
监控的自我修养,过去十年和未来十年

{metric: load.1min,endpoint: open-falcon-host,tags: srv=falcon,idc=aws-sgp,group=az1,value: 1.5,timestamp: `date +%s`,counterType: GAUGE,step: 60}
1、infra 层面监控数据比重变小,app 层面监控数据比重快速增加
2、监控产品的使用对象发生了变化,从专职运维人员拓展到人数众多的研发和运营群体
3、监控数据的采集原则发生了变化,应用对自身运行状态的自描述成为主流,数据应收尽收,治理前置成为指导原则
4、监控数据模型的维度变得更丰富
5、Metrics 的生命周期变得更短
6、针对监控数据的 Ad Hoc 查询需求变大
7、Metrics 与 Logs、Traces 的相互打通以及建立关联关系重要性凸显
8、基于数据而高于数据的 Insight & Knowledge 成为评价监控产品的能力标准之一
9、OaC / API-Driven 获得开发者青睐
10、监控系统本身也要云原生:)
如果您对 Prometheus、Alertmanager、Grafana 等多个系统的割裂和上手难有怨言; 如果您对通过修改配置文件来管理 Prometheus、Alertmanager 的方式有痛点; 如果您对因为数据量过大而无法扩展您的 Prometheus 感到有困扰; 如果您在生产环境运行多套 Prometheus 集群面临管理和使用上的不便; 如果您在企业数字化转型过程中对于如何架构适合您的云原生监控方案有困惑;
好用和实用的开源告警功能和事件中心;原生内置 dashboard、故障自愈、Resource管理功能;支持多 Prometheus 数据源管理;支持 Prometheus、M3DB、VictoriaMetrics、Influxdb 多种时序库;原生支持 PromQL;原生支持 Exporter 数据采集;支持 Telegraf 做监控数据采集;原生支持 Grafana;
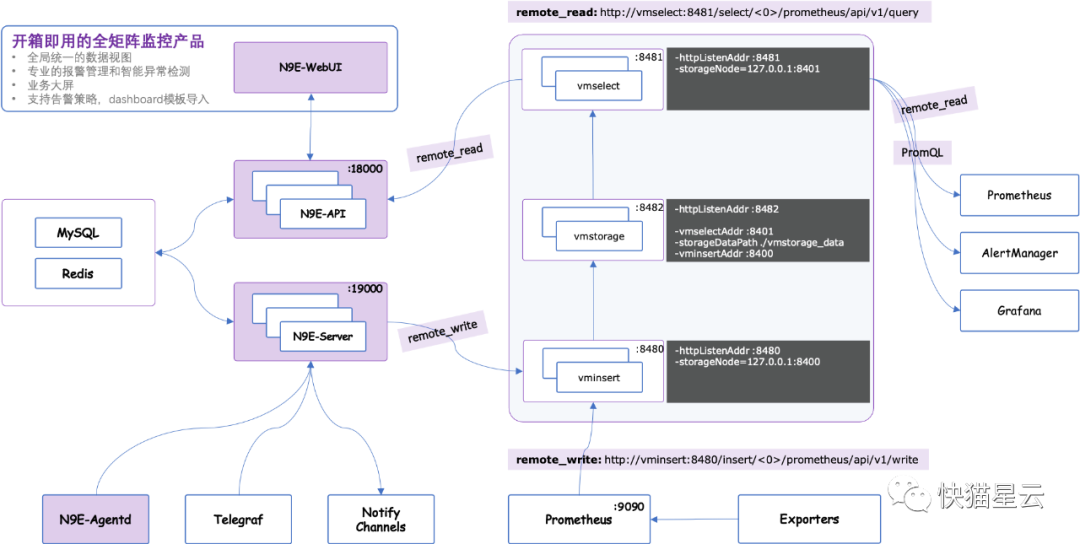
关于Nightingale:企业级云原生开源监控系统。重点聚焦在云原生场景,在 Prometheus 的生态基础上,重点加强其企业级特性提升、产品化的创新以及解决方案的落地(https://github.com/didi/nightingale)。
想要了解更多 Go 语言相关信息,欢迎关注 「GoCN 社区」 获取每日精彩内容,也可加入群聊和我们一起体验 Go语言的乐趣吧~
评论