
栈和队列
栈(Stack) 栈的应用一:方法的系统调用栈 栈的应用二:前进后退功能 栈的代码实现:分别使用数组和链表实现 队列(Queue) 使用数组实现队列 使用单向链表实现队列 优化单向链表实现的队列 优化数组实现的队列:循环队列
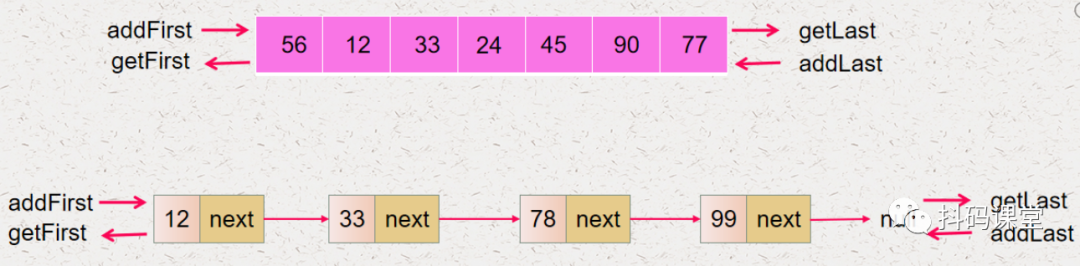

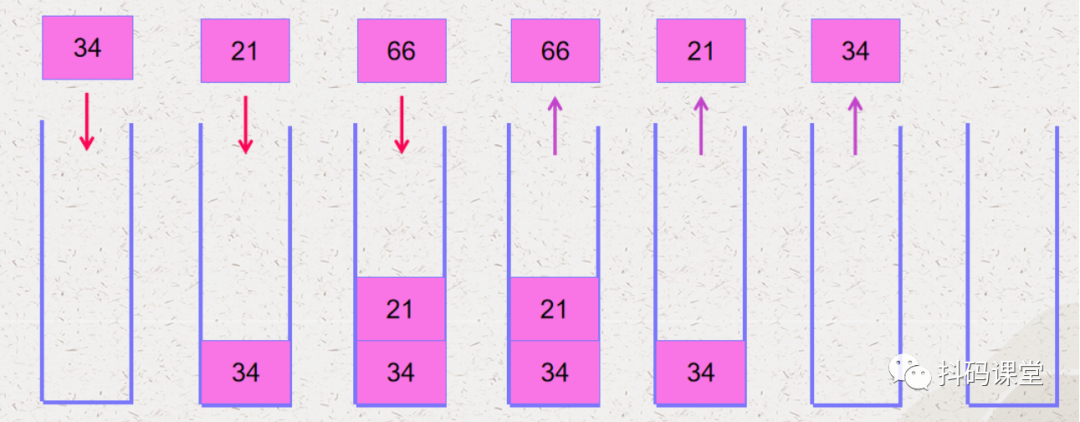
元素进栈的顺序是:34、21、66 元素出栈的顺序是:66、21、34
栈顶:可以操作数据的一端称为栈顶 栈底:不可以操作数据的一端称为栈底
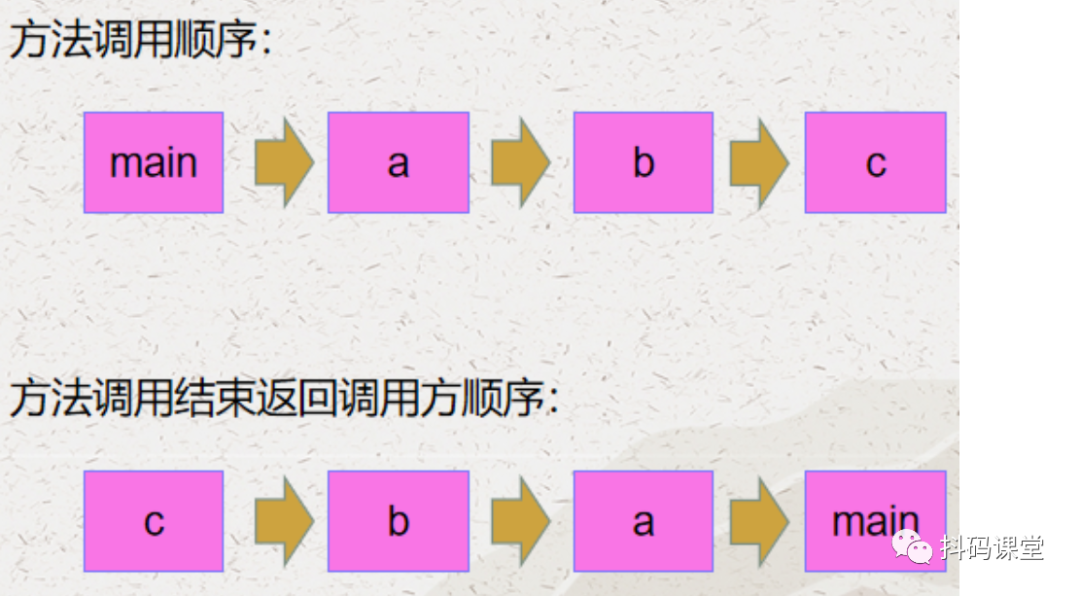
public static void main(String[] args) {a(10);}public static int a(int x) {int y = b(x, 1);return y;}public static int b(int x, int y) {int sum = x + y;c(sum);return sum;}public static void c(int x) {System.out.println(x);}
首先使用栈来记录每一个操作,用户每操作过一次就将操作压入栈中 等用户想返回的时候,只需要将操作出栈即可
当用户需要后退的时候,将第一个栈中的栈顶操作出栈,然后将出栈的操作再次压入到第二个栈中 当用户需要前进的时候,将第二个栈中的栈顶操作出栈,然后将出栈的操作再次压入到第一个栈中
push 操作:向栈中压入元素
pop 操作:从栈中弹出栈顶元素
push 操作:向数组的末尾追加元素,这个操作的时间复杂度是 O(1)
pop 操作:将数组末尾的元素删除掉,注意,这里并不要真的删除末端元素,而是直接将 size-- 即可,这样可以实现常量级别的时间复杂度
在使用单向链表来实现栈的时候,我们只对链表的表头进行操作:
push 操作:向单向链表表头插入元素,这个操作是常量级别的时间复杂度
pop 操作:将单向链表的表头删除,这个操作也是常量级别的时间复杂度
可以看出,不管是使用数组还是单向链表实现栈,push 和 pop 的时间复杂度都是 O(1)
注意:代码实现请见视频讲解
队列 (Queue)
从一端将数据添加到队列中,这个过程我们称为入队 (enqueue) 从另一端将数据从队列中删除,这个过程我们称为出队 (dequeue)

和栈一样,队列可以使用数组、也可以使用链表来实现。
到底使用静态数组还是动态数组,这要看实现的队列是固定容量的还是动态容量的,我们这里先实现一个动态容量的队列,所以使用动态数组来实现 到底使用数组的哪一端作为队首,哪一端作为队尾,我们看下面的分析
入队的操作就是 addFirst,它的时间复杂度是 O(n) 出队的操作就是 removeLast,它的时间复杂度是 O(1)
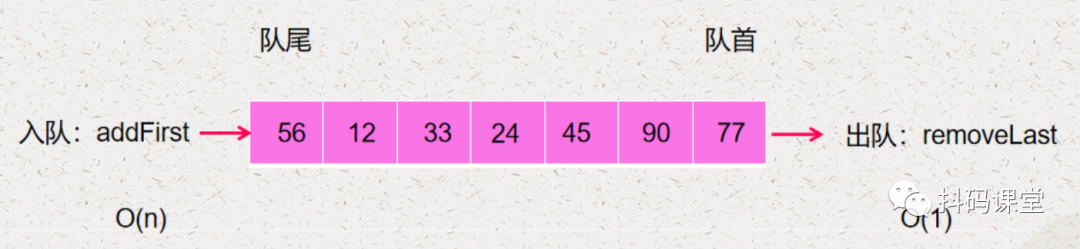
入队的操作就是 addLast,它的时间复杂度是 O(1) 出队的操作就是 removeFirst,它的时间复杂度是 O(n)
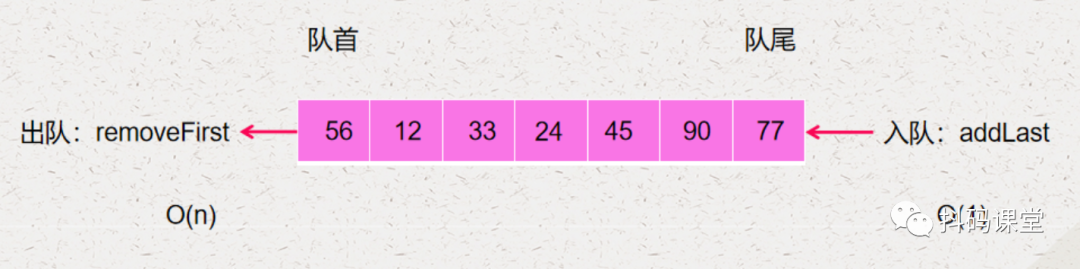
所以说。不管选哪个端作为队首,时间复杂度都是一样的,都会有一个操作是 O(n),一个是 O(1),所以选哪一端作为队首都一样
注意:代码实现请见视频讲解
二、使用单向链表实现队列
入队的操作就是 addFirst,它的时间复杂度是 O(1) 出队的操作就是 removeLast,它的时间复杂度是 O(n)
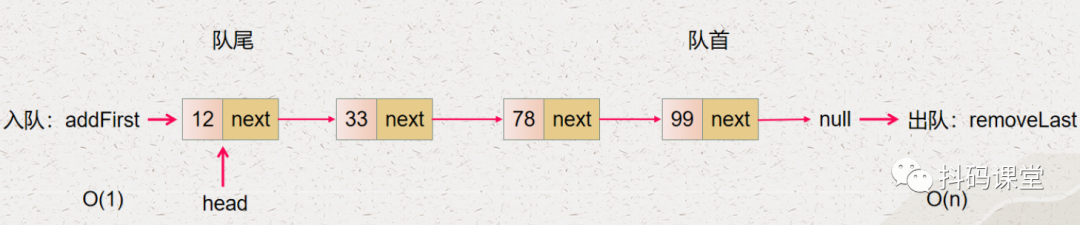
入队的操作就是 addLast,它的时间复杂度是 O(n) 出队的操作就是 removeFirst,它的时间复杂度是 O(1)
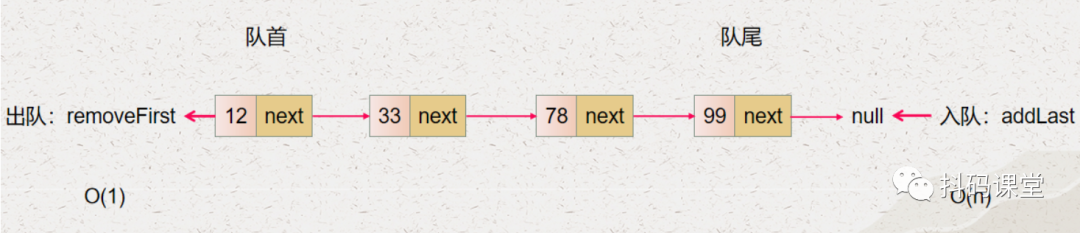
注意:代码实现请见视频讲解
我们使用单向链表实现了队列,不管是以链表的哪一端作为队首,队列中的出队和入队两个操作肯定会有一个操作的时间复杂度是 O(n),我们能不能将这个时间复杂度降为 O(1) 呢?
我们要优化时间复杂度,先要找到导致时间复杂度高的原因,我们先看看下面的两张图:
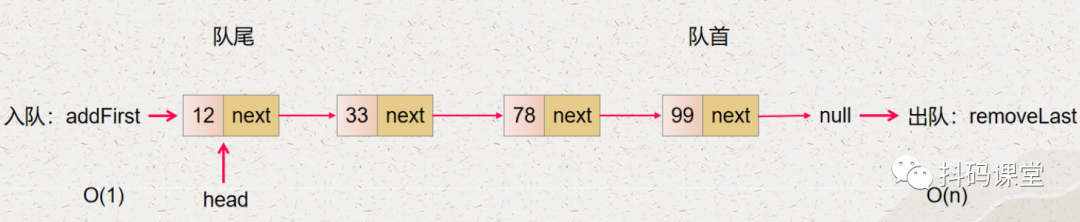
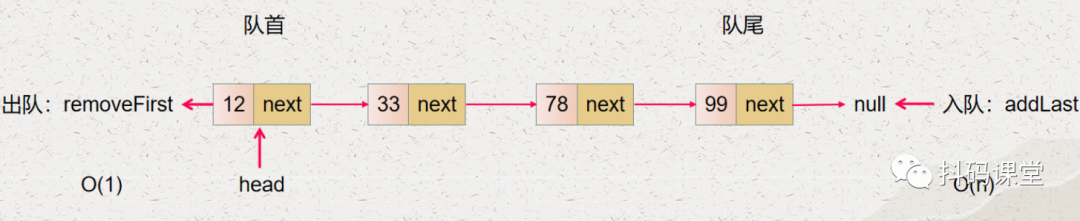
所以,我们要降低单向链表实现的队列出队入队的时间复杂度,那么就要降低对单向链表最后一个节点操作的时间复杂度。
我们现在回想下,为什么对单向链表的头不管是删除还是新增操作的时间复杂度是 O(1) 呢?答案就是我们通过一个变量 head 记住了链表头节点的位置,所以对头的操作的时间复杂度可以为常量级别
借助这个方法,我们也可以使用一个变量 tail 来记住单向链表的尾节点,看看能不能降低对尾节点的操作时间复杂度呢?
removeLast 操作的时间复杂度还是 O(n),之所以时间复杂度没有变化,是因为要删除最后一个节点,就需要找到最后一个节点的前一个节点,然而对于单向链表,要找到最后一个节点的前一个节点需要从头节点开始遍历找到,所以时间复杂度还是 O(n) addLast 操作的时间复杂度变成了 O(1),这个是因为在最后一个节点后面新增一个节点,只需要知道最后一个节点的位置即可,然而我们已经使用 tail 变量记录了最后一个节点的位置了。
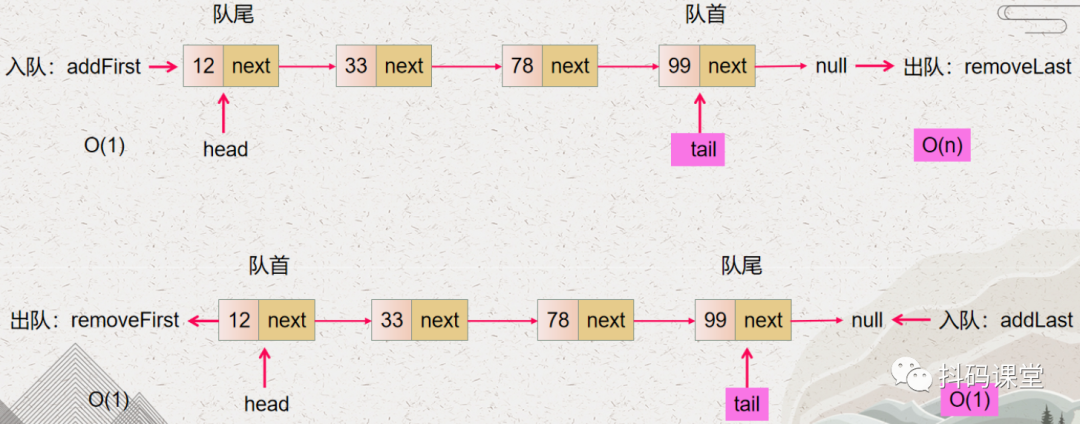
从上图,我们也可以得出一个结论:要使得单向链表实现的队列的出队和入队操作的时间复杂度都是 O(1) 的话,那么必须使用单向链表表头做队首。
以上,我们是使用单向链表 + 表头表尾两个指针来实现队列,而且实现的出队和入队的时间复杂度都是 O(1)
当然,你完全可以使用双向链表来实现队列,这样出队和入队的时间复杂度也是 O(1)
但是直接使用双向链表实现的队列,比使用单向链表 + 表头表尾两个指针实现的队列更加的耗费空间,因为双向链表的每个节点都多了一个前置指针
注意:代码实现请见视频讲解
四、循环队列
前面我们对使用单向链表实现的队列进行了优化,使得出队和入队的时间复杂度都是 O(1)
那么,我们能不能对数组实现的队列也进行优化呢?答案是可以的,那就是接下来要讲解的循环队列了
现在我们就来对前面的数组实现的队列进行优化。
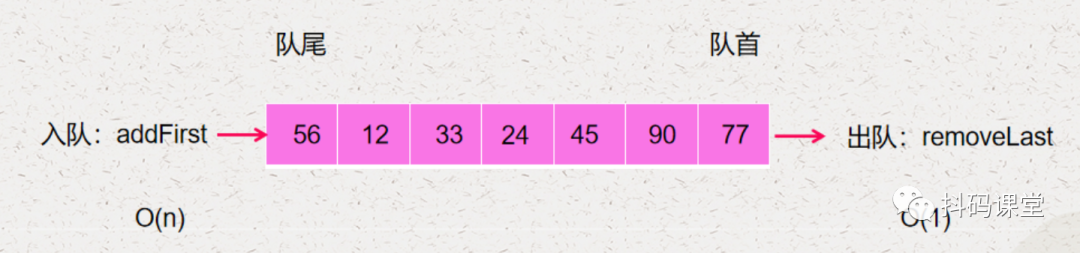

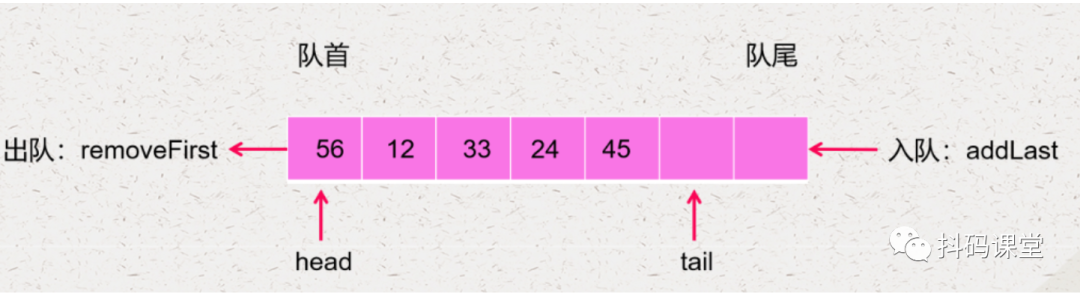
当第一个元素出队了,我们不需要移动剩下的元素,而是直接将 head 往后移动一位,如下:
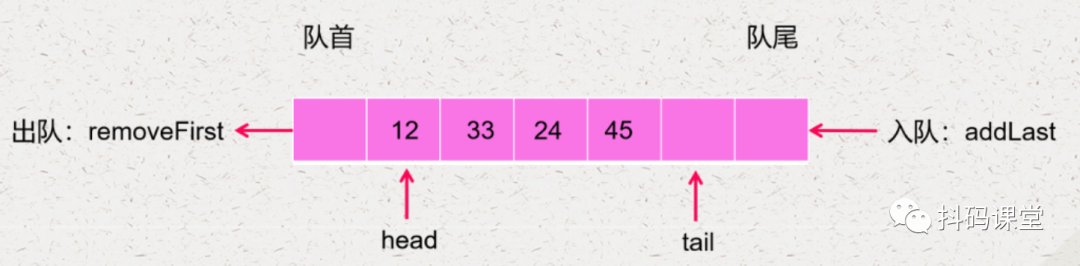
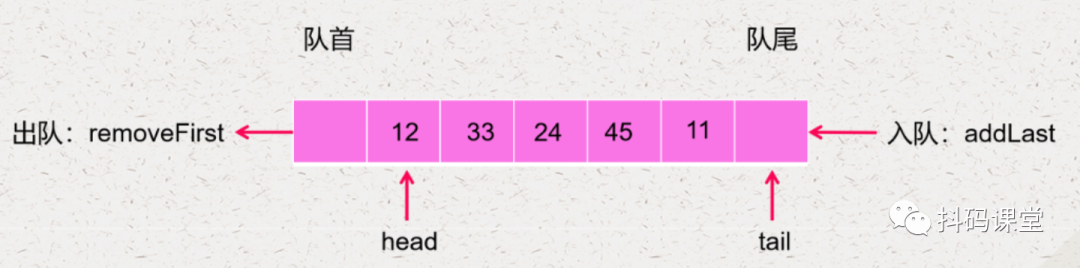
什么时候表示队列为空 什么时候表示队列已经满了

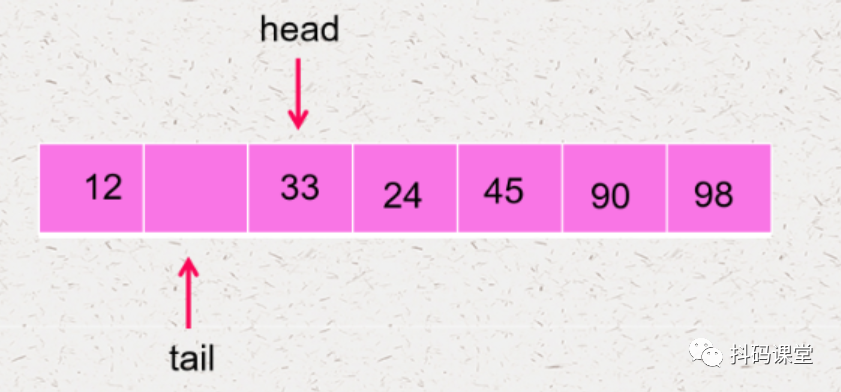
在实现循环队列之前,我们还有一个问题需要解决:head 和 tail 是怎么移动的?每次移动都 +1 吗?这样的话,head 和 tail 肯定会超出数据界限的,我们可以使用取模的手段,将 head 和 tail 控制在数组范围内,如下:
head = (head + 1) % data.lengthtail = (tail + 1) % data.length
注意:代码实现讲解请见视频讲解
package com.douma.line.queue;/*** @微信公众号 : 抖码课堂* @官方微信号 : bigdatatang01* @作者 : 老汤*/public class LoopQueue<E> implements Queue<E> {private E[] data;private int head;private int tail;private int size;public LoopQueue() {this(20);}public LoopQueue(int capacity) {data = (E[])new Object[capacity];head = tail = 0;size = 0;}// 当前队列的容量public int getCapacity() {return data.length - 1;}public int getSize() {return size;}public void enqueue(E e) {if ((tail + 1) % data.length == head) {// 队列满了resize(getCapacity() * 2);}data[tail] = e;size++;tail = (tail + 1) % data.length;}public E dequeue() { // O(1)if (isEmpty()) {throw new RuntimeException("dequeue error, No Element for dequeue");}E res = data[head];data[head] = null;size--;head = (head + 1) % data.length;if (size == getCapacity() / 4) {resize(getCapacity() / 2);}return res;}private void resize(int newCapacity) {E[] newData = (E[])new Object[newCapacity + 1];for (int i = 0; i < size; i++) {newData[i] = data[(i + head) % data.length];}data = newData;head = 0;tail = size;}public E getFront() {return data[head];}public boolean isEmpty() {return head == tail;}public String toString() {StringBuilder sb = new StringBuilder();sb.append(String.format("Queue:size = %d, capacity = %d\n", size, getCapacity()));sb.append(" 队首 [");for (int i = head; i != tail ; i = (i + 1) % data.length) {sb.append(data[i]);if ((i + 1) % data.length != tail) {sb.append(",");}}sb.append("]");return sb.toString();}}
码字不易,点赞、看一看两连即可。