
从 MySQL 执行原理告诉你:为什么分页场景下,请求速度非常慢?
从一个问题说起
答案的追寻
确认场景
小白作答
继续解答
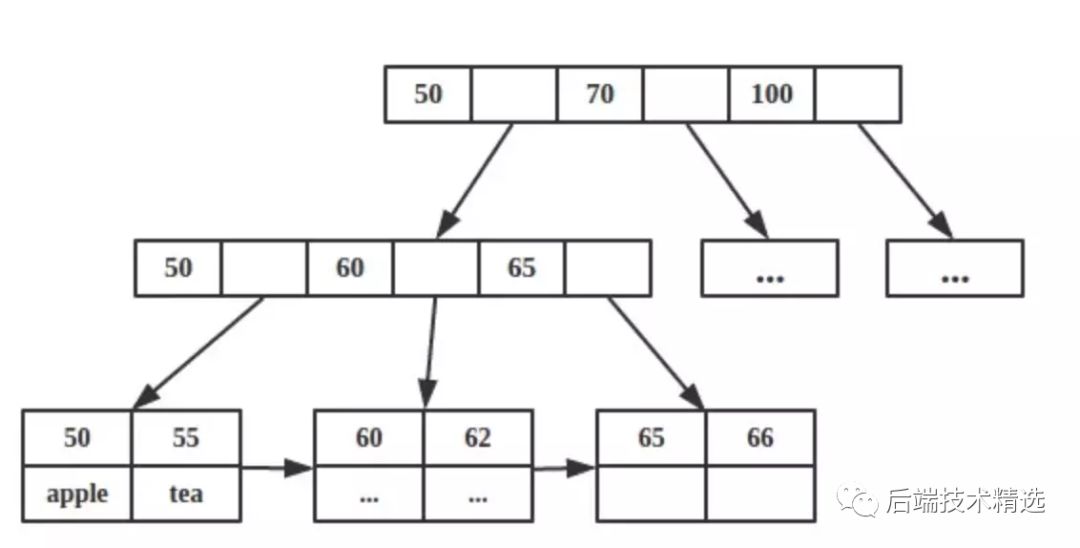
系统学习
聚簇索引:包含主键索引和对应的实际数据,索引的叶子节点就是数据节点 辅助索引:可以理解为二级节点,其叶子节点还是索引节点,包含了主键id。
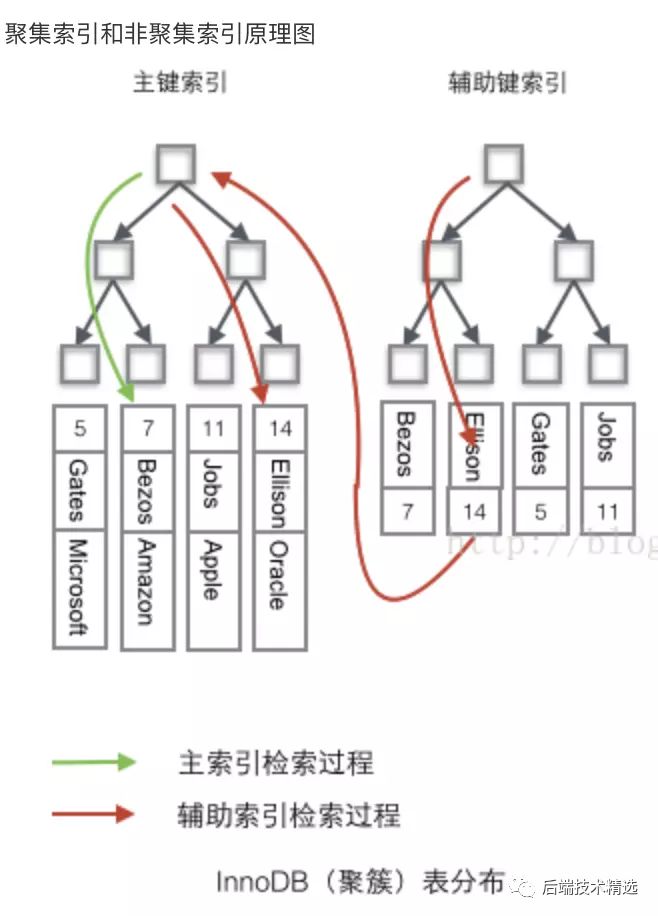
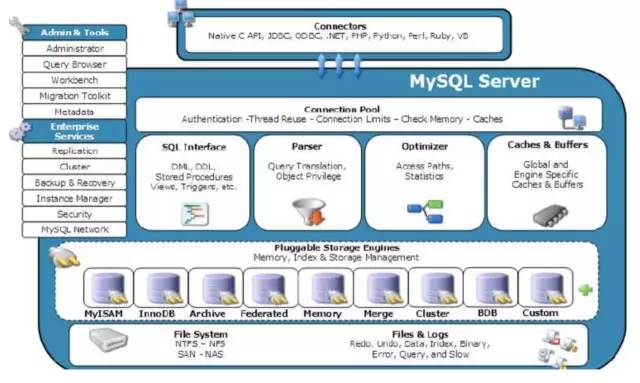
触类旁通
DataSource 这个就是数据源,也就是表,select * from t 里面的 t。 Selection 选择,例如 select xxx from t where xx = 5 里面的 where 过滤条件。 Projection 投影, select c from t 里面的取 c 列是投影操作。 Join 连接, select xx from t1, t2 where t1.c = t2.c 就是把 t1 t2 两个表做 Join。
select b from t1, t2 where t1.c = t2.c and t1.a > 5变成逻辑查询计划之后,t1 t2 对应的 DataSource,负责将数据捞上来。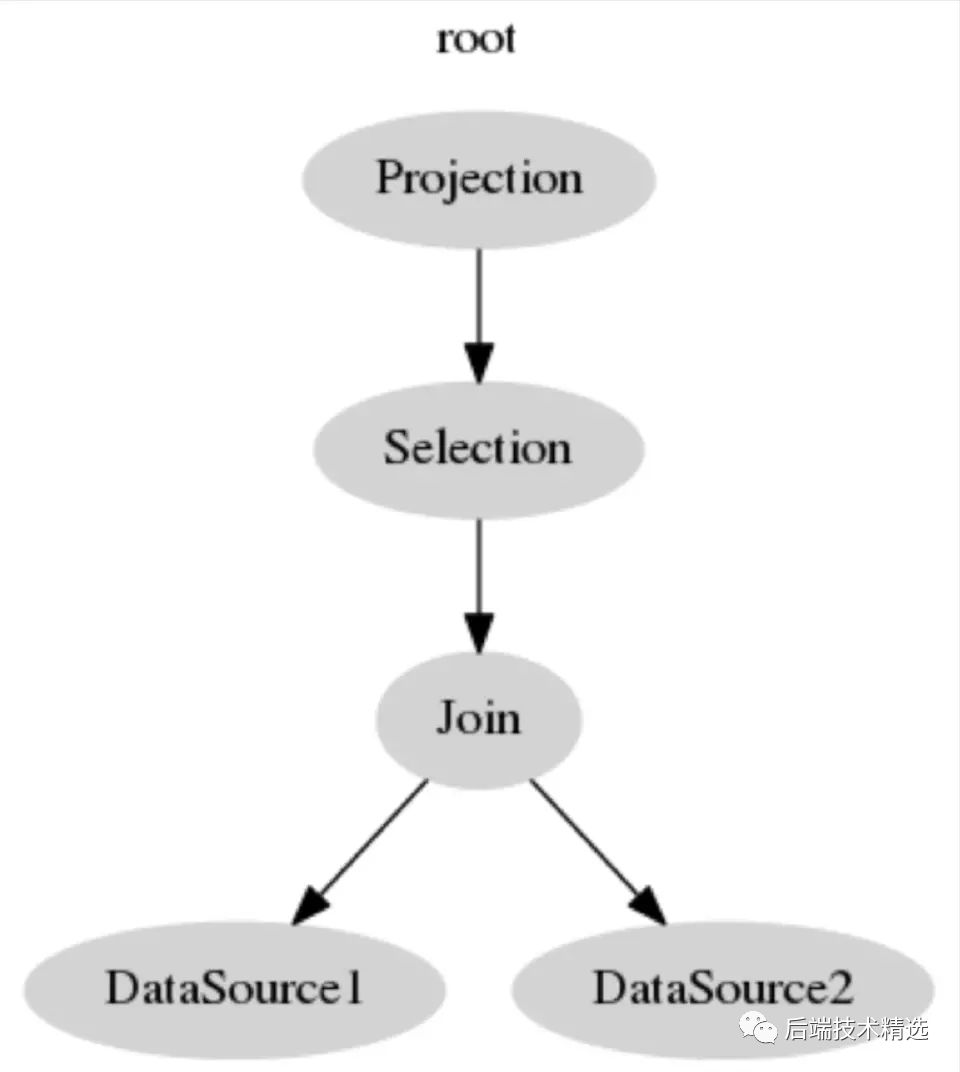
怎么解决
《高性能MySQL》提到了两种方案
方案一
方案二
select xxx,xxx from in (select id from table where second_index = xxx limit 10 offset 10000)这句话是说,先从条件查询中,查找数据对应的数据库唯一id值,因为主键在辅助索引上就有,所以不用回归到聚簇索引的磁盘去拉取。再通过这些已经被limit出来的10个主键id,去查询聚簇索引。这样只会十次随机io。写在最后
来源:juejin.im/post/5c4db295e51d4503834d9c43
本文版权归原作者所有,如有问题请联系我删除。

评论