
日常利器,shell脚本统计数据
前言
最近就干了两件有意思的事,昨天分享了一个,今天我们来分享另一个——shell脚本统计数据。
相比于python,shell是另一种特别常用,特别实用,也特别基础的脚本语言,基本上所有的linux系统都支持shell,更准确地说,shell让系统运行更方便,是shell让linux更强大,所以学习一些基本的shell语法,可以简化linux的运维工作,提升我们的工作效率。
其实,win平台也是有它的shell的,也就是bat或者cmd脚本,通过这些脚本,我们同样也可以做很多事,等下我们也分享一些win平台的常用脚本,让各位小伙伴见识下脚本语言的魅力。
好了,废话少说,下面我们开始编写数据统计脚本。
shell脚本统计数据
在开始之前,我们先看下shell的相关内容。shell通俗来讲就是我们通常说的CMD(commond,也叫命令行),通过shell我们可以直接与操作系统内核进行沟通。
至于为什么叫shell,也很好理解,shell的中文名称是壳,而kernel是操作系统的核心,核心是需要和外侧进行隔离的,通过什么来隔离呢,就是通过壳(shell),而且shell还要充当核心与外界沟通的信使。
当然shell本身也有好多种:
/bin/sh:已经被/bin/bash所取代/bin/bash:Linux预设的shell/bin/tcsh:整合C shell,提供更多的功能/bin/csh:已经被/bin/tcsh所取代/bin/zsh:自动补全功能很强大,检查拼写功能很强大,因为oh-my-zsh名声大噪,而且可定制性比bash更高
如果是日常使用的话,推荐使用zsh,但是如果是写脚本的话,建议用bash,毕竟它是linux的预装shell
简单介绍
下面是最简单的shell脚本:
#!/bin/bash
echo "hello shell"
结合我们上面shell的相关知识,我们可以推测出第一行是标记shell类别的,也就是用哪种shell来解释脚本;从第二行开始就是脚本的内容了。
运行这个脚本之后会在telminal控制台打印输出hello shell字符串:

shell脚本基本要点
linux系统的shell脚本文件后缀是.sh,也就是shell的简写。shell脚本的注释方式是# 注释内容,linux平台绝大多数的配置文件都是采用这种方式进行注释的:#!/bin/bash
# 我是脚本注释
eacho "hello shell"shell脚本有两种运行方式第一种是:
# 脚本名称hello.sh
sh hello.sh
# 或者
bash hello.sh
第二种方式是:
./hello.sh
虽然这两种方式都可以运行,但是第二种方式需要给脚本增加运行权限,具体命令如下:
chmod u+x hello.sh
u表示所属用户,+x表示增加运行权限,所以执行上面的这行命令,这个脚本就有了运行权限,然后再通过./hello.sh运行即可。
关于sh脚本的基础知识我们就先分享这么多,想系统学习的小伙伴可以去看下《鸟叔的Linux私房菜》,里面关于shell script讲的还是比较系统的,而且很全面,这本书也算是linux的中文圣经了。
编写统计脚本
下面这段脚本执行的操作很简单,首先是查询了db库配置库,并将结果写入到connect_info文件中,拿到查询结果之后,循环遍历,然后再次组装sql查询我们要统计的数据,并将数据写入count_data,之后我们就可以通过awk、sort、head等命令对结果进行解析、排序,最终拿到我们想要的结果。
#!/bin/bash
# mysql数据库配置信息
# 数据库端口
port=3306
# 数据库用户名
user="root"
# 数据库密码
pawd="root"
# 数据库地址
host="192.168.1.105"
# 库名
db_name="exam_system"
# 查询数据库连接信息
select_sql="select id, db_server, db_source_name from db_config"
# 统计sql
count_sql="select count(*) from question_option_info where question_id in (select id from question_info where type = 5 ) and CHAR_LENGTH(title) >= 50"
# 命令行连接mysql,并执行sql,这里我将查询结果输出到connect_info文件中
mysql -h "${host}" -P "${post}" -u"${user}" -p"${pawd}" -D${db_name} -N -s -e "${select_sql}" >connect_info
# 循环遍历
while read line
do
# 获取连接信息中的数据
config_id=`echo "$line"|cut -f1`
db_server=`echo "$line"|cut -f2`
db_name=`echo "$line"|cut -f3`
#mysql -h "${db_server}" -P "${port}" -u"${user}" -p"${pawd}" -D${db_name} -N -s -e "${count_sql}">>count_data
result=`mysql -h "${host}" -P "${port}" -u"${user}" -p"${pawd}" -D${db_name} -N -s -e "${count_sql}"`
echo "${config_id} ${result}" >> count_data
done < connect_info
这里我们简单解释下这段脚本,4~16行我们分别定义了7个变量,sh脚本定义变量的方式和python有点像,都不需要指定数据类型;
mysql命令参数
18行我们执行了一个mysql的命令,这行命令的作用是连接mysql并执行sql语句,-e表示执行并退出,后面直接跟sql语句,会直接打印sql,执行完成后会打印sql结果:

我以前真不知道还有这种操作方式,不是这次统计数据,应该不会去了解。
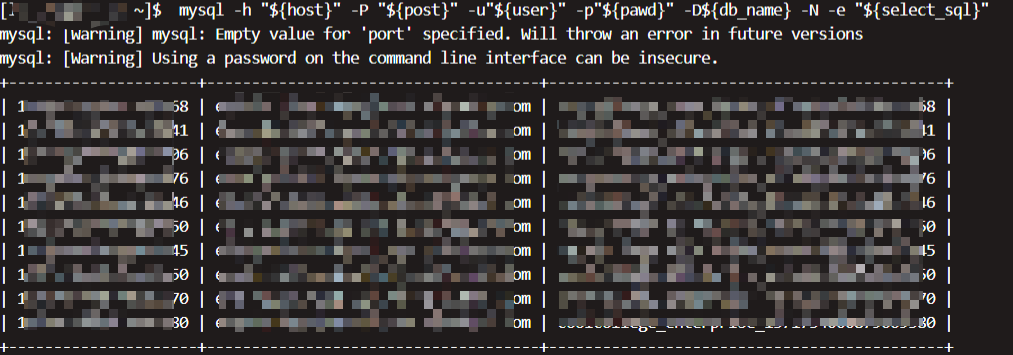
-s表示以制表符分割显示结果,不加这个参数的话,结果会包括|,也就是我们通常看到的结果:

不加-s查询结果如下:
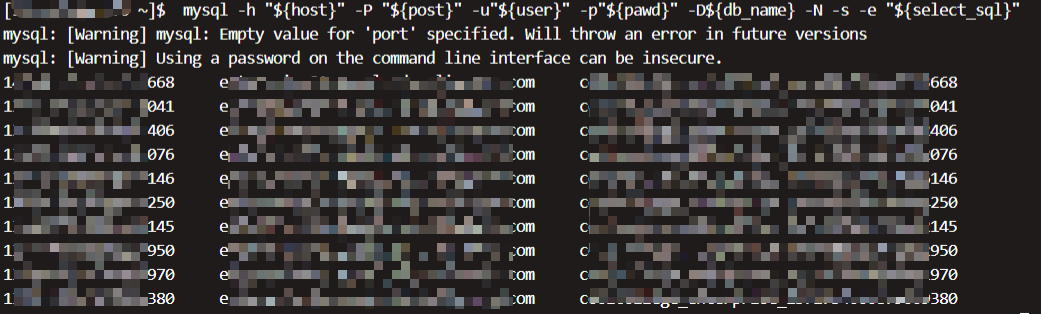
加了-s显示结果如下:
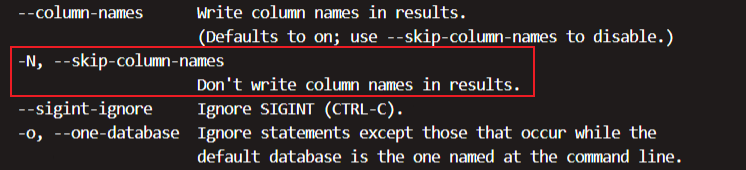
-N参数的作用是隐藏字段名称,也就是title(加上这个参数可以保证我们查询结果只有数据):
sh脚本要点
在sh脚本中,将运行结果输出到文件中有两种方式,一种是>,另一种是>>,两者的区别是,前者会覆写文件中的内容,而后者是在文件中追加(如果文件中已经存在内容,则会在原有内容后面追加新的内容),这种操纵在sh中很普遍,比如:
# 将 ls 结果输出到文件中
ls /home/syske > file_list
# 将当前时间输出到文件中,每次追加
date >> date_list
<与>刚好相反,是将文件的内容读取出来,比如:
# 读取 date_list
cat < date_list
另外除了直接将命令结果输出,我们还可以用变量接收运行结果:
result=`mysql -h "${host}" -P "${port}" -u"${user}" -p"${pawd}" -D${db_name} -N -s -e "${count_sql}"`
比如上面这行sh代码就是用result接收mysql的运行结果,需要注意的是命令必须通过( ` )进行包装,否则命令无法运行。这种方式有个好处,就是可以对结果进行处理,比如拼接变量:
echo "${config_id} ${result}"
运行结果处理
拿到运行结果之后,我们可以通过awk、sort等命令进行处理,以拿到最终数据。比如我们的查询结果如下:
Sun Nov 7 16:59:54 CST 2021
Sun Nov 7 16:59:57 CST 2021
Sun Nov 7 16:59:58 CST 2021
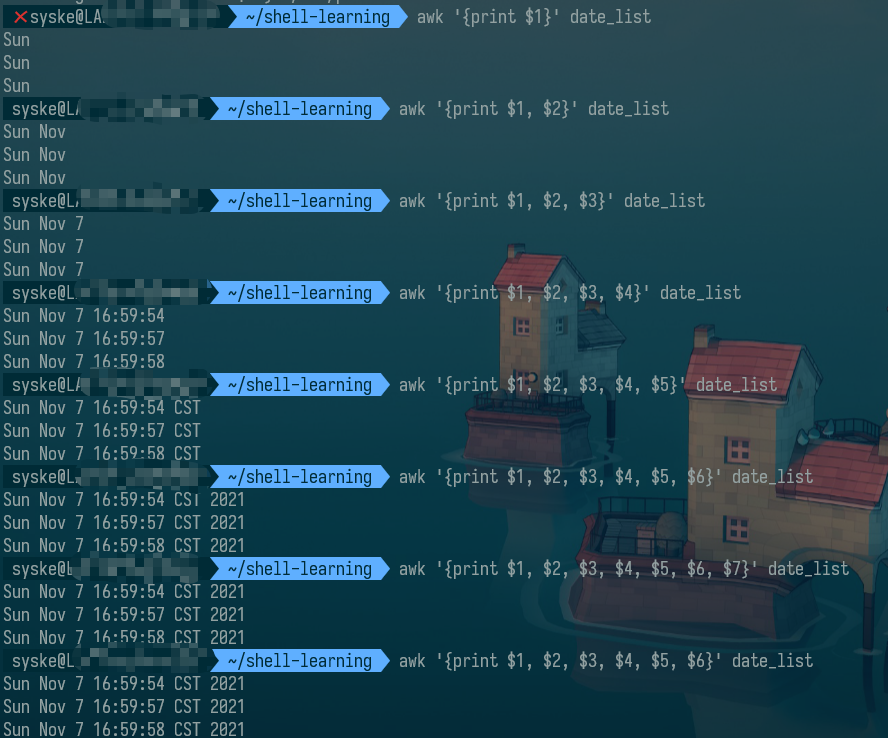
如果是通过awk处理,则可以直接帮我们将数据分割成:sun、Nov、7、16:59:54、CST、2021这样的格式,而且很简单:
awk '{print $1, $2, $3, $4, $5, $6}' date_list
这里的$1表示分割的第一部分,也就是Sun,其他以此类推;$0表示原始数据
排序的话,可以用sort命令进行操作:
awk '{print $1, $2, $3, $4, $5, $6}' date_list | sort -rk 4
排序结果如下:

其中-r表示降序排序,默认是正序排序,-k表示按指定序列排序,4表示按第四列排序,也就是按时间排序。更多其他排序可以参考sort文档。
最后再补充点akw的常用操作命令:
求和
cat data|awk '{sum+=$1} END {print "Sum = ", sum}'
求平均
cat data|awk '{sum+=$1} END {print "Average = ", sum/NR}'
求最大值
cat data|awk 'BEGIN {max = 0} {if ($1>max) max=$1 fi} END {print "Max=", max}'
求最小值(min的初始值设置一个超大数即可)
awk 'BEGIN {min = 1999999} {if ($1
扩展知识
这里再分享win环境下的几个常用命令:
关机操作:
# 休眠操作
shutdown /h
# 重启
shutdown /r
# 定时关闭(两小时后关机,单位秒)
shutdown /s /t 3600
显示指定文件夹下的所有内容,包括文件和子文件夹:
dir /b/s ./
显示指定文件夹树形结构:
tree ./
另外,我们前面说了,win平台也支持>和>>,这样我们就可以把上面命令的结果输出到文件中:
dir /b/s ./ > file_list.log
tree ./ >> struts.log
批量修改文件后缀(文件名)
# 修改文件扩展名
ren *.gif *.jpg
# 或者(ren和rename等同)
rename *.gif *.jpg
# 修改文件名
ren *.gif *-syske.gif批量删除文件
# 我经常通过这样的方式删除重复文件
del *(1).jpg
结语
shell脚本统计数据的内容我们就分享这么多,核心知识点包括shell的基本语法、linux的常用命令等,总体的内容难点并不大,如果实际工作中遇到了类似的需求,各位小伙伴可以参考。
最后,还想多说两句。在我的理解中,我觉得一切工具都可以变成生产力工具,最关键的还是要学会活学活用,养成一个善于动脑的小可爱,这样才能避免低效重复工作,有时候同样的工具,关键在于你如何用,你是否能够发现它的价值点,现实中的栗子有很多,比如回形针的一百种用法。
当然,实际工作中也会遇到很多类似的问题,比如你现在需要修改一批线上数据(400多条),数据的条件和更新内容各不相同,你能想到哪些处理方式?通过编辑器批量修改?还是手工一条一条修改?还是借助其他工具,python、excel?上周五我就完成了这样的工作,最终通过excel生成update sql,通过文本编辑器批量插入和替换拼接缓存key,最后完成相关数据修改。我说这个例子是希望各位小伙伴在学习和实践的时候,要学会发散思维,不要被当前的语言、环境、方法所局限,要学会解决问题,学会知识的横向应用,横向思考。好了,今天废话有点多,各位小伙伴,晚安吧!