
Facebook万字长文:AI模型将全部迁移至PyTorch框架
AI算法与图像处理
共 5770字,需浏览 12分钟
·
2021-06-13 16:28
点击下面卡片关注,”AI算法与图像处理”
最新CV成果,火速送达
来源:新智元



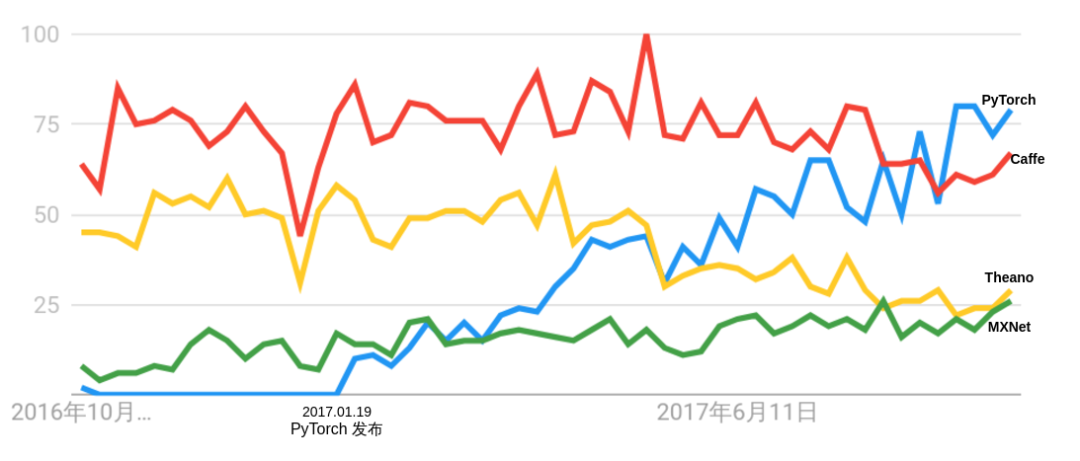
PyTorch 的诞生
PyTorch 的诞生





来自 Facebook 的 PyTorch 支持的技术
来自 Facebook 的 PyTorch 支持的技术
Instagram个性化技术
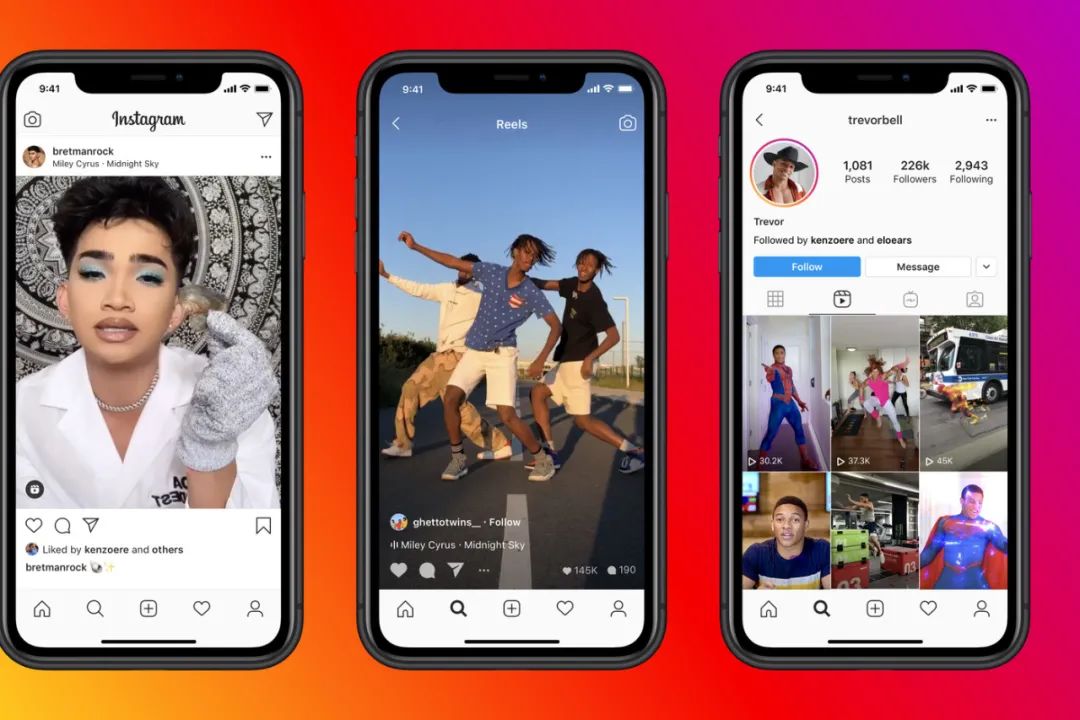
人物分割模型
现在,想象一下他们在自己的移动设备上完成这些,不需要使用专业的绘图软件或者视频制作设备。
当软件捕获一个人在物理空间中的位置时,它就会在人物周围放置增强现实图形,以及这些图形应该如何与人物交互。

模型使用 Detectron2Go (D2Go)进行训练,这是一个新的、最先进的 PyTorch 扩展。
PyTorch加入网络有害内容对抗



文本到语音

光学字符识别

OCR 可以从图像和视频中定位和提取多种语言文本,用于从完整性到搜索的各种案例。通过将OCR的框架切换到PyTorch,团队已经能够使系统更加强健,更容易。

将AI模型迁移至PyTorch的优势在哪?
将AI模型迁移至PyTorch的优势在哪?


参考资料:
https://ai.facebook.com/blog/pytorch-builds-the-future-of-ai-and-machine-learning-at-facebook/
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
评论