
多模态预训练模型综述

极市导读
本文梳理总结了11个通用型的预训练模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
2021年诺贝尔生理学、医学奖揭晓,获奖者是戴维·朱利叶斯(DavidJulius)和阿代姆·帕塔博蒂安(Ardem Patapoutian),表彰他们在“发现温度和触觉感受器”方面作出的贡献。那作为算法从业者,我们该思考些什么呢?人在感知这个世界的时候,主要的方式就是视觉,嗅觉,听觉等等。其中语音,文字和图像是最重要的传播载体,这三个领域的研究也都在这几年得到了快速的发展,今天我们就来看看其交叉的领域即文字+图像的图文多模态,其实多模态涉及的领域很多,今天我们只看文字+图像这一分支(下文提到的多模态仅仅指语言视觉模型即Vision-Language 预训练模型)。从2018年Bert横空出世以后,以预训练模型为基石的各个领域百花齐放,下面我们要梳理的多模态预训练模型也是在这样一个背景下诞生的~~,具体大概是从2019年开始涌现的。目前布局在这一赛道的公司包括:腾讯、百度、谷歌、微软、Facebook、UCLA等等。
技术是不断更新的,相信以后会有更多的技术涌现出来,如果大家对这一方向比较感兴趣的话,可以实时关注VCR的榜单或者其他相关的榜单,就可以追踪到最新的idea。
VCR榜单:https://visualcommonsense.com/leaderboard/
除此之外,一些之前的有关预训练模型的其他方向的trick也被同步应用到了多模态预训练模型,比如Prompt-Tuning等等:
CPT:https://arxiv.org/pdf/2109.11797.pdf
需要说明的是目前这一赛道大的方面分为两块:通用型的预训练&特定领域的预训练,具体一些论文大家可以看:
GitHub - yuewang-cuhk/awesome-vision-language-pretraining-papers: Recent Advances in Vision and Language PreTrained Models (VL-PTMs)
https://github.com/yuewang-cuhk/awesome-vision-language-pretraining-papers
我们这里主要梳理通用型的预训练模型,与之相对的就是还有一些工作是研究一些特定领域的图文预训练模型的,当然文章最后也会简单介绍一篇特定领域的多模态预训练模型。
全文较长,建议收藏,慢慢消化~~~
Tasks & Datasets
● 一些常用的公开数据集

最近又有一个更大的多模态图文数据集:LAION-400,其包含了4亿图文对:https://sail.usc.edu/iemocap/
● 一些常见下游任务

主要分为理解式和生成式任务;理解式任务包括问答,推理,检索等等,如下图的VQA;生成式任务包括比如根据文字生成图片或者根据图片生成文字等等。

Key technology
为了大家对该方向的paper有一个更好的全局把握,这里先来梳理一下相关的技术点(部分看不懂的不要紧,可以详细看后面的论文,先大概脑子里有个整体框架就行),可以想象到要设计一个Vision-Language 预训练模型,其实主要涉及到三个关键技术:特征提取、特征融合和预训练任务。
(1)特征提取要解决的问题是怎么分别量化文字和图像,进而送到模型学习?
(2)特征融合要解决的问题是怎么让文字和图像的表征交互?
(3)预训练任务就是怎么去设计一些预训练任务来辅助模型学习到图文的对齐信息?
当然还有一些其他的零零散散的,但是也很重要的trick,比如:
(1) 训练的数据是文本和图像pair,怎么挖掘?
(2) 训练好的预训练模型怎么增量学习?
(3) 训练好的预训练模型怎么压缩?
(4) ......
目前这三个技术的通常做法是:
(1) 特征提取:文本端的表征标配就是bert的tokenizer,更早的可能有LSTM;图像的话就是使用一些传统经典的卷积网络,按提取的形式主要有三种Rol、Pixel、Patch三种形式。
(2) 特征融合:目前的主流的做法不外乎两种即双流two-stream或者单流single-stream;前者基本上就是双塔网络,然后在模型最后的时候设计一些layer进行交互,所以双流结构的交互发生的时间更晚。后者就是一个网络比如transformer,其从一开始就进入一个网络进行交互,所以单流结构的交互时间发生的更早且全程发生,更灵活;当然还有一类是Multi-stream(MMFT-BERT),目前还不多,不排除将来出现基于图文音等Multi-stream多模态模型。
(3) 预训练任务:这里就是最有意思的地方,也是大部分多模态paper的idea体现。这里就先总结一些常见的标配任务,一些特色的任务后面paper单独介绍
大家可以记一下下面的仍无简称,后面介绍paper的时候,凡是使用了相关预训练任务,都以简称一笔带过。
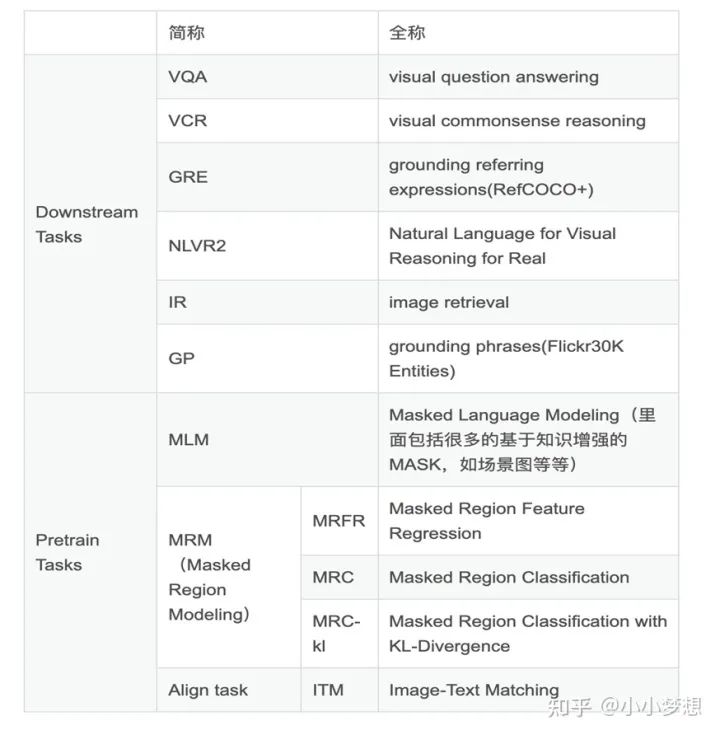
3.1 Masked Language Modeling ( MLM ):传统的文本屏蔽语言模型,针对的是文本流。
3.2 Masked Region Modeling(MRM):模仿MLM,只不过这里是对图片进行随机mask,针对的是图像流。被随机屏蔽的概率是15% ,替换成 0 和保持不变的概率分别是 90%和10%,这里又可以细化的分为Masked Region Feature Regression (MRFR) ,Masked Region Classification (MRC)和Masked Region Classification with KL-Divergence (MRC-kl)。主要的loss分别是L2 regression,cross-entropy (CE) loss,KL divergence 。
3.3 Image-Text Matching ( ITM ): 图文匹配任务,针对的是图文交互流,即判断当前pair是不是匹配(就是个分类任务),具体的是将图片的IMG token和文本的cls做element-wise product再经过一个MLP层来做相似性的监督学习。
papers & Summary
VILBERT

论文链接:https://arxiv.org/pdf/1908.02265.pdf
代码链接:https://github.com/facebookresearch/vilbert-multi-task
(1)特征提取:文本采用的是bert的tokenizer,图片是基于一个pretrain的object-detection网络生成图像rpn及其视觉特征。具体的是使用bounding boxes的左上角和右下角的坐标以及图像区域的覆盖占比形成的一个5-dim的vec,然后用一个MLP将之映射成与视觉特征一样的维数,然后做sum。
(2) 特征融合:可以看到这里其实是two-stream,交互主要是靠Co-TRM来完成的,那什么是Co-TRM呢?下面的右图就是Co-TRM,传统的TRM的q,k,v是来自同一个vec(self-attention),这里为了交互改进了这一结构,具体的为了在表征图片的时候考虑到其文本的上下文,那么q来自图片,而k,v都来自文本,同样在表征文本的时候,其k,v来自图片。
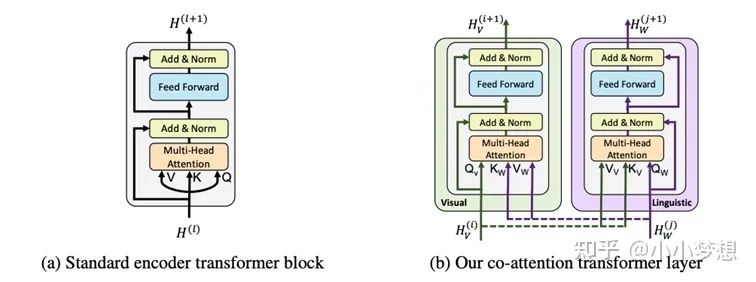
(3) 预训练任务:MLM、MRM:MRC-kl、ITM
B2T2
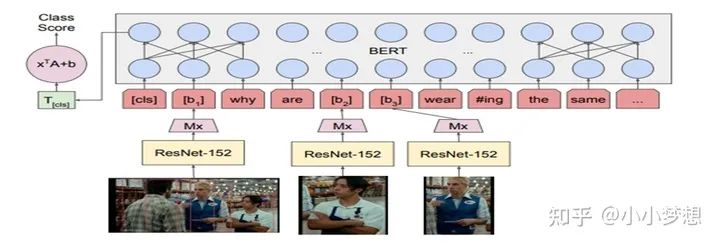
论文链接:https://arx-iv.org/pdf/1908.05054v1.pdf
(1)特征提取:文本采用的是bert的tokenizer,图片采用ResNet。
(2) 特征融合:可以看到这里是single-stream,这里的交互主要是靠加和,如下:等号右边的第一项就是正常的文本部分,第二项是图像特征。R是一个矩阵,可以简单理解为屏蔽矩阵,元素值只有(0,1),只有对应的文本token在图像的bounding box出现是1,也即最后才加和
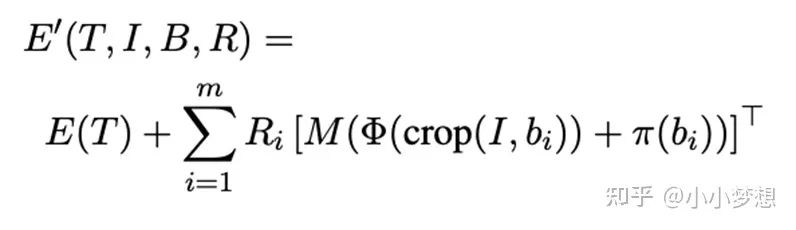
(3) 预训练任务:MLM、ITM。
LXMERT
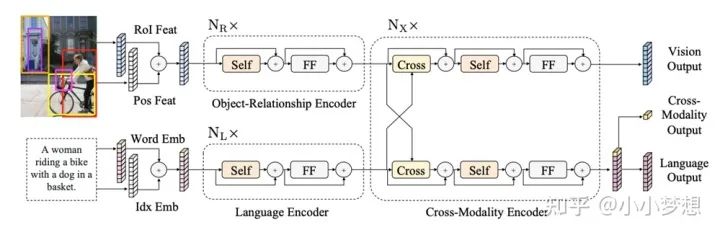
论文链接:https://arxiv.org/pdf/1908.07490.pdf
代码链接:https://github.com/airsplay/lxmert
(1)特征提取:文本采用的是bert的tokenizer,图片这里使用的是object-detection对图片进行分块,注意这里只是得到了Rol, 本质上还是图片,为了量化具体采用的是pre-trained R-CNN提取得到的表征。
(2) 特征融合:可以看到这里是two-stream,和Co-TRM结果基本一样。
(3) 预训练任务:MLM、MRM:MRC/ MRC-kl、ITM、QA
这里的QA:一个问答任务,作者为了扩大预训练的数据集,使用问答数据集,同时为了对比QA是否带来效果,做了一个消融实验(不加QA 20 epoch VS 10 epoch 不加QA 和10 epoch 加QA)发现QA带来收益。
VisualBERT
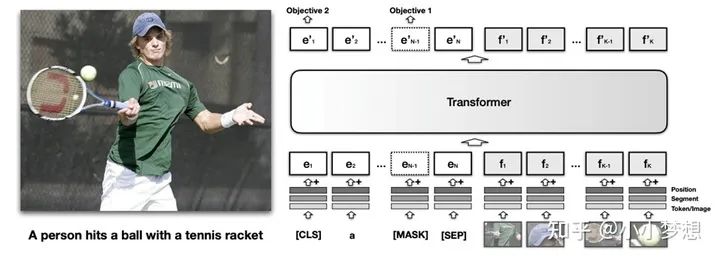
论文链接:https://arxiv.org/pdf/1908.03557.pdf
论文代码:https://github.com/uclanlp/visualbert
(1)特征提取:文本采用的是bert的tokenizer,图片这里依然使用的是ROI。
(2) 特征融合:可以看到这里是single-stream。
(3) 预训练任务:MLM、ITM
Unicoder-VL
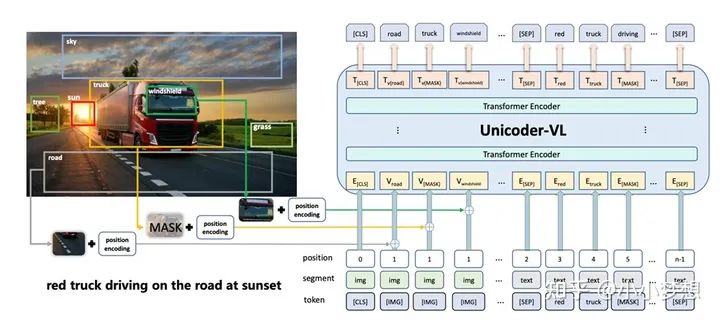
论文链接:https://arxiv.org/pdf/1908.06066.pdf
(1)特征提取:文本采用的bert的tokenizer,图片这里依然使用的是object-detection + Faster-RCNN。
(2) 特征融合:可以看到这里是single-stream,右半部分是文本,左半边部分是图像部分,基本上类似VL-BERT。
(3) 预训练任务:MLM、MRM:MRC、ITM
需要说明的是在MASK的时候,这里和VL-BERT不同的是,其实在Faster-RCNN之后mask(置0)
VL-BERT
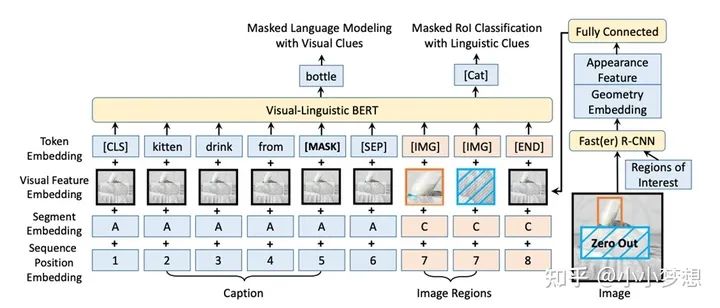
论文链接:https://arxiv.org/pdf/1908.08530.pdf
代码链接:https://github.com/jackroos/VL-BERT
(1)特征提取:文本采用的bert的tokenizer,图片这里依然使用的是object-detection+Faster-RCNN。
(2) 特征融合:可以看到这里是single-stream,左半部分是文本,右边部分是图像部分,文本沿用了之前的bert形式编码(sent_A sep sent_B,上图中只有sent_A),图像部分分为两块,前面是Rol,最后为了不丢失全局信息将整张图片加了进去即[END]部分。这里需要注意的是,对比Bert,segment是三部分即A,B,C分别是句子A,句子B,图像,sequence对于文本和之前一样,同时作者认为图像的Rol部分是没有顺序的,所以编码一样即上图都是7。
(3) 预训练任务:MLM、MRM:MRC
MRC 需要注意两点的是第一在mask 某一Rol后,全图对应的部分也要mask,不然会存在偷窥。第二是图像上做 mask,而不是在输出的特征图上做 mask,另外作者认为ITM 没有用,所以没加。
UNITER
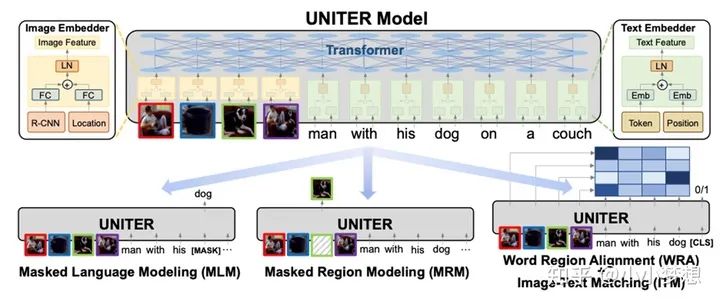
论文链接:https://arxiv.org/pdf/1909.11740.pdf
代码链接:https://github.com/ChenRocks/UNITER
(1)特征提取:文本采用的bert的tokenizer,图片这里依然使用的是object-detection+Faster-RCNN。
(2) 特征融合:可以看到这里是single-stream,左半部分是图像,右边部分是文本部分,基本上也是类似VL-BERT。
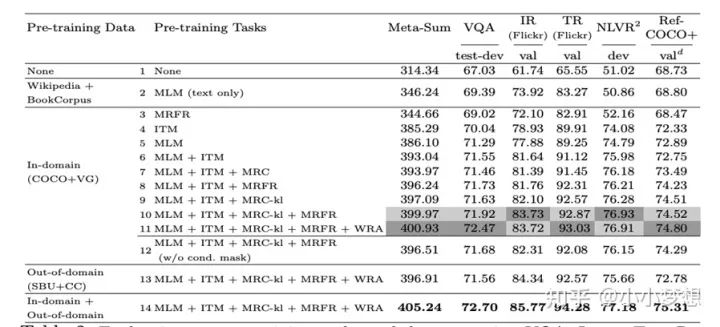
(3) 预训练任务:MLM、MRM:MRC/ MRFR /MRC-kl、ITM、WRA
3.1 注意最后MRM 这三种不是都使用了,这里作者进行了消融实验,作者对各种任务做了消融实验,包括MRM当中的三种变体如下,最后得出的最佳组合是:MLM + ITM + MRC-kl + MRFR + WRA。
3.2 WRA是一个图像和文本对齐任务,本质是一个Optimal Transport问题,大家也可以从下图的实验结果看到该任务的收益即第11个消融实验,尤其是在VQA和RefCOCO+上面。
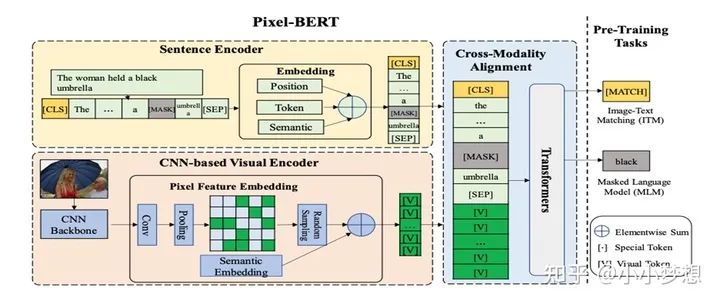
Pixel-BERT
论文链接:https://arxiv.org/pdf/2004.00849.pdf
(1)特征提取:文本采用的bert的tokenizer,图片这里使用的是Pixel。
(2) 特征融合:可以看到这里是single-stream,值得说的是作者做了一个Pixel Random Sampling,即随机从 feature map中抽取100 pixels ,这么做的好处有两个:增加了模型的健壮性,缓解了图像端的序列长度。
(3) 预训练任务:MLM、ITM
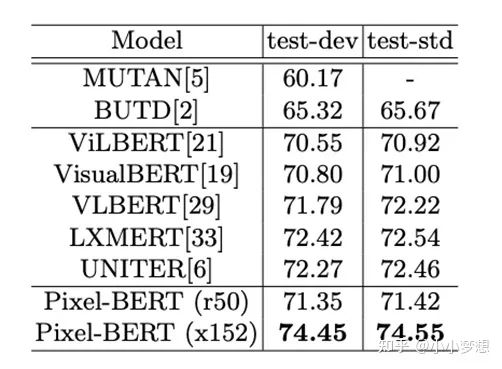

3.1这里需要说一下采用Pixel这种方法的理由是说如果采用如之前的目标检测其实就缺失了很多信息比如空间关系,以及重合等等,实验结果对比如下。
3.2另外作者对其提出的Pixel Random Sampling的策略也做了相应的消融实验:通过4和5的对比可以看到该策略在VQA、retrieval tasks和NLVR2 上的收益分别是0.5, 2.0 和0.4 。
ERNIE-ViL
论文链接:https://arxiv.org/pdf/2006.16934.pdf
代码链接:https://github.com/PaddlePaddle/ERNIE/tree/repro/ernie-vil
(1)特征提取:文本采用的bert的tokenizer,图片这里依然使用的是object-detection。
(2) 特征融合:可以看到这里是two-stream,基本上采用的是类似ViLBERT的结构。
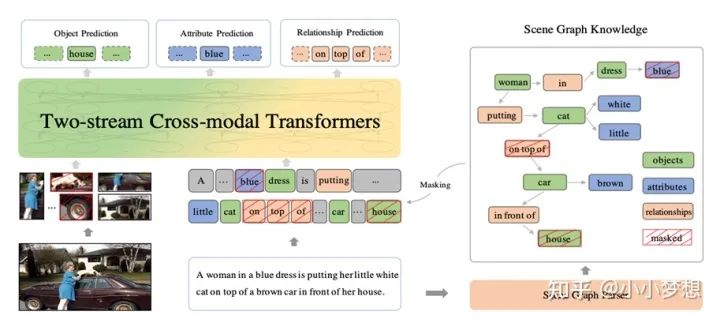
(3) 预训练任务:MLM、MRFR、ITM、SGP (scene Graph Prediction)
SGP场景图预测,这也是ERNIE-ViL的核心创新点,上图的右半部分就是所谓的场景图,可以看到其实就是目标+属性+关系的一个结构图。这些词被称为细粒度词,而a,the等等被看作是普通词,依据这个场景图,作者设计了三个具体任务即物体预测object prediction+属性预测Attribute prediction + 关系预测 relationship prediction,其实可以看到object prediction就是MRC,但是是从文本端的角度mask的(之前的实体MASK是MASK region)。
UNIMO
论文链接:https://arxiv.org/pdf/2012.15409.pdf
代码链接:https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO
之前都是只做多模态,作者认为这局限了数据量,因为上述方法只能在非常有限的多模态数据(图文pair)上进行训练,所以作者设计了统一模态预训练框架即UNIMO,能够有效地同时进行单模态和多模态,带来的最大好处就是可以利用大量的开放域文本语料和图片,简单来说就是增加了训练数据集。
(1)特征提取:文本采用的bert,图片这里依然使用的是object-detection。
(2) 特征融合:可以看到这里是three-stream, 图文融合的多模态是上图左边的cross-modal single-stream,然后文本和图片的单模态分别一个single-modal transformer。
(3)预训练任务:MLM、Seq2Seq generation、MRC/MRC-kl、ITM
3.1 MLM/Seq2Seq generation:需要注意这些任务在cross-modal和single-modal的文本序列中都有,Seq2Seq generation是为了使得模型具备文本生成任务加的一个任务。
3.2 MRC/MRC-kl:需要注意这些任务在cross-modal和single-modal的region图像序列中都有。
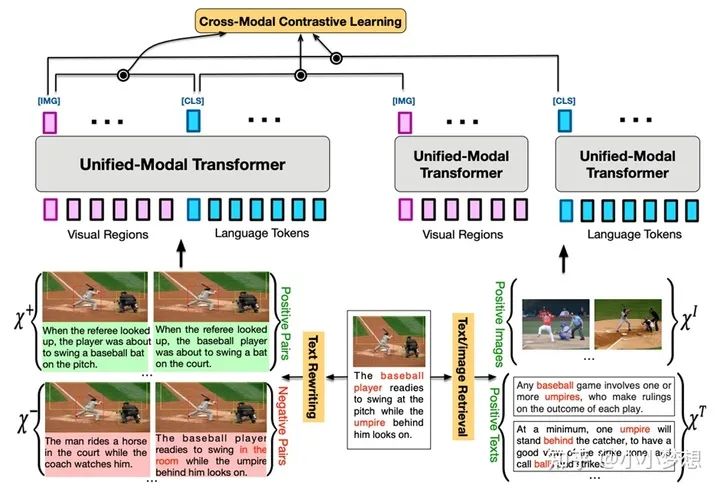
3.3 CMCL:将最近大火特火的对比学习应用了进来,之前的对比学习都是一个batch 内random 抽取得到负样本,作者认为这些只能让模型学到一些粗粒度的图文对齐,为此这里采用了两个重要的数据增强技术文本重写text rewriting和图文检索text/image retrieval,使得模型不但能够学习到一些细粒度方面的信息,且能够使的cross-modal利用到大量的single-modal数据资源。
(a) text rewriting:具体从三个层面对文本进行改写即sentence-level, phrase-level和wordlevel。具体细节如下:
sentence-level利用的是back-translation回译方法,这样得到的是正样本,此外还用了TF-IDF similarity取检索出相似的句子,这些检索的句子很像原来句子,但是不能很准确的描述图片,所以可以作为负样本,而且是一种hard negative samples。
phrase-level和wordlevel是利用了场景图(类似前面说的ERNIE_VIL),然后就是随替换object,attribute,relationship。这些也是负样本,而且是一种hard negative samples。
(b) text/image retrieval:这里就是根据当前图文pair中的图和文分别去检索出自己相似的图和文,然后这些检索的图和文其实相比于原始的的pair是弱相关性的,然后在进行对比学习的时候,这些检索出来的文本是单独过single-modal进行编码,然后和cross-modal做相似性,比如原始的图文pair是(v,w),v检索出来的有一个是v*,那么v*过single-modal得到的图表征和(v,w)过cross-modal得到的[CLS]的文本特征作为对比学习的目标。
这里说一下比较重要的结论:
其热启的模型是RoBERTa,那么其首先是多模态上超过了之前的Ernie-ViL等多模态预训练模型,其次是进一步验证了在单模态上面的效果,超越了RoBERTa本身(其他的多模态预训练都在单模态上面表现不好)
CLIP
论文链接:https://arxiv.org/pdf/2103.00020.pdf
代码链接:https://github.com/OpenAI/CLIP
解读:https://www.bilibili.com/video/av291385771/
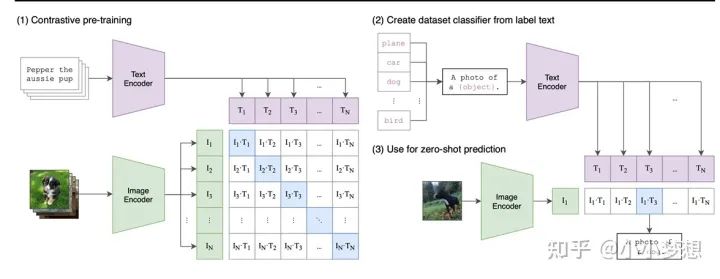
(1)特征提取:文本、图片都采用transformer,其中图片采用的是patch。
(2) 特征融合:可以看到这里是two-stream。
(3) 预训练任务:这里采用的是对比学习。上图(1)中I1,I2就是第一、二张图片表征,T1,T2就是第一、二条文本表征,其中I1、I2和T1、T2都是一一对应即T1是I1的描述,所以对比学习的目标就是使得矩阵对角线的pair距离越来越近,非对角线pair距离越来越远。由于矩阵特别大,所以将对比学习转化为分类任务,即对于I1来说,其在T1-TN上这N个类别中应该被分到T1,所以最后的loss就是按行(图像分类)和按列(文本分类)都做一个分类任务,取平均。
常见的上下游任务
paper我们就暂时刷到这里,基本上涵盖了最常见和出名的paper,如果大家对某一篇特别感兴趣的话,可以看原论文了解细节,下面我们就先总结一下上述模型涉及到的一些上下游任务,然后再整体对比看看异同。
常见的上下游任务
(1) IR里面包括图片检索文本任务Image Retrieval (IR) 和文本检索图片任务Text Retrieval (TR)。
(2) GRE和GP是差不多类型的任务都是根据一段文本的描述取定位到图像对应的region,使用的fintune的数据集不一样如上。
模型对比:
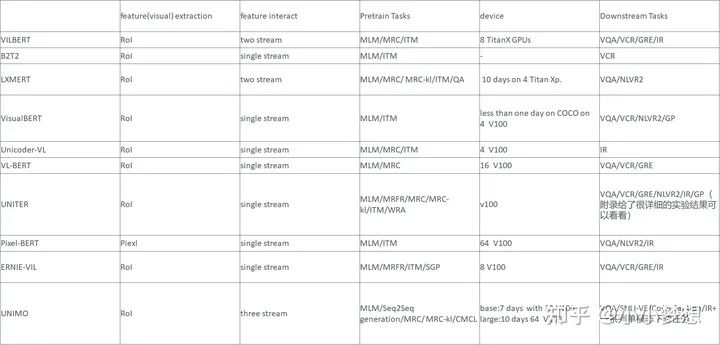
更详细一点的如下,同时可以看到这里的使用的数据集
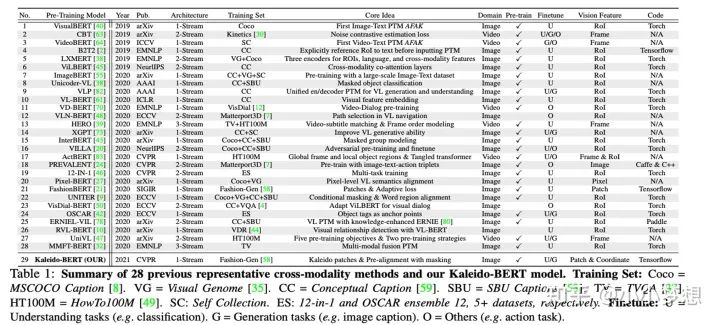
图片出自Kaleido-BERT
Task-specific Vision-Language pre-training
除了上述介绍的通用领域预训练模型之外,还有一些研究是着眼于一些特定领域比如情感识别领域等等,这里我们就介绍一篇阿里的关于时尚领域的多模态预训练模型。
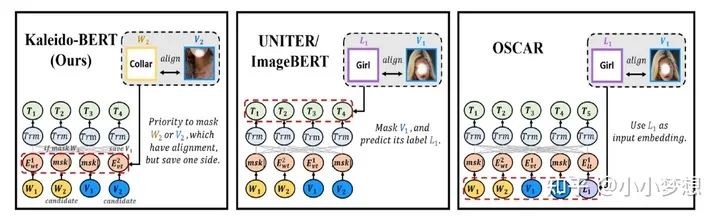
kaleido-BERT
论文链接:https://github.com/mczhuge/Kaleido-BERT
相比通用领域的预训练模型,在淘宝APP上等时尚领域面临的问题有:
(1) 图像特征表达:Rol 稀疏,Rol噪声,目标检测出来的非常少。通常一个图片就只有一个目标比如袜子。
(2) 确少图文信息先验理解:Masking 策略缺少模特关联信息(region-token),最好改策略使得模型有意识的甚至是显示的去学习。
(3) 图像欠拟合:即使有MRFR和MOC等,但是还是不够像文本端自监督任务。
为此作者提出以下idea:
针对第一个问题阿里之前的一篇 FashionBERT 采用了分块。
针对问题一:提出了KPG,先是提取Foreground(不需要学习空白位置这种lower level信息,更希望聚焦于语义,这主要是电商领域背景色大部分都是一个大空白),后面进行多尺度(多种粒度,1*1,2*2,3*3,4*4)kaleido图像块划分,作为图像特征输入。
针对问题二:提出了AGM,其中先要AAG得到了token-patch 的先验知识,只mask一侧。
针对问题三:提出了AKPM,1*1块例如旋转;2*2块拼图(分类);3*3块这里有三个任务是借鉴了MLM,具体为随机选取一个块,然后有三种mask,即随机替换(用另外一个3*3同样位置的),置灰,不变;4*4着色恢复任务(原始随机2个块置灰恢复原来的颜色);5*5:空白恢复任务(原始随机3个块置空白恢复原来)。
可以看到其实着色恢复任务相当于空白恢复任务是简单的,因为其还有一些问题的基本纹理,这里的一个逻辑就是让模型先掌握简单的,然后在这基础上再学会难的,其实AKPM中从1*1到5*5设计的任务就是一个由简单到难的过程。
关于这些任务的训练的顺序是怎么样的?是交替进行还是递进进行还是说一起进行的?这里问了作者是一起训练的。
论文做了很多消融实验,最后的实验结果是:前景提取和多尺度的设计对效果的提升最大,其次设计的AGM和AKPM也有一定的效果。
Conclusion
(1) 基本上现在的标配:就是single-modal层面的MASK预测,以及cross-modal层面的对齐学习。
(2) single-stream好还是two-stream好,目前没有一个绝对的结论,就目前看使用single-stream更多一些,使用single-stream的好处是特征融合更早更充分,使用two-stream一个明显的优势是参数量更多(意味着可以容纳更多的信息),先在前期提取了各种低阶特征,进而在高阶进行融合。
(3) 图像的提取Rol到Pixel到Patch,目前使用Rol方式居多,但是必然缺失了很多信息,最直观的就是空间,尽管一些模型都显示的加了位置embedding,但是一些隐式的也有缺失,毕竟目标外的甚至是目标检测模型不能检测的目标信息都丢失了,所以从包含的信息的角度考虑后两种更全。
(4) 粒度越来越细。语言模态上:从简单的MLM到mask 场景图,视觉模态上:从单纯的mask region 区域到mask object目标,kaleido-BERT的设计的AKPM任务等等。对齐任务上面的比如:kaleido-BERT的设计的AGM。这里也是可以挖掘的一个方向可以更细粒度,当然难点就是要挖掘的粒度下的训练pair的挖掘。对齐先验知识很重要,这块有更大的挖掘空间。
(5) 数据量越来越大。不论是使用对比学习还是什么手段,本质上就是为了使的模型可以利用更大的数据集。谁能利用的数据量更大且谁能挖掘更细粒度的对齐,效果应该是越好。
(6) 大一统模态即一个模型同时可以多模态单模态可能是一个方向,因为其利用的数据可以更多,且一个模型解决可以覆盖所有任务,应用也广。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
