
Pandas骚操作:用 pandas 快速爬数据
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包

提起爬虫,大家可能都知道requests、beautifulsoup、scrapy、selenium等等一些工具库。但其实对于一些日常的网页Table表格数据抓取来讲,没有必要去F12研究HTML页面结构甚至写正则表达式解析字段。
本次东哥介绍一个超级简单的方法,用pandas也可以玩爬虫。
pandas自带一个方法是read_html,利用这个方法可以直接爬虫网页的Table表格型数据,无需敲更多的爬虫代码,简单!粗暴!
查看HTML结构,如果发现是下面这个table格式的,那直接可以上手开干。
<table class="..." id="...">
<thead>
<tr>
<th>...</th>
</tr>
</thead>
<tbody>
<tr>
<td>...</td>
</tr>
<tr>...</tr>
<tr>...</tr>
...
<tr>...</tr>
<tr>...</tr>
</tbody>
</table>
下面我们来看下如何操作。
一、使用方法
举一个例子,拿wiki百科上的各国家收入的页面抓取演示一下。
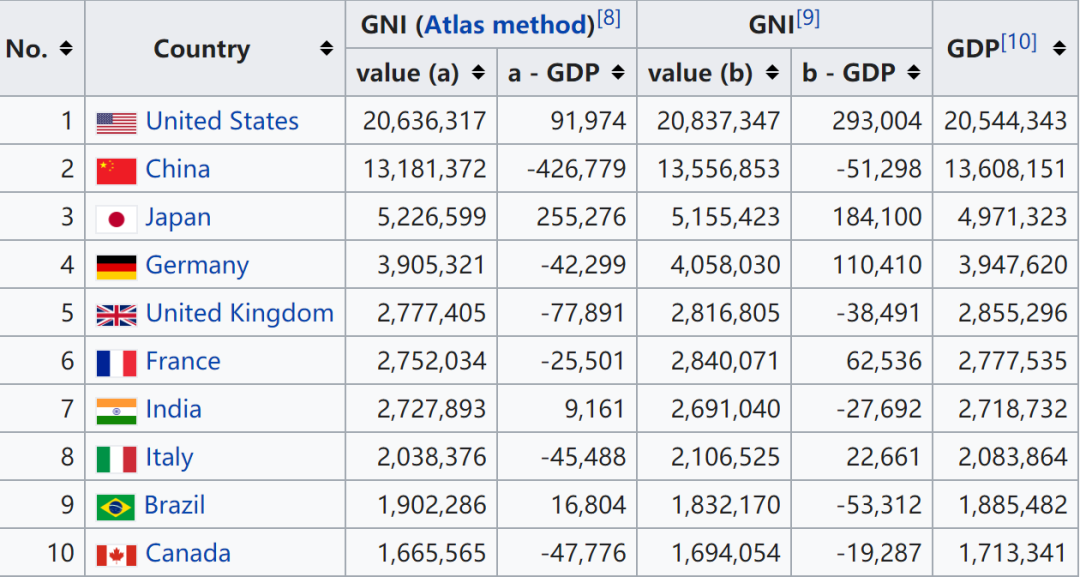
read_html,它可以自动将网页的所有表格数据全部抓取下来。代码如下:import pandas as pd
url = 'https://en.wikipedia.org/wiki/Gross_national_income'
tables = pd.read_html(url)
这里返回的tables是一个DataFrames的列表,每个DataFrame就是网页中从上到下顺序的数据表格。因此,可以用列表的切片tables[x]来提取网页指定的表格数据。
比如,我们对第4个表格感兴趣,那么直接:
talbes[3]
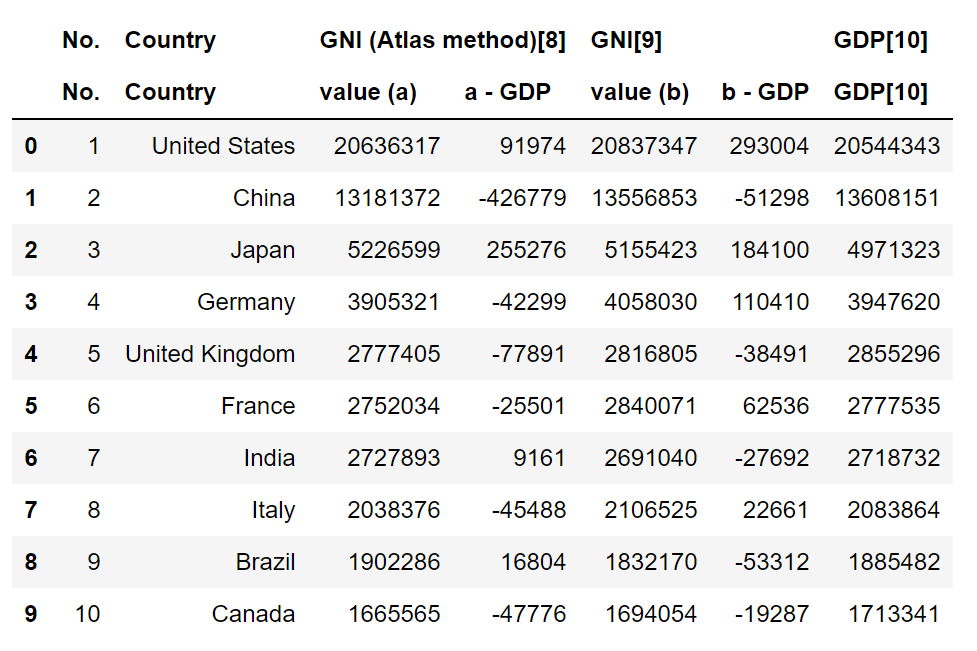
当然,上面表格看起来有点别扭,我们可以简单几个操作调整一下表结构。
df = tables[3].droplevel(0, axis=1)\
.rename(columns={'No.':'No', 'GDP[10]':'GDP'})\
.set_index('No')
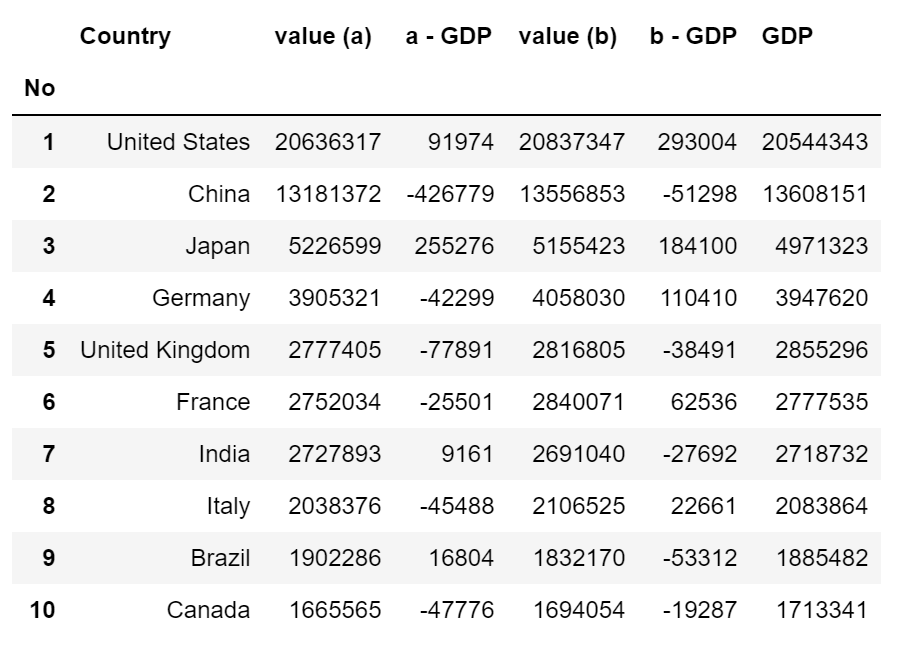
这样看起来就好多了。
最后,read_html中也配有很多参数可供调整,比如匹配方式、标题所在行、网页属性识别表格等等,具体说明可以参看pandas的官方文档学习。
官网链接:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_html.html
以上所有代码已上传至我的GitHub:
项目链接:https://github.com/xiaoyusmd/PythonDataScience
原创不易,GitHub给个Star求续命
- END -
推荐阅读
推荐一个公众号,帮助程序员自学与成长
觉得还不错就给我一个小小的鼓励吧!

评论