
李飞飞提出深度进化强化学习新框架:创建具身智能体学会动物进化法则

新智元报道
新智元报道
来源:外媒
编辑:Yaxin, LQ
【新智元导读】6亿多年的进化中,动物表现出显著的具身智能,利用进化学习复杂的任务。研究人员称,AI智能体也可以很快学会动物的这种智能行为,但目前推动具身认知面临很多挑战。最近斯坦福李飞飞教授等人的研究「深度进化强化学习」有了突破,首次证明了「鲍德温效应」。
智能体/代理(Agents)是人工智能领域的一个主要研究课题,分为非具身智能和具身智能。
而创建具身智能体是一个非常具有挑战的任务,所以当前人工智能领域更加关注「非具身认知」。
最近,李飞飞和其他几名学者提出了一个新的计算框架——深度进化强化学习——Deep Evolutionary Reinforcement Learning (DERL),基于该框架,具身智能体可以在多个复杂环境中执行多个任务。
此外,本研究还首次通过「形态学习」(morphological learning)证明了进化生物学中的「鲍德温效应」。
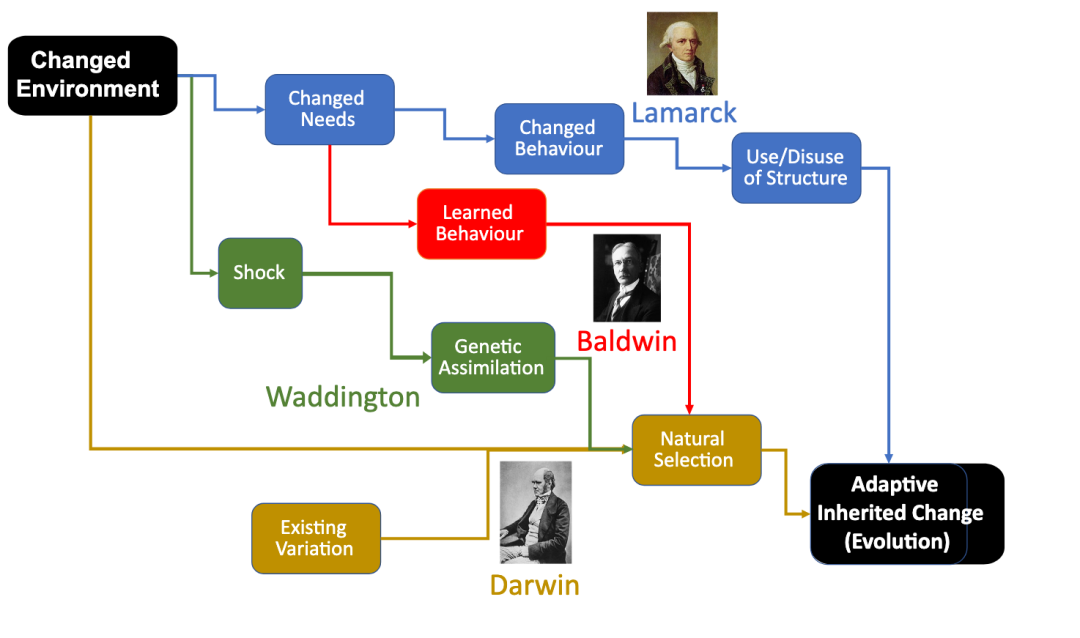
1953年,美国古生物学家George Gaylord Simpson创造了术语「鲍德温效应」,其中提到了美国哲学家和心理学家JM Baldwin的1896年论文中进化的一个新的因素。
在进化生物学中,鲍德温效应提出,在进化过程的早期世代一生中最初学会的行为将逐渐成为本能,甚至可能遗传给后代。
在过去的6亿年里,进化带来了无数形态的美:从古老的两侧对称的昆虫到各种各样的动物形态。

这些动物还表现出显著的具身智能,利用进化学习复杂的任务。
具身认知的研究人员认为,AI智能体可以很快地学会这种智能行为,而且它们的形态也能很好地适应环境。
然而,人工智能领域更注重「非具身认知」,如语言、视觉或游戏。
当AI智能体能够很好地适应环境时,它们就可以在各种复杂环境中学习控制性任务。然而,由于以下原因,创建这样的智能体非常具有挑战性。
这需要在大量潜在模式中进行搜索。通过终身学习评估一个智能体的适应性需要大量的计算时间。
因此,以往的研究要么是在极其有限的形态学搜索空间中使智能体实现进化,要么是在给定的人工设计形态学下寻找最优参数。
评估适应性的困难使得以前的研究避免了直接在原始感官观察的基础上学习自适应控制器;
学习使用少量参数(≤100)手动设计控制器; 学习预测一种形式的适应性;
模仿拉马克进化而不是达尔文进化,直接跨代传递学习的信息。
此外,以前的研究主要局限于在地面上移动的简单任务。
智能体自由度(DoF)比较少 ,或者由多个立方体构成,这就进一步简化了控制器的学习问题。
三种维度:环境、形态和控制,具身智能体可以执行哪些任务?
三种维度:环境、形态和控制,具身智能体可以执行哪些任务?
斯坦福大学李飞飞和Agrim Gupta,Silvio Savarese,Surya Ganguli研究人员提出的新型计算框架——深度进化强化学习(DERL)可以在环境,形态和控制这三种复杂维度同时扩展创建具身智能体的规模。
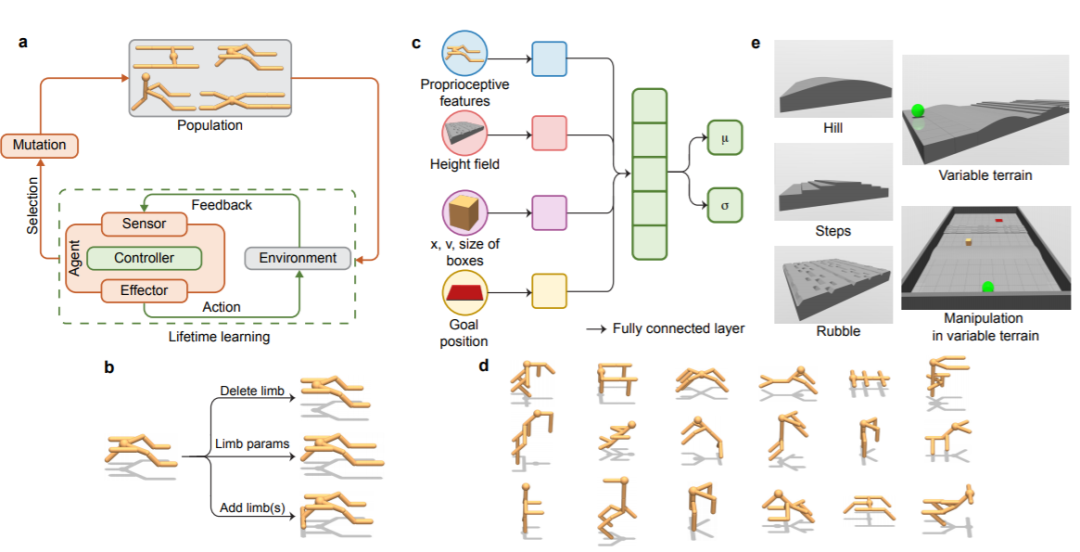
DERL为计算机模拟实验中的大规模具身智能体创建活动打开了一扇门,这有助于获得有关学习和进化如何协作以在环境复杂性,形态智能和控制的可学习性之间建立复杂关系的科学见解。
此外,DERL还减少了强化学习的样本低效性的情况。智能体的创建不仅可以使用更少的数据,而且可以泛化和解决各种新任务。
DERL通过模仿达尔文进化论中错综复杂的代际进化过程来搜索形态空间,并通过终生神经学习的智能控制解决复杂任务来评估给定形态的速度和质量。

斯坦福大学教授,论文的作者李飞飞表示,「这项研究不仅提出了一种新的计算框架,即深度进化强化学习(DERL),而且通过形态学习首次证明了达尔文-鲍德温效应。形态学习对于自然界中的动物进化至关重,现已在我们创建的 AI 智能体中展现」。
在这项研究中创建的具身智能体可以平地(FT),多变地形(VT)和多变地形的非抓握操作(MVT)中执行巡视(patrol)、点导航(point navigation)、避障(obstacle)、探索(exploration)、逃脱(escape)、爬坡(incline)、斜坡推箱子(push box incline)和控球(manipulate ball)等任务。
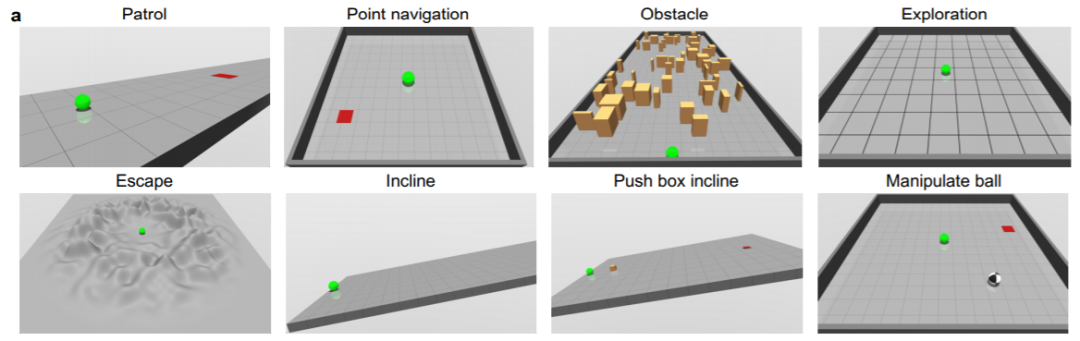
DERL:用于创建具身智能体的计算框架,Universal aniMAL 形态设计空间
DERL:用于创建具身智能体的计算框架,Universal aniMAL 形态设计空间
为了学习,每个智能体仅通过接收低级自我感知和外部感受观察来感知世界,并通过由深度神经网络的参数确定的随机策略选择其动作。
该随机策略是通过近端的深度神经网络的参数策略优化(PPO)学习得到。
通常,DERL允许研究人员在1152个CPU上进行大规模实验,平均涉及10代进化,搜索和训练4000种形态,每种形式有500万智能体与环境的交互(即学习迭代)。
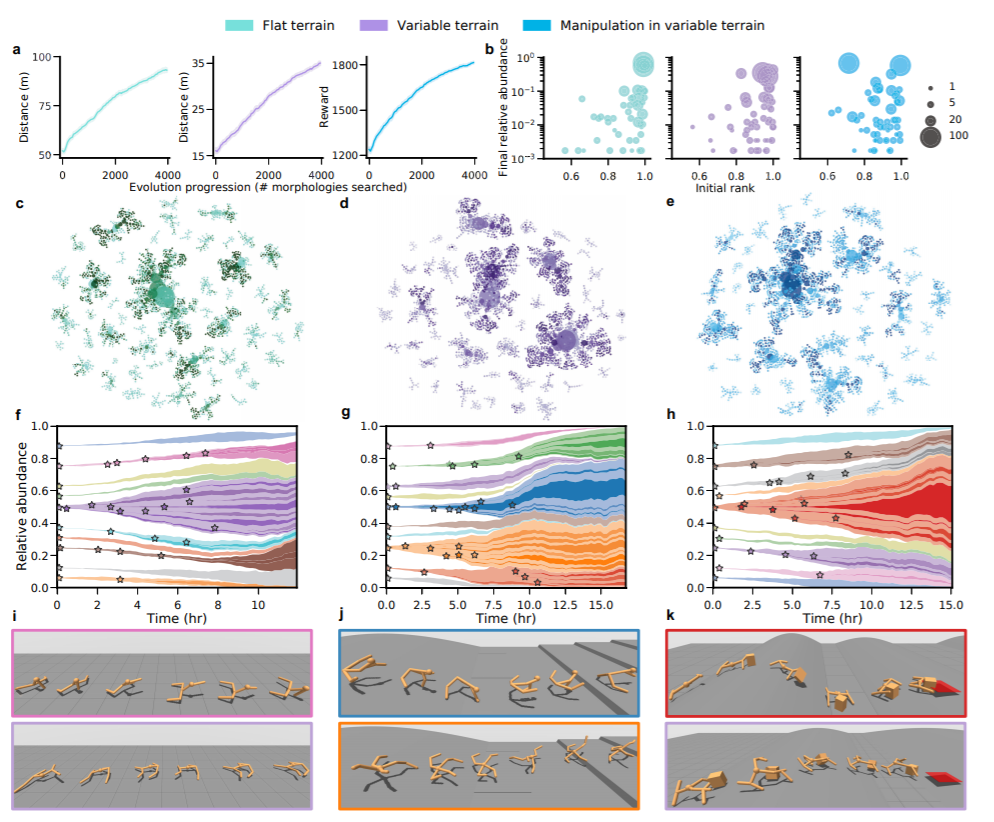
多种形态中进化动力学
该研究可以在并行的异步竞赛中训练288种形态,因此在任何给定时刻,整个学习和演化过程都可以在16小时内完成。
可以理解为,这是迄今为止形态进化和RL的最大同时模拟。
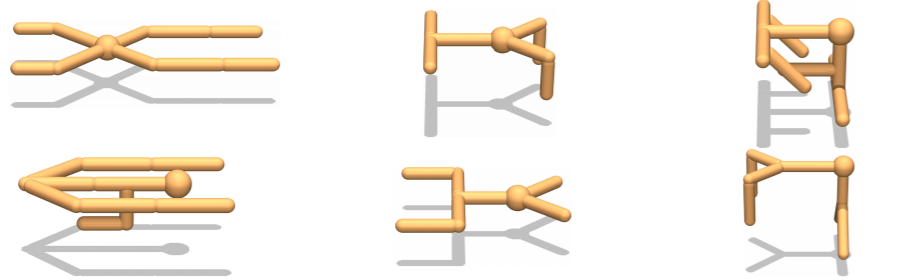
为了克服过去形态学搜索空间表达能力的局限性,本研究引入了 Universal aniMAL(UNIMAL)设计空间。
本研究的基因型(genotype )是运动树,它对应于通过电机驱动的铰链连接的3D刚性零件的层次结构。
运动树的节点由两种类型的组件组成:代表智能体头部的球体(树的根)和代表肢体的圆柱体。
进化通过三种类型的变异算子无性繁殖:
1 通过增加或减少肢体来收缩或生长运动树
2 改变现有肢体的物理特征,如长度和密度
3修改四肢之间关节的属性,包括自由度、旋转角度限制以及齿轮比
最重要的是,该研究只允许保持两侧对称的成对变异,这是动物形体构型在进化过程中最古老的特征(起源于6亿年前)。
一个关键的物理结果是,每个智能体的质心都位于矢状面,从而减少了学习左右平衡所需要的控制程度。
尽管有这一限制,但该研究提出的形态设计空间极具表达力,包含大约1018种独特的智能体形态,至少有10个肢体。
研究小组表明, 利用DERL证明了环境复杂性、形态智能和控制的可学习性之间的关系:
首先,环境复杂性促进了形态智能的进化,可用形态促进新任务学习的能力来量化。
其次,进化快速选择学得更快的形态,从而使早期祖先一生中较晚学会的行为在其后代一生中较早表现出来
第三,实验表明,通过物理上更稳定、能量效率更高的形态的进化,促进学习和控制,鲍德温效应和形态智能的出现都有一个机理基础。
参考链接

