FunctionDeclaration: {
enter() {
console.log('enter function declaration')
},
exit() {
console.log('exit function declaration')
}
}
});
上面的例子中,通过识别标识符把 "n" 换成了 "x",其中的 path 是遍历过程中的路径,会保留上下文信息,有很多属性和方法,可以在访问到指定节点后,根据 path 进行自定义操作,比如:
path.node指向当前 AST 节点,path.parent指向父级 AST 节点;
path.getSibling、path.getNextSibling、path.getPrevSibling获取兄弟节点;
path.isxxx判断当前节点是不是 xx 类型;
path.insertBefore、path.insertAfter插入节点;
path.replaceWith、path.replaceWithMultiple、replaceWithSourceString替换节点;
path.skip跳过当前节点的子节点的遍历,path.stop结束后续遍。
有了 @babel/traverse 我们可以在 tranform 阶段做很多自定义的事情,例如删除 console.log 语句,在特定的地方插入一些表达式等等,从而影响输出结果。我们再举一个例子,在 console 语句中增加位置信息的输出,形如:console.log('[18,0]', 111)。
import * as t from "@babel/types"; // 用来创建一些 AST 和判断 AST 的类型
traverse(ast, {
visitor: {
CallExpression(path, state) {
const callee = path.node.callee;
if (
callee.object.name === 'console' &&
['log', 'info', 'error'].includes(callee.property.name)
) {
const { line, column } = path.node.loc.start;
const locationNode = types.stringLiteral( `[ ${line} , ${column} ]` );
path .node.arguments.unshift(locationNode); }
},
},
})
generate(生成)
AST 转换完之后就要输出目标代码字符串,这个阶段是个逆向操作,用新的 AST 来生成我们所需要的代码,在生成阶段本质上也是遍历抽象语法树,根据抽象语法树上每个节点的类型和属性递归调用从而生成对应的字符串代码,在 babel 中通过 @babel/generator 包的 api 来实现。
generate(newAST) => newSourceCode
还拿前面的 transform 的代码举例,如下所示:
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const generate = require('@babel/generator').default;
const code = `function square(n) {
return n * n;
}`;
const ast = parser.parse(code);
traverse(ast, {
enter(path) {
if (path.isIdentifier({
name: "n"
})) {
path.node.name = "x";
}
},
});
const output = generate(ast, {}, code);
console.log(output)
// {
// code: 'function square(x) { return x * x;}',
// map: null,
// rawMappings: undefined
// }
由上面代码可以看到,函数里的变量 "n" 被替换成了 "x"。
总结
编译原理涉及大量的概念及知识,以实现完整编译链路的 GCC 编译器来看,单源代码就 600w 行,足以说明其水深且宽,但编译原理带来的价值是巨大的,可以说是编译原理的进步才有各种高级语言百花齐放,进而提高软件行业生产力。Babel 作为前端工程化领域一个很重要的工具,明白了其编译流程,对诸如其他工具 v8 引擎、 tsc、jsx 模板等前端方面的编译原理便可以融汇贯通,触类旁通。
❤️ H5-Dooring,让H5制作更简单
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
喜欢的话别忘了 分享、点赞、收藏 三连哦~。
欢迎关注公众号 趣谈前端 收获前端一手好文章~