来源:新智元
【导读】近日,北大校友、约翰·霍普金斯大学博士生提出了一种新的方法:MaskFeat,力压大神何恺明的新作MAE,摘下12个SOTA!
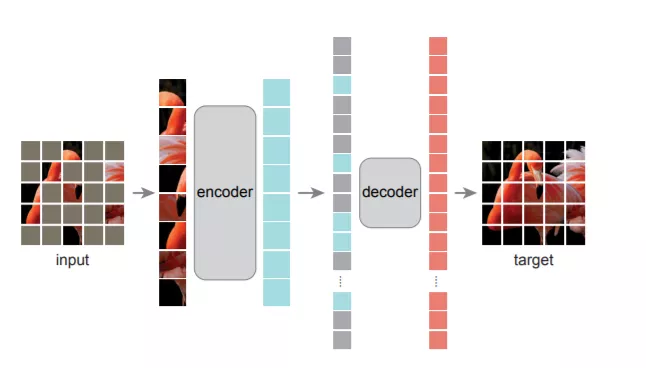
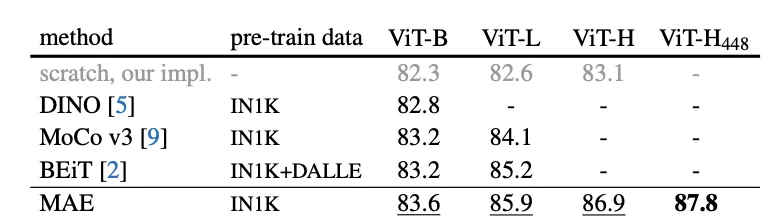
CV大神何恺明的力作「Masked Autoencoders Are Scalable Vision Learners」(MAE) 刚出了一个多月。这是一个能用于视频模型的自监督预训练方法:掩码特征预测(MaskFeat)。https://arxiv.org/abs/2112.09133简而言之,MaskFeat的ViT-B在ImageNet 1K上的准确率达到了84.0%,MViT-L在Kinetics-400上的准确率达到了86.7%,成功地超越了MAE,BEiT和SimMIM等方法。一作Chen Wei是约翰·霍普金斯大学的计算机科学博士生,此前在北京大学获得了计算机科学学士学位。并曾在FAIR、谷歌和华为诺亚方舟实验室实习,主要研究方向是视觉自我监督学习。
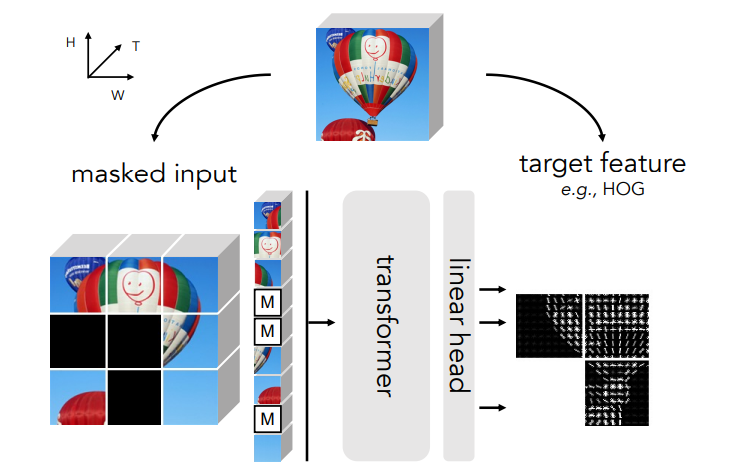
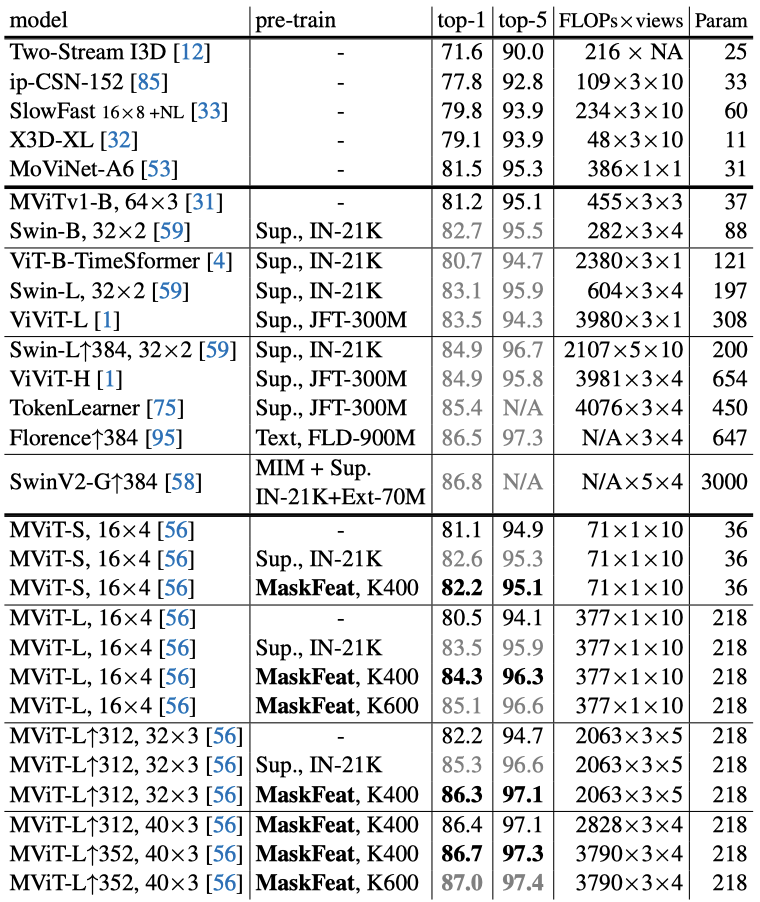
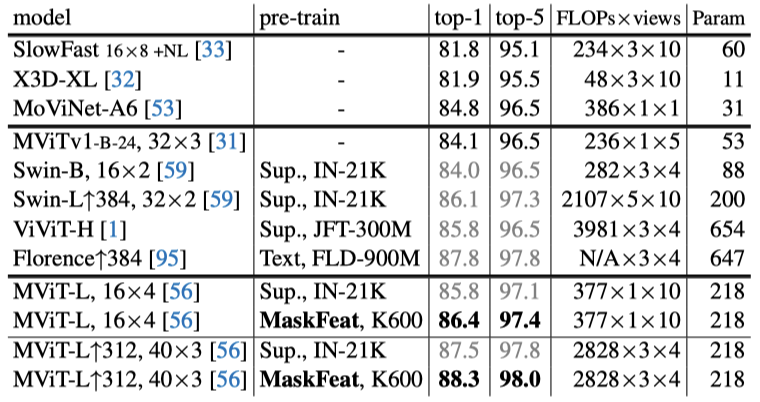
MAE最大的贡献,可能就是将NLP领域和CV两大领域之间架起了一座更简便的桥梁。https://arxiv.org/abs/2111.06377此前,大名鼎鼎的GPT和BERT已经将大型自然语言处理(NLP)模型的性能提升到了一个新的高度。直观点讲,就是事先遮住一些文本片段,让AI模型通过自监督学习,通过海量语料库的预训练,逐步掌握上下文语境,把这些被遮住的片段,用尽可能合乎逻辑的方式填回去。这和我们做「完形填空」的方式有些类似。经过海量数据的学习和训练,AI模型慢慢学会了自己生成自然文本。目前,随着GPT及其后续改进模型的不断进步,生成的自然文本几乎可以乱真。而何恺明的MAE就是把NLP领域已被证明极其有效的方式:「Mask-and-Predict」,用在了计算机视觉(CV)领域,先将输入图像的随机部分予以屏蔽(Mask),再预测(Predict)丢失的像素(pixel)。而就在上周,Facebook AI Research和约翰霍普金斯大学的研究人员提出了MaskFeat,也是采用「Mask-and-Predict」的方法,性能却比MAE上更进一步。「Mask-and-Predict」总要有个可以「Predict」的特征来让模型学习到东西。MaskFeat最核心的改变就是将MAE对图像像素(pixel)的直接预测,替换成对图像的方向梯度直方图(HOG)的预测。 图像HOG特征向量HOG是一种经典的图像特征提取算法,发表于2005年的CVPR,到现在已经收获了37000+的引用。 https://hal.inria.fr/file/index/docid/548512/filename/hog_cvpr2005.pdf像素作为预测目标,有一个潜在的缺点,那就是会让模型过度拟合局部统计数据(例如光照和对比度变化)和高频细节,而这些对于视觉内容的解释来说很可能并不是特别重要。相反,方向梯度直方图(HOG)是描述局部子区域内梯度方向或边缘方向分布的特征描述符,通过简单的梯度滤波(即减去相邻像素)来计算每个像素的梯度大小和方向来实现的。通过将局部梯度组织化和归一化,HOG对模糊问题更加稳健HOG的特点是善于捕捉局部形状和外观,同时对几何变化不敏感,对光的变化也有不变性,计算引入的开销还很小,可以忽略不计。这次,MaskFeat引入HOG,其实正是将手工特征与深度学习模型结合起来的一次尝试。MaskFeat首先随机地mask输入序列的一部分,然后预测被mask区域的特征。只不过,模型是通过预测给定masked input(左)的HOG特征(中间)来学习的,原始图像(右)并不用于预测。方向梯度直方图(HOG)这个点子的加入使得MaskFeat模型更加简化,在性能和效率方面都有非常出色的表现。在不使用额外的模型权重、监督和数据的情况下,MaskFeat预训练的MViT-L在Kinetics-400数据集上获得了86.7%的Top-1准确率。这个成绩以5.2%的幅度领先此前的SOTA,也超过了使用如IN-21K和JFT-300M这些大规模图像数据集的方法。此外,MaskFeat的准确率在Kinetics-600数据集上为88.3%,在Kinetics-700数据集上为80.4%,在AVA数据集上为38.8 mAP,而在SSv2数据集上为75.0%。相比于不使用预训练的CNN,严重依赖大规模图像数据集和监督性预训练的基于Transformer的方法,MaskFeat表现出极佳的性能。经过300个epoch预训练的MaskFeat将MViT-S,16×4的81.1%的top-1准确率提高了1.1%。其中,16×4表示该模型在训练过程中采用16个时间跨度为4的帧作为输入。而在K400上用MaskFeat预训练了800个epoch的MViT-L 16×4达到了84.3%的top-1准确率,比其基线高出了3.8%,比使用IN-21K训练的监督模型高出了0.8%。MaskFeat也以一己之力将K400上没有外部数据的最佳准确率(MoViNet-A6的81.5%)提高了5.2%。此外,MaskFeat仅用K400的结果(86.7%)就能和86.5%的Florence和86.8%的SwinV2-G不相上下。其中,Florence使用了9亿个文本-图像对,SwinV2-G使用了一个具有30亿个参数的巨型模型,并首先在IN-21K和7千万张内部图像的大型数据集上进行自我监督和监督预训练。可以说,MaskFeat在参数量、计算成本、数据和注释方面的高效性再次证明了直接在未标记的视频上进行预训练的优势,也为一种全新的视频预训练方式打开了大门。
图像HOG特征向量HOG是一种经典的图像特征提取算法,发表于2005年的CVPR,到现在已经收获了37000+的引用。 https://hal.inria.fr/file/index/docid/548512/filename/hog_cvpr2005.pdf像素作为预测目标,有一个潜在的缺点,那就是会让模型过度拟合局部统计数据(例如光照和对比度变化)和高频细节,而这些对于视觉内容的解释来说很可能并不是特别重要。相反,方向梯度直方图(HOG)是描述局部子区域内梯度方向或边缘方向分布的特征描述符,通过简单的梯度滤波(即减去相邻像素)来计算每个像素的梯度大小和方向来实现的。通过将局部梯度组织化和归一化,HOG对模糊问题更加稳健HOG的特点是善于捕捉局部形状和外观,同时对几何变化不敏感,对光的变化也有不变性,计算引入的开销还很小,可以忽略不计。这次,MaskFeat引入HOG,其实正是将手工特征与深度学习模型结合起来的一次尝试。MaskFeat首先随机地mask输入序列的一部分,然后预测被mask区域的特征。只不过,模型是通过预测给定masked input(左)的HOG特征(中间)来学习的,原始图像(右)并不用于预测。方向梯度直方图(HOG)这个点子的加入使得MaskFeat模型更加简化,在性能和效率方面都有非常出色的表现。在不使用额外的模型权重、监督和数据的情况下,MaskFeat预训练的MViT-L在Kinetics-400数据集上获得了86.7%的Top-1准确率。这个成绩以5.2%的幅度领先此前的SOTA,也超过了使用如IN-21K和JFT-300M这些大规模图像数据集的方法。此外,MaskFeat的准确率在Kinetics-600数据集上为88.3%,在Kinetics-700数据集上为80.4%,在AVA数据集上为38.8 mAP,而在SSv2数据集上为75.0%。相比于不使用预训练的CNN,严重依赖大规模图像数据集和监督性预训练的基于Transformer的方法,MaskFeat表现出极佳的性能。经过300个epoch预训练的MaskFeat将MViT-S,16×4的81.1%的top-1准确率提高了1.1%。其中,16×4表示该模型在训练过程中采用16个时间跨度为4的帧作为输入。而在K400上用MaskFeat预训练了800个epoch的MViT-L 16×4达到了84.3%的top-1准确率,比其基线高出了3.8%,比使用IN-21K训练的监督模型高出了0.8%。MaskFeat也以一己之力将K400上没有外部数据的最佳准确率(MoViNet-A6的81.5%)提高了5.2%。此外,MaskFeat仅用K400的结果(86.7%)就能和86.5%的Florence和86.8%的SwinV2-G不相上下。其中,Florence使用了9亿个文本-图像对,SwinV2-G使用了一个具有30亿个参数的巨型模型,并首先在IN-21K和7千万张内部图像的大型数据集上进行自我监督和监督预训练。可以说,MaskFeat在参数量、计算成本、数据和注释方面的高效性再次证明了直接在未标记的视频上进行预训练的优势,也为一种全新的视频预训练方式打开了大门。Kinetics-600 & Kinetics-700数据集
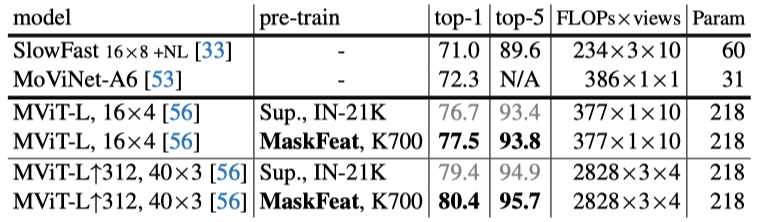
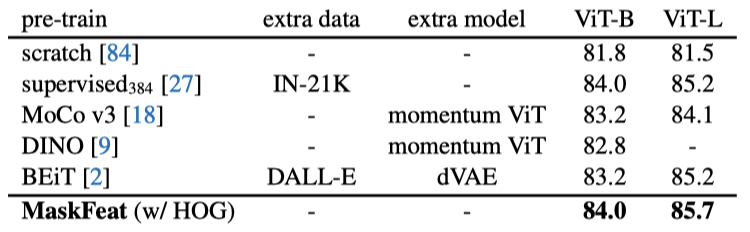
MaskFeat在K600和K700上分别达到了86.4%和77.5%的top-1准确率,与之前基于Transformer的方法相比,既没有使用外部的图像数据,而且FLOPs还减少了10倍以上。而在更大的输入分辨率312和更长的持续时间40×3下,MaskFeat在K600上实现了88.3%的top-1准确率,在K700上实现了80.4%的top-1准确率。于是,MaskFeat在没有任何外部监督(如IN-21K和JFT-300M)的情况下,为每个数据集都创造了新的SOTA。对MaskFeat进行1600个epoch的预训练,在ViT-B上微调100个epoch,在ViT-L上微调50个epoch。当图像大小为224x224时,MaskFeat与在IN-21K上进行的有监督的预训练相比,在ViT-B上打成了平手,而在ViT-L上直接实现了超越。当图像大小为384x384时,利用IN-21K的有监督预训练需要用到比MaskFeat多10倍的图像和标注。通常来说,由于缺乏典型的CNN归纳偏置,ViT模型对数据要求很高,并且需要大规模的监督预训练。而MaskFeat可以在没有外部标记数据的情况下通过解决特征图像修复任务来克服这个问题。此外,与BEiT相比,MaskFeat只需要计算HOG特征,摆脱了dVAE的tokenizer。而后者在250M DALL-E数据集上引入了额外的预训练阶段,并在mask预测期间引入了不可忽视的推理开销。与MoCo v3和DINO相比,MaskFeat也更准确、更简单。随着MAE、MaskFeat等模型的出现,NLP界的制胜武器「Mask-and-Predict」会是CV自监督预训练的下一个标准范式吗?对此,来自清华大学的知友「谢凌曦」表示:
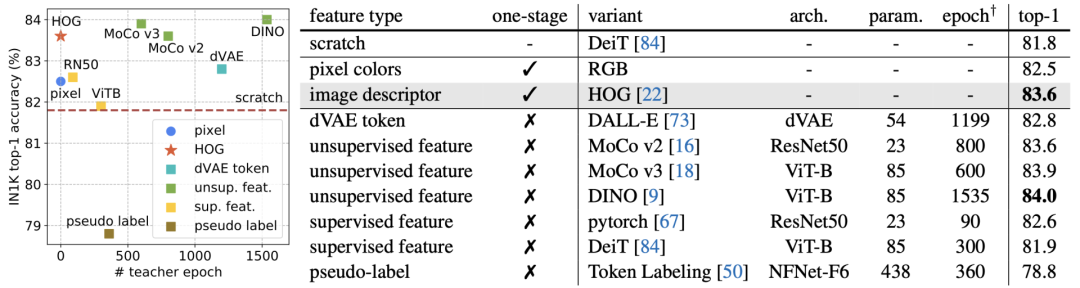
视觉自监督领域做了这么些年,从最早的生成式学习出发,绕了一圈,又回到生成式学习。到头来,我们发现像素级特征跟各种手工特征、tokenizer、甚至离线预训练网络得到的特征,在作为判断生成图像质量方面,没有本质区别。也就是说,自监督也许只是把模型和参数调得更适合下游任务,但在「新知识从哪里来」这个问题上,并没有任何实质进展。
参考资料:
https://arxiv.org/pdf/2112.09133.pdf
https://www.zhihu.com/question/506657286/answer/2275700206
推荐阅读
FAIR何恺明团队最新研究:定义ViT检测迁移学习基线
【何恺明新作速读】Masked Autoencoders Are Scalable Vision Learners
如何看待何恺明最新一作论文Masked Autoencoders Are Scalable Vision Learners?
为了方便读者学习交流,我们建立了微信交流群,欢迎大家进群交流讨论,你可以先加我的微信,邀请你进群。