手把手带你玩转Apache MADlib
大数据文摘授权转载自数据派THU
作者:陈之炎
随着数据规模的不断扩大,目前,许多现有的分析解决方案都无法胜任大规模数据量的计算任务。利用MADlib项目来创建一个框架,以满足大规模数据量的需求,该框架旨在利用现代计算能力,提供适应业务需求的强大解决方案。
概述
MADlib实现方案来自商业实践、学术研究和开源开发社区的多方面努力,它是一个基于SQL的数据库内置的可扩展的开源机器学习库,由Pivotal与UCBerkeley合作开发。MADlib创始于2011年,当时属于EMC/Greenplum,后来Greenplum变成了pivotal的Greenplum。主要由伯克利的学者:Joe Hellerstein发起,Stanford, University of Wisconsin-MADISON和University of Florida也有参与。MAD一词来源于:MagneticAgile、Deep三个词的首字母,意为有吸引力的、快速的、精准深入的,三个单词连在一起,意思是“极好的”,旨在为数据科学家们提供一个极好的机器学习和数据分析平台。
MADlib提供了丰富的分析模型,包括回归分析,决策树,随机森林,贝叶斯分类,向量机,风险模型,KMEAN聚集,文本挖掘,数据校验等。MADlib支持Greenplum,PostgreSQL 以及 Apache HAWQ, In-Database Analytics的特性使其大大扩展了数据库的分析功能,充分利用MPP架构使其能够快速处理海量数据集。
本文将为大家介绍MADlib的基本架构,工作原理及特性,并为开发人员提供快速入门指南。
ADlib创始于2011年,2015年7月MADlib成为Apache软件基金会的孵化器项目,经过两年的发展,于2017年8月成为Apache顶级项目。整个项目和代码是在Apache上是开源的,已经正式发布了MADlib 1.14、MADlib 1.15、MADlib 1.15.1、MADlib 1.16 等多个正式版本。

Apache MADlib 架构
MADlib有以下三个主要组件:
Python 驱动函数 C++ 实现函数 C++ 数据库抽象层
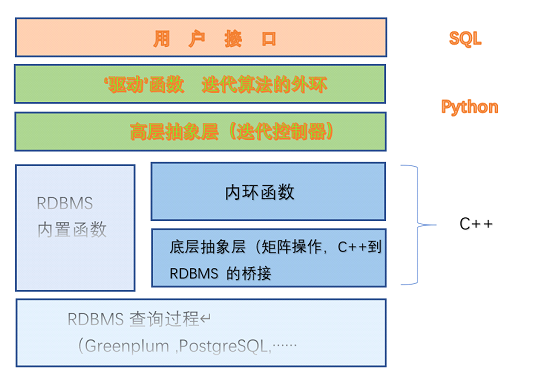
Python 驱动函数
Python 驱动函数位于如下子目录中:
https://github.com/apache/incubator-madlib/tree/master/src/ports/postgres/modules
这些功能是用户输入的主要入口点,主要负责算法的流程控制。一般来说,实现包括验证输入参数、执行SQL语句、评估结果和潜在的循环来执行更多的SQL语句,直到达到收敛标准为止。
C++实现函数
大多数位于如下子目录中:
https://github.com/apache/incubator-madlib/tree/master/src/modules
这些函数是特定算法所需核心函数和集合的C++定义。由于性能原因,这些都是在C++而不是Python中实现的。
C++ 数据库抽象层
大多数位于如下子目录中:
https://github.com/apache/incubator-madlib/tree/master/src/dbal
和:
https://github.com/apache/incubator-madlib/tree/master/src/ports/postgres/dbconnector
这些函数试图提供一个编程接口,将所有Postgres内部细节抽象掉,并提供一种机制,使MADlib能够支持不同的后端平台,并专注于内部功能而不是平台集成逻辑。
MADlib架构的主要理念:
在本地数据库中操作数据。无需在多个运行时环境之间进行不必要的数据移动。 利用最好的breed数据库引擎,将机器学习逻辑与数据库特定的实现细节相剥离 利用MPP共享技术,如Greenplum数据库,提供并行性和可伸缩性。 开放的实施维护措施,与Apache社区和正在进行中的学术研究保持密切的联系。
开发人员快速入门指南
准备工作
可以按照MADlib安装指南中的步骤安装MADlib,也可以使用下面的Docker映像指令来安装。
MADlib源代码的组织方式如下:机器学习或统计模块的核心逻辑位于一个公共位置,数据库端口特定的代码位于 ports文件夹中。由于当前支持的所有数据库都是基于Postgres的, 所以Postgres端口包含所有特殊端口的文件,并从中继承 greenplum和 hawq文件。在继续使用本指南之前,建议熟悉一下 MADlib module anatomy 这个文档。
Docker映像
Docker映像提供了在PostgreSQL 9.6上编译和测试MADlib所必需的依赖性,可以在 /tool/docker/base/docker file_postgres_9_6中查看到依赖项docker文件,映像位于docker hub上的 madlib/postgres U 9.6:latest,稍后将为Greenplum数据库提供一个类似的Docker映像。
使用Docker文件的一些常用命令:
##1)从docker hub下拉“madlib/postgres”U 9.6:latestyin映像:docker Pull madlib/postgres”U 9.6:latest##2)启动与MADlib映像对应的容器,将源代码文件夹装入容器:docker run-d-it--name MADlib-v(incubator-madlib目录的路径):/incubator MADlib/MADlib/postgres U 9.6其中incubator-madlib是MADlib源代码所在的目录。##############################################*警告*###################################################请注意,如上图所示安装时,在“incubator-madlib” Docker容器中的文件夹中所做的任何变动#将反映在本地磁盘上(反之亦然)。这意味着从Docker容器中删除已装入卷中的数据也会导致本地磁盘中数据丢失。###############################################################################################################3)容器启动后,连接到它,并构建MADlib:docker exec-it MADlib bashmkdir/incubator madlib/build docker cd/incubator madlib/build docker cmake..make docmake install##4)安装MADlib:src/bin/madpack-p postgres-c postgres/postgres@localhost:5432/postgres install##5)运行其他几个madpack命令:#对所有模块进行运行安装检查:src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres install-check#在特定模块(比如说svm)上运行install check:src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres install-check -t svm#在所有模块上运行dev check(比install check更全面):src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres dev-check#在特定模块上(比如说svm)运行dev check:src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres dev-check -t svm#重新安装MADlib:src/bin/madpack -p postgres -c postgres/postgres@localhost:5432/postgres reinstall##6)杀死并移除容器(退出容器后):docker Kill madlibdocker rm madlib
添加新模块
添加一个名为 “hello_world” 新模块。在这个模块中,实现了一个名为 avg_var的用户自定义的SQL聚合(UDA),它计算表的给定数值列的平均值和方差。在此,将实现一个分布式版本的Welford's online algorithm(Welford在线算法)来计算均值和方差。
与PostgreSQL中的普通UDA不同, avg_ar也可以在分布式数据库上运作,并利用底层分布式网络进行并行计算。使用avg_var也十分简单,用户仅需运行如下psql命令:

之后,将在屏幕上打印三个数值:均值、方差和名为bath的表格中的行数。
通过以下几步实现:
注册模块。 定义SQL函数。 在C++中实现函数。 注册C++头文件。
此练习的文件的源代码可以在hello world文件夹 中找到。
1.注册模块
在 /src/config/目录下的名为 Modules.yml的文件中添加以下行

并创建两个文件夹:/src/ports/postgres/modules/hello-world和 /src/modules/hello-world。这两个文件夹的名称应和Modules.yml 中定义的模块名称相匹配。
2.定义SQL函数
在./src/ports/postgres/modules/hello_world文件夹下创建avg_var.sql_in文件,在这个文件中,定义了用于计算均值和方差的聚合函数和其他辅助函数。这些函数将在单独的C++文件中实现,将在下一节中对其进行描述。
在avg_var.sql_in文件的初始部分,必需利用命令行 m4_include('SQLCommon.m4') 运行m4 宏处理器(m4 macro processor)。利用M4在SQL定义中添加平台专属的命令,并在将MADlib部署到数据库时运行。
利用内置的PostgreSQL 命令CREATE AGGREGATE 定义聚合函数avg_var。

同时定义传递给CREATE AGGREGATE的参数:
SFUNC
为每个输入行调用的状态转换函数命名。在这个例子中,状态转换函数avg_var_transition,与avg_var.sql_in在同一个文件定义,之后在C++中得以实现。
FINALFUNC
在遍历所有输入行之后,调用最终函数的名称来计算聚合结果。例如:最终函数, avg_v ar_final, 与avg_var.sql_in在同一个文件定义,之后在C++中得以实现。
PREFUNC
在遍历每个数据段或分区之后,调用合并函数以合并聚合状态值的名称。Greenplum和HAWQ上的分布式数据集需要合并函数。对于PostgreSQL而言,数据不是分布式的,合并函数并非必需。为了完整起见,我们在本指南中实现了一个名为 avg_var_merge_states的合并函数。
INITCOND
状态值的初始条件。在本例中,利用一个全零双数组,分别对应于平均值、方差和行数。
最终函数的遍历和合并,在与avg_var.sql_in同一个文件中作为聚合函数定义。有关这些函数的更多详细信息可以在 PostgreSQL文档中找到。
在C++中实现函数
在文件夹 /src/modules/hello\u world下创建头文件和源文件 avg_ar.hpp和 avg_ar.cpp。在头文件中利用宏DECLARE_UDF(MODULE, NAME)申明最终函数的遍历和合并。例如,转换函数 avg_var_transi tion声明为 DECLARE_UDF(hello_world,avg_var_transition)。在./src/ports/postgres/dbconnector 文件夹下的dbconnector.hpp 文件里定义DECLARE_UDF宏。
在hood下,三个UDF均申明为 dbconnector::postgres::UDF的子类。这些UDF的行为完全由其成员函数决定。
换句话说,只需要在 avg_ar.cpp文件中实现以下方法:

这里, AnyType类既用于从DBMS传递数据到C++函数,又将返回C++的值。
有关更多详细信息,, 请参阅头文件 TypeTraits _impl.hpp。
转移函数:
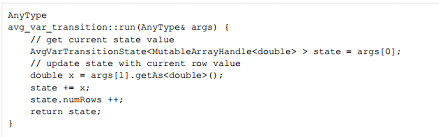
avg_var_transition, 有两个参数,在 avg_var.sql_in中进行定义。第一个是SQL double类型的数组,对应于当前遍历的平均值、方差和行数,第二个是表示当前元组值的double类型。
稍后将描述 class AvgVarTransitionState。基本上,它采用了args[0],SQL双精度数组,将数据传递给适当的C++类型,并将它们存储在state实例中。
通过在AvgVarTransitionState类中加载+= 操作符来在线计算均值和方差。
合并函数

此外: AnyType& args中包含的参数,在avg_var.sql_in 中进行定义。
详细信息隐含于AvgVarTransitionState 的方法中。
最终函数
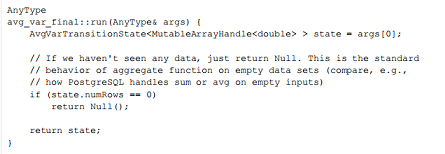
AvgVarTransitionState类加载AnyType() 运算符后可以直接返回状态,AvgVarTransition State 的示例返回AnyType.
桥接类
Below are the methods that overload the operator +=for the bridging class AvgVarTransitionState:
通过下述方法为桥接类AvgVarTransitionState: 加载运算符+=
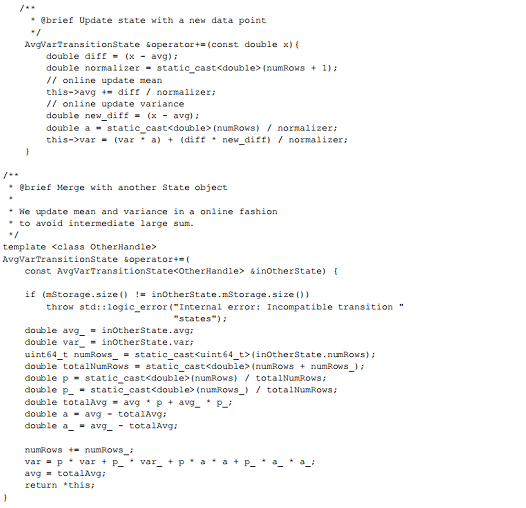
给定两个数据集的均值、方差和大小,利用Welford方法计算两个数据集组合的均值和方差。
注册C++头文件
在 avg_var.sql_in中定义的SQL函数需要能够从C++文件中找到实际的实现。这只需在 /src/modules/目录下的declarations.hpp文件中添加以下行即可完成
运行新模块
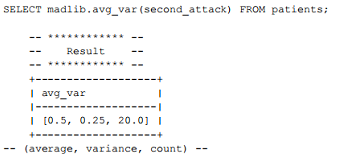
利用新模块运行一个示例。首先,根据 安装指南中的说明重建并重新安装MADLib,并使用MADlib快速入门指南中的 pati ents数据集进行测试。从 psql终端来看,20名患者中有一半在1年内发生过第二次心脏病发作(yes=1):
示例:添加一个迭代UDF
在这里,将演示一个稍微复杂一点的示例,该示例要求迭代调用UDA。这种情况经常出现在许多机器学习模块中,在这些模块中,底层优化算法向目标函数的优化方向迭代。在这个例子中,实现了一个简单的对数回归解算器作为迭代UDF。特别是,用户可以在 psql中键入以下命令来训练逻辑回归分类器:

结果如下:
这里的数据存储在一个名为 patients的SQL表中。logistic回归的目标是second_attack列,特征是treatment列和trait_anxiety列。数组中的 1项表示模型中的附加偏移项。
将解算器添加到上面创建的 hello_world模块中。主要步骤如下:

与上一小节中介绍的步骤相比,这里无须修改 Modules.yml文件,因为我们没有创建新模块。另外一点与上一小节的区别是除.sql_in 文件之外,还创建了一个附加的python文件.py_in.,在此文件中实现绝大多数对数迭代。
此练习的文件可以在源代码存储库的 hello world文件夹中找到。注意:该文件夹中不包括__init__.py_in文件。
1.概述
整个逻辑分为三个部分。在simple_logistic.sql_in 中定义了全部的UDF 和UDA。转换、 合并和 最终函数在C++中实现。这些函数共同构成了一个称为 logreg_simple_step的UDA,它从当前状态下进一步来逼近对数回归的目标。最后,在 simple_logistic.py_in中,采用 plpy包在python中实现一个名为 logregr_simple_train的UDF,它迭代调用 logregr_simple_step直到收敛。
注意:在simple_logistic.sql_in 文件中,定义了如下名为logregr_simple_train的SQL 函数:

其中, python function(hello_world,simple_logistic,logreg_simple_train)的实际实现由hello_world模块中的simple_logistic文件的python函数 logreg_simple_train提供,如下所示:
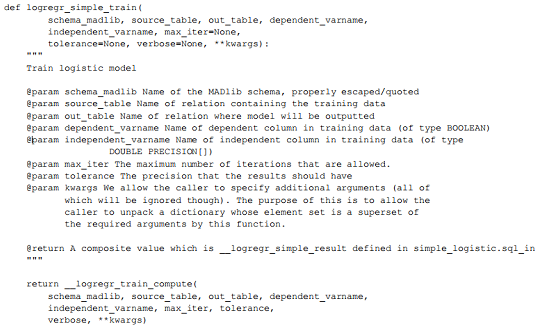
2.plplply中的迭代过程
迭代逻辑使用 PL/Python过程语言实现。在simple_logistic.py_in文件的开始部分,导入一个名为 plpy的Python 模块,利用它来实现数据库的命令。使用 plpy实现迭代逻辑很简单,如下所示:

logregr_simple_step是在 simple_logistic.sql_in文件中定义的UDA,利用/src/modules/hello_world. 目录下的C++文件实现实现转换合并等功能。
__logregr_simple_step 有三个参数,分别为:目标,特征和先前状态。
.状态初始化为 None,在SQL中通过 plpy解释为 null值。
更为复杂的对数回归迭代方案还将包括最优性验证和收敛保证过程,为了简单起见,这里特意忽略这些过程。
有关对数回归的生产级实现,请参阅regress模块。
3.运行新的迭代模块
下面的示例演示了在前面使用的名为patients表上使用 madlib.logreg_simple_train的方法。经过训练的分类模型存储在名为 logreg_mdl的表中,可以使用标准SQL查询查看。
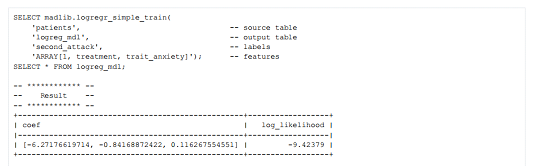
结语
在本文中,介绍了的基本架构,工作原理及特性,并为开发人员快速入门提供了指南,文中详细描述了添加一个迭代UDF 的详细步骤,希望对大家入门有所帮助。