
Spark性能调优指北:性能优化和故障处理
一、Spark 性能优化
生产环境 Spark submit 脚本
\--class com.atguigu.spark.WordCount \--num-executors 80 \--driver-memory 6g \--executor-memory 6g \--executor-cores 3 \--master yarn \--deploy-mode cluster \--queue root.default \--conf spark.yarn.executor.memoryOverhead=2048 \--conf spark.core.connection.ack.wait.timeout=300 \/usr/local/spark/spark.jar

RDD 优化
RDD 复用,避免相同的算子和计算逻辑之下对 RDD 进行重复的计算
RDD 持久化,对多次使用的 RDD 进行持久化,将 RDD 缓存到内存/磁盘中,之后对于 该RDD 的计算都会从内存/磁盘中直接获取。
RRD 尽可能早的进行 filter 操作。
并行调节
Spark 官方推荐,Task 数量应该设置为 Spark 作业总 CPU core 数量的 2~3 倍。
val conf = new SparkConf().set("spark.default.parallelism", "500")广播大变量
Task 中的算子中如果使用了外部的变量,每个 Task 都会缓存这个变量的副本,造成了内存的极大消耗。而广播变量在可以在每个 Executor 中保存一个副本,此 Executor 的所有 Task 共用此广播变量,这让变量产生的副本数量大大减少。
广播变量起初在 Driver 中,Task 在运行时会首先在自己本地的 Executor 上的 BlockManager 中尝试获取变量,如果本地没有,BlockManager 会从 Driver 中远程拉取变量的副本,之后 Executor 的所有 Task 都会直接从 BlockManager 中获取变量。
Kryo 序列化
Spark 默认使用 Java 的序列化机制。而 Kryo 序列化机制比 Java 序列化机制性能提高10倍左右,但 Kryo 序列化不支持所有对象的序列化,并且需要用户在使用前注册需要序列化的类型,不够方便,但从 Spark 2.0.0 版本开始,简单类型、简单类型数组、字符串类型的Shuffling RDDs 已经默认使用 Kryo 序列化方式了。
public class MyKryoRegistrator implements KryoRegistrator{@Overridepublic void registerClasses(Kryo kryo){kryo.register(StartupReportLogs.class);}}//创建SparkConf对象val conf = new SparkConf().setMaster(…).setAppName(…)//使用Kryo序列化库,如果要使用Java序列化库,需要把该行屏蔽掉conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");//在Kryo序列化库中注册自定义的类集合,如果要使用Java序列化库,需要把该行屏蔽掉conf.set("spark.kryo.registrator", "atguigu.com.MyKryoRegistrator");
调节本地化等待时间
网络传输会严重影响性能,所以可以设置调节本地化等待的时间,若等待某个时长后,目标节点处理完了一部分 Task,当前的 Task 将有机会得到执行。
Spark本地化等级

在 Spark 项目开发阶段,可以使用 client 模式对程序进行测试,此时,可以在本地看到比较全的日志信息,日志信息中有明确的 Task 数据本地化的级别,如果大部分都是 PROCESS_LOCAL,那么就无需进行调节,但是如果发现很多的级别都是 NODE_LOCAL、ANY,那么需要对本地化的等待时长进行调节,通过延长本地化等待时长,看看 Task 的本地化级别有没有提升,并观察 Spark 作业的运行时间有没有缩短。注意,过犹不及,不要将本地化等待时长延长地过长,导致因为大量的等待时长,使得 Spark 作业的运行时间反而增加了。
val conf = new SparkConf().set("spark.locality.wait", "6")1.2 算子调优
mapPatitions
普通的 map 算子对 RDD 中的每一个元素进行操作,而 mapPartitions 算子对 RDD 中每一个分区进行操作。
比如,当要把 RDD 中的所有数据通过 JDBC 写入数据,如果使用 map 算子,那么需要对 RDD 中的每一个元素都创建一个数据库连接,这样对资源的消耗很大,如果使用mapPartitions算子,那么针对一个分区的数据,只需要建立一个数据库连接。
缺点:普通 map 算子,可以将已处理完的数据及时的回收掉,但使用 mapPartitions 算子,当数据量非常大时,function 一次处理一个分区的数据,如果一旦内存不足,此时无法回收内存,就可能会 OOM,即内存溢出。在项目中,应该首先估算一下 RDD 的数据量、每个 partition 的数据量,以及分配给每个 Executor 的内存资源,如果资源允许,可以考虑使用 mapPartitions 算子代替 map。
foreachPartition 优化数据库操作
在生产环境中,通常使用 foreachPartition 算子来完成数据库的写入,通过 foreachPartition 算子的特性,可以优化写数据库的性能。
foreachPartition 算子 与 mapPartitions 算子类似,如果一个分区的数据量特别大,可能会造成OOM,即内存溢出。
filter 与 coalsce 的配合使用
使用 filter 算子完成 RDD 中数据的过滤,但是 filter 过滤后,每个分区的数据量有可能会存在较大差异,造成数据倾。此时使用 coalesce 算子,压缩分区数量,而且让每个分区的数据量尽量均匀紧凑,便于后面的 Task 进行计算操作。
repartition 与 coalesce 都可以用来进行重分区,其中 repartition 只是 coalesce 接口中 shuffle 为 true 的简易实现,coalesce 默认情况下不进行 shuffle,但是可以通过参数进行设置。
repartition 解决 SparkSQL 低并行度问题
并行度的设置对于 Spark SQL 是不生效的,用户设置的并行度只对于 Spark SQL 以外的所有 Spark 的 stage 生效。Spark SQL 自己会默认根据 hive 表对应的 HDFS 文件的 split 个数自动设置 Spark SQL 所在的那个 stage 的并行度,Spark SQL自动设置的 Task 数量很少。
Spark SQL 查询出来的 RDD,立即使用 repartition 算子重新分区为多个 partition,从 repartition 之后的 RDD 操 作的并行度就会提高。
reduceByKey 预聚合
reduceByKey 相较于普通的 shuffle 操作一个显著的特点就是会进行 map 端的本地聚合,map 端会先对本地的数据进行 combine 操作。故我们可以考虑使用 reduceByKey 代替其他的 Shuffle 算子,比如 groupByKey。
reduceByKey 对性能的提升如下:1. 本地聚合后,在 map 端的数据量变少,减少了磁盘IO;2. 本地聚合后,下一个 stage 拉取的数据量变少,减少了网络传输的数据量;3. 本地聚合后,在 reduce 端进行数据缓存的内存占用减少;4. 本地聚合后,在 reduce 端进行聚合的数据量减少。
1.3 JVM 调优
对于 JVM 调优,首先应该明确,full gc/minor gc,都会导致 JVM 的工作线程停止工作,即 stop the world。
降低 cache 操作的内存占比
静态内存管理
在 Spark UI 中可以查看每个 stage 的运行情况,包括每个 Task 的运行时间、gc 时间等等,如果发现 gc 太频繁,时间太长,可以考虑调节 Storage 的内存占比,让 Task 执行算子函数式,有更多的内存可以使用。Storage 内存区域可以通过 spark.storage.memoryFraction 参数进行指定,默认为0.6,即60%,可以逐级向下递减。
val conf = new SparkConf().set("spark.storage.memoryFraction", "0.4")统一内存管理
Storage 主要用于缓存数据,Execution 主要用于缓存在 shuffle 过程中产生的中间数据,两者所组成的内存部分称为统一内存,Storage和Execution各占统一内存的50%,由于动态占用机制的实现,shuffle 过程需要的内存过大时,会自动占用 Storage 的内存区域,因此无需手动进行调节。
调节 Executor 堆外内存
有时 Spark 作业处理的数据量非常大,达到几亿的数据量,此时运行 Spark 作业会时不时地报错,例如 shuffle output file cannot find,executor lost,task lost,out of memory 等,这可能是 Executor 的堆外内存不太够用,导致 Executor 在运行的过程中内存溢出。
默认情况下,Executor 堆外内存上限大概为 300MB,在实际的生产环境下,对海量数据进行处理的时候,这里都会出现问题,导致 Spark 作业反复崩溃,无法运行,此时就会去调节这个参数,到至少1G,甚至于2G、4G。
# Executor 堆外内存的配置需要在 spark-submit 脚本里配置。--conf spark.yarn.executor.memoryOverhead=2048
调节连接等待时长
遇到 file not found、file lost 这类错误,在这种情况下,很有可能是 Executor 的 BlockManager 在拉取数据的时候,无法建立连接,然后超过默认的连接等待时长 60s 后,宣告数据拉取失败,如果反复尝试都拉取不到数据,可能会导致 Spark 作业的崩溃。此时调节连接的等待时长,通常可以避免部分的XX文件拉取失败、XX文件 lost 等报错。
# 连接等待时长需要在 spark-submit 脚本中进行设置。--conf spark.core.connection.ack.wait.timeout=300
数据倾斜的表现:
Spark 作业的大部分 task 都执行迅速,只有有限的几个task执行的非常慢,此时可能出现了数据倾斜,作业可以运行,但是运行得非常慢;
Spark 作业的大部分task都执行迅速,但是有的task在运行过程中会突然报出OOM,反复执行几次都在某一个task报出OOM错误,此时可能出现了数据倾斜,作业无法正常运行。
定位数据倾斜问题:
查阅代码中的 shuffle 算子,例如 reduceByKey、countByKey、groupByKey、join等算子,根据代码逻辑判断此处是否会出现数据倾斜;
查看 Spark 作业的 log 文件,log 文件对于错误的记录会精确到代码的某一行,可以根据异常定位到的代码位置来明确错误发生在第几个stage,对应的 shuffle 算子是哪一个;
2.1 Shuffle 调优
调节 map 端缓冲区大小
通过调节 map 端缓冲的大小,可以避免频繁的磁盘 IO 操作。map 端缓冲的默认配置是32KB,如果每个 Task 处理640KB 的数据,那么会发生 640/32 = 20次溢写,这对于性能的影响是非常严重的。map 端缓冲区的大小可以通过 spark.shuffle.file.buffer 参数进行设置定。
val conf = new SparkConf().set("spark.shuffle.file.buffer", "64")调节 reduce 端拉取数据缓冲区大小
适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数。reduce 端数据拉取缓冲区的大小可以通过 spark.reducer.maxSizeInFlight 参数进行设置,默认为 48MB。
val conf = new SparkConf().set("spark.reducer.maxSizeInFlight", "96")调节 reduce 端拉取数据重试次数
reduce task 拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试。对于那些包含了特别耗时的 shuffle 操作的作业,建议增加重试最大次数(比如60次),调节该参数可以大幅度提升稳定性。reduce 端拉取数据重试次数可以通过 spark.shuffle.io.maxRetries 参数进行设置,默认为 3 次。
val conf = new SparkConf().set("spark.shuffle.io.maxRetries", "6")调节 reduce 端拉取数据等待间隔
reduce 端拉取数据等待间隔可以通过 spark.shuffle.io.retryWait 参数进行设置,默认值为5s
val conf = new SparkConf().set("spark.shuffle.io.retryWait", "60s")调节 SortShuffle 排序操作阈值
对于 SortShuffleManager,如果 shuffle reduce task 的数量小于某一阈值则 shuffle write 过程中不会进行排序操作,而是直接按照未经优化的 HashShuffleManager 的方式去写数据。
当使用 SortShuffleManager 时,如果的确不需要排序操作,建议将这个参数调大一些,大于 shuffle read task 的数量,此时 map-side 就不会进行排序,减少了排序的性能开销,但是这种方式下,依然会产生大量的磁盘文件,因此 shuffle write 性能有待提高。排序操作阈值可以通过 spark.shuffle.sort. bypassMergeThreshold 参数进行设置,默认值为200。
val conf = new SparkConf().set("spark.shuffle.sort.bypassMergeThreshold", "400")2.2 聚合原数据
避免 shuffle 过程
为了避免数据倾斜,可以考虑避免 shuffle 过程,如果避免了shuffle过程,就从根本上消除了数据倾斜问题的可能。
如果 Spark 作业的数据来源于 Hive 表,那么可以先在 Hive 表中对数据进行聚合,例如按照 key 进行分组,将同一key 对应的所有 value 用一种特殊的格式拼接到一个字符串里去,这样一个 key 就只有一条数据了;之后对一个 key 的所有 value 进行处理时,只需要进行 map 操作即可,无需再进行任何的 shuffle 操作。通过上述方式就避免了执行 shuffle 操作,也就不可能会发生任何的数据倾斜问题。
对于 Hive 表中数据的操作,不一定是拼接成一个字符串,也可以是直接对 key 的每一条数据进行累计计算。
改变 Key 的粒度
在具体的场景下,可以考虑扩大或缩小 key 的聚合粒度,可以减轻数据倾斜的现象。
例如,目前有10万条用户数据,当前 key 的粒度是(省,城市,区,日期),现在我们考虑扩大粒度,将 key 的粒度扩大为(省,城市,日期),这样 key 的数量会减少,key 之间的数据量差异也有可能会减少。
过滤导致倾斜的 key
在 Spark 作业过程中出现的异常数据,比如 null 值,将可能导致数据倾斜,此时滤除可能导致数据倾斜的 key 对应的数据,这样就不会发生数据倾斜了。
提高 shuffle 操作中的 reduce 并行度
增加 reduce 端并行度可以增加 reduce 端 Task 的数量,每个 Task 分配到的数据量就会相应减少,从而缓解数据倾斜。
reduce 端并行度的设置
部分 shuffle 算子中可以传入并行度的设置参数,比如 reduceByKey(500),这个参数会决定 shuffle 过程中 reduce端的并行度。
对于 group by、join 等算子,需要设置参数 spark.sql.shuffle.partitions,该参数代表 shuffle read task 的并行度,默认是200,对于很多场景来说都有点过小。
reduce 端并行度设置存在的缺陷
提高 reduce 端并行度并没有从根本上改变数据倾斜的本质和问题,只是尽可能地去缓解和减轻 shuffle reduce task 的数据压力,以及数据倾斜的问题,适用于有较多 key 对应的数据量都比较大的情况。
比如,某个 key 对应的数据量有100万,那么无论你的 Task 数量增加到多少,这个对应着100万数据的 key 肯定还是会分配到一个 Task 中去处理。
使用随机 key 实现双重聚合
当使用类似 groupByKey、reduceByKey 这样的算子时,可以考虑使用随机 key 实现双重聚合。
首先,通过 map 算子给每个数据的 key 添加随机数前缀,对 key 进行打散,将原先一样的 key 变成不一样的 key,然后进行第一次聚合,这样就可以让原本被一个 Task 处理的数据分散到多个 Task 上去做局部聚合;随后,去除掉每个 key 的前缀,再次进行聚合。
此方法对于由 groupByKey、reduceByKey 这类算子造成的数据倾斜有比较好的效果。如果是 join 类的 shuffle 操作,还得用其他的解决方案。
将 reduce join 转换为 map join
正常情况下 join 操作会执行 shuffle 过程,并且执行的是 reduce join,先将所有相同的 key 和对应的 value 汇聚到一个 reduce task 中,然后再进行 join。
但是如果一个 RDD 是比较小的,则可以 采用广播小RDD全量数据+map算子 来实现与 join 同样的效果,也就是 map join,此时就不会发生 shuffle 操作,也就不会发生数据倾斜。
注意:RDD 是并不能进行广播的,只能将 RDD 内部的数据通过 collect 拉取到 Driver 内存然后再进行广播。并且如果将一个数据量比较大的 RDD 做成广播变量,那么很有可能会造成内存溢出。
sample 采样对倾斜 key 单独进行 join
如果某个 RDD 只有一个 key,在 shuffle 过程中会默认将此 key 对应的数据打散,由不同的 reduce 端 task 处理。
所以, 当由单个 key 导致数据倾斜时,可有将发生数据倾斜的 key 单独提取出来,组成一个 RDD,然后用这个原本会导致倾斜的 key 组成的 RDD 跟其他 RDD 单独 join,此时,根据 Spark 的运行机制,此 RDD 中的数据会在 shuffle 阶段被分散到多个 Task 中去进行 join 操作。
对于 RDD 中的数据,可以将其转换为一个中间表,或者使用 countByKey() 的方式,查看这个 RDD 中各个 key 对应的数据量,此时如果你发现整个 RDD 就一个 key 的数据量特别多,那么就可以考虑使用这种方法。
当数据量非常大时,可以考虑使用 sample 采样获取 10% 的数据,然后分析这 10% 的数据中哪个 key 可能会导致数据倾斜,然后将这个 key 对应的数据单独提取出来。
如果一个 RDD 中导致数据倾斜的 key 很多,那么此方案不适用。
使用随机数以及扩容进行 join
如果在进行 join 操作时,RDD 中有大量的 key 导致数据倾斜,那么进行分拆 key 也没什么意义,此时就可以使用扩容的方式来解决。
选择一个 RDD,使用 flatMap 进行扩容,对每条数据的 key 添加数值前缀(1~N的数值),将一条数据映射为多条数据(扩容);选择另外一个RDD,进行 map 映射操作,每条数据的 key 都打上一个随机数作为前缀(1~N的随机数)(稀释)。
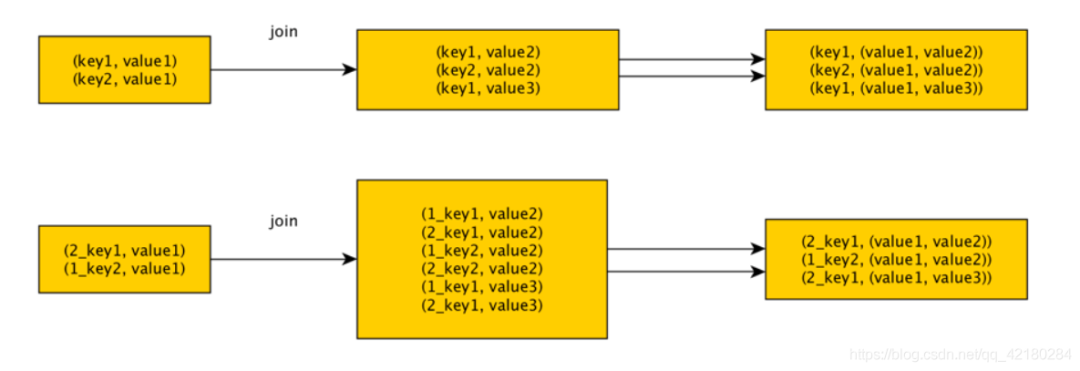
缺点:如果两个 RDD 都很大,那么将 RDD 进行 N倍 的扩容显然行不通;使用扩容的方式只能缓解数据倾斜,不能彻底解决数据倾斜问题。
控制 reduce 端缓冲大小以避免 OOM
在 Shuffle 过程,reduce 端 Task 并不是等到 map 端 Task 将其数据全部写入磁盘后再去拉取,而是 map 端写一点数据,reduce 端 Task 就会拉取一小部分数据。
增大 reduce 端缓冲区大小可以减少拉取次数,提升 shuffle 性能。
但是有时 map 端的数据量非常大,写出的速度非常快,此时 reduce 端的所有 Task 都在拉取数据,且全部达到缓冲的最大值,即 48MB,再加上 reduce 端执行的聚合函数的代码,会创建大量的对象,这可能导致内存溢出,即OOM。
一旦出现 reduce 端内存溢出的问题,可以考虑减小 reduce 端拉取数据缓冲区的大小,例如减少为 12MB。这是典型的以性能换时间的原理。reduce 端拉取数据的缓冲区减小,不容易导致OOM,但是相应的 reudce 端的拉取次数增加,造成更多的网络传输开销,造成性能的下降。在开发中还是要保证任务能够运行,再考虑性能的优化。
JVM GC 导致的 shuffle 文件拉取失败
在 Shuffle 过程中,后面 stage 的 Task 想要去上一个 stage 的 Task 所在的 Executor 拉取数据,结果对方正在执行GC。BlockManager、netty 的网络通信都会停止工作,就会导致报错 shuffle file not found,但是第二次再次执行就不会再出现这种错误。
所以,通过调整 reduce 端拉取数据重试次数和 reduce 端拉取数据时间间隔这两个参数来对 Shuffle 性能进行调整,增大参数值,使得 reduce 端拉取数据的重试次数增加,并且每次失败后等待的时间间隔加长。
val conf = new SparkConf().set("spark.shuffle.io.maxRetries", "60").set("spark.shuffle.io.retryWait", "60s")
解决各种序列化导致的报错
当报错信息中含有 Serializable 等类似词汇,那么可能是序列化问题导致的报错。
序列化问题要注意以下三点:
作为RDD的元素类型的自定义类,必须是可以序列化的;
算子函数里可以使用的外部的自定义变量,必须是可以序列化的;
不可以在RDD的元素类型、算子函数里使用第三方的不支持序列化的类型,例如 Connection。
解决算子函数返回 NULL 导致的问题
一些算子函数里,需要有返回值,但是在一些情况下我们不希望有返回值,此时我们如果直接返回 NULL,会报错,例如Scala.Math(NULL)异常。
可以通过下述方式解决:
返回特殊值,不返回NULL,例如“-1”;
在通过算子获取到了一个 RDD 之后,可以对这个 RDD 执行 filter 操作,进行数据过滤,将数值为 -1 的过滤掉;
在使用完 filter 算子后,继续调用 coalesce 算子进行优化。
解决 YARN-CLIENT 模式导致的网卡流量激增问题
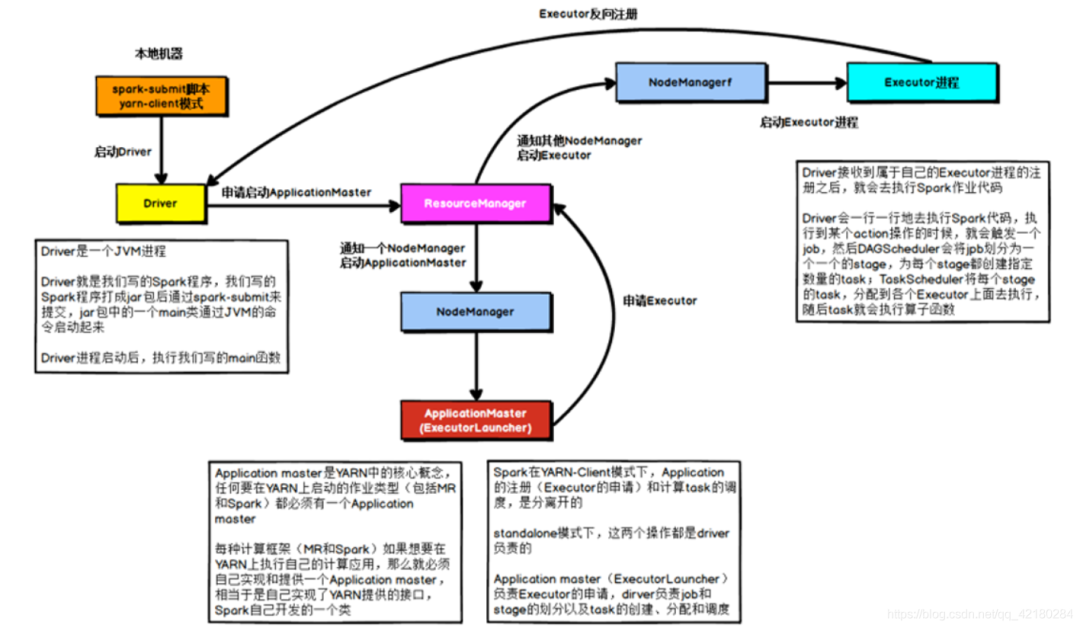
假设有100个Executor, 1000个task,那么每个Executor分配到10个task,之后,Driver要频繁地跟Executor上运行的1000个task进行通信,通信数据非常多,并且通信品类特别高。这就导致有可能在Spark任务运行过程中,由于频繁大量的网络通讯,本地机器的网卡流量会激增。
YARN-client 模式只会在测试环境中使用, YARN-client模式可以看到详细全面的 log 信息,通过查看 log,可以锁定程序中存在的问题,避免在生产环境下发生故障。
生产环境下,使用的是 YARN-cluster 模式。在 YARN-cluster 模式下,就不会造成本地机器网卡流量激增问题,如果 YARN-cluster 模式下存在网络通信的问题,需要运维团队进行解决。
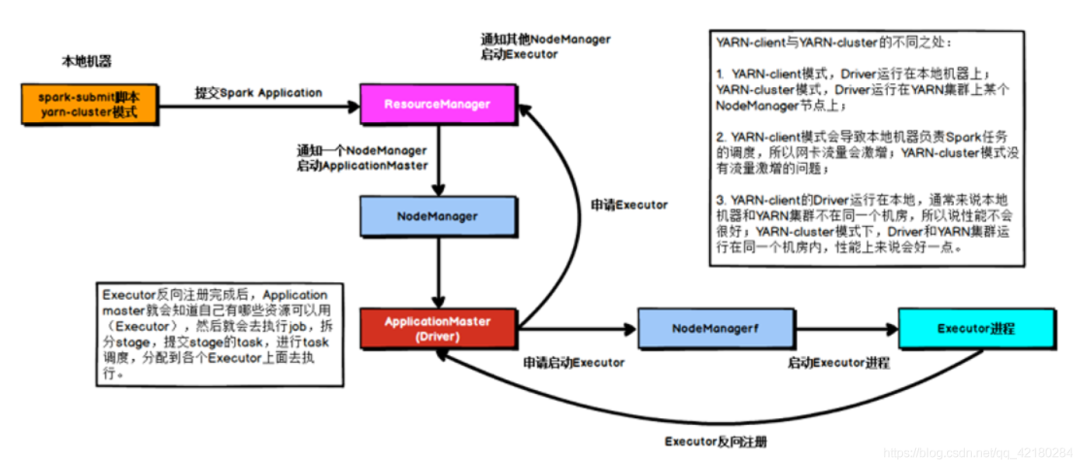
YARN-client 模式下,Driver 是运行在本地机器上的,Spark 使用的 JVM 的 PermGen 的配置,是本地机器上的 spark-class 文件,JVM 永久代的大小是 128MB,但是在 YARN-cluster 模式下,Driver 运行在 YARN 集群的某个节点上,使用的是没有经过配置的默认设置,PermGen 永久代大小为 82MB。
SparkSQL 的内部需要进行很复杂的SQL的语义解析、语法树转换等等。如果 sql 语句非常复杂,很有可能会导致性能的损耗和内存的占用,特别是对 PermGen 的占用会比较大。
此时如果 PermGen 的占用好过了 82MB,但是又小于128MB,就会出现 YARN-client 模式下可以运行,YARN-cluster 模式下无法运行的情况。
解决上述问题的方法时增加 PermGenspark-submit:
# 设置 Driver 永久代大小,默认为128MB,最大256MB--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"
解决 SparkSQL 导致的 JVM 栈内存溢出
JVM栈内存溢出基本上就是由于调用的方法层级过多,产生了大量的,非常深的,超出了 JVM 栈深度限制的递归。很可能是 SparkSQL 有大量 or 语句导致的,因为在解析 SQL 时,转换为语法树或者进行执行计划的生成对于 or 的处理是递归的。
建议将一条 sql 语句拆分为多条 sql 语句来执行,每条sql语句尽量保证 100 个以内的子句。
持久化与 checkpoint 的使用
一个 RDD 缓存并 checkpoint 后,如果一旦发现缓存丢失,Spark 会优先查看 checkpoint 数据存不存在,如果有就会使用 checkpoint 数据,而不用重新计算。checkpoint 可以视为 cache 的保障机制,如果 cache 失败,就使用 checkpoint 的数据。
使用 checkpoint 的优点在于提高了 Spark 作业的可靠性,一旦缓存出现问题,不需要重新计算数据,缺点在于, checkpoint 时需要将数据写入 HDFS 等文件系统,对性能的消耗较大。
原文地址:https://blog.csdn.net/qq_42180284/article/details/103945403