科大讯飞CTR预估挑战赛Top3方案总结
今天要分享的是结构化的赛题-创意视角下的数字广告CTR预估挑战赛。
赛题任务
广告的CTR预估需要强大的数据作为支撑,本次大赛提供了讯飞AI营销云海量的现网流量和创意数据作为训练样本,参赛选手需基于提供的样本构建模型,预测测试集的点击率,点击率的准确性将直接影响评价结果。
数据说明
总体来说就是包含了多个ID信息、Embedding特征以及文本图像的一个多模态的数据。
评价指标
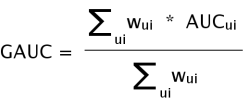
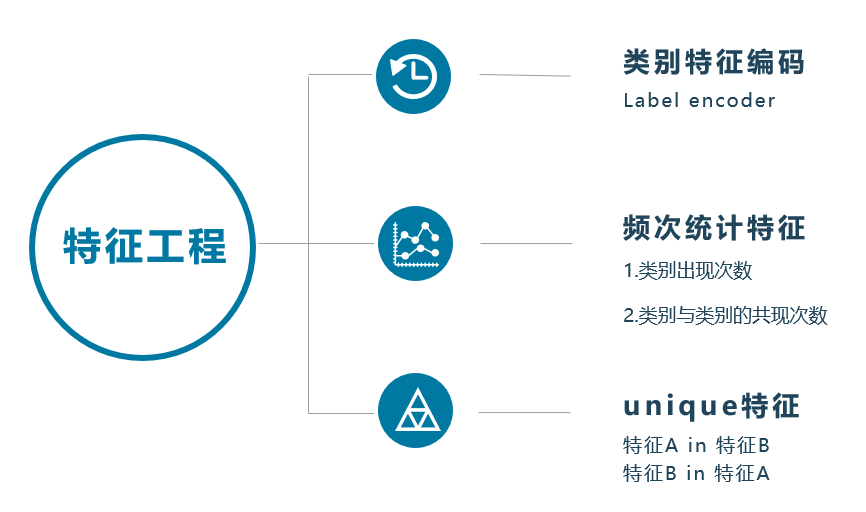
方案概述

评论

今天要分享的是结构化的赛题-创意视角下的数字广告CTR预估挑战赛。
广告的CTR预估需要强大的数据作为支撑,本次大赛提供了讯飞AI营销云海量的现网流量和创意数据作为训练样本,参赛选手需基于提供的样本构建模型,预测测试集的点击率,点击率的准确性将直接影响评价结果。
总体来说就是包含了多个ID信息、Embedding特征以及文本图像的一个多模态的数据。