
快速学Python,走个捷径~
大家好,我是小菜。一个希望能够成为 吹着牛X谈架构 的男人!如果你也想成为我想成为的人,不然点个关注做个伴,让小菜不再孤单!
本文主要介绍
python 的入门学习如有需要,可以参考
如有帮助,不忘 点赞 ❥
微信公众号已开启,菜农曰,没关注的同学们记得关注哦!
哈喽,大家好。这里是小菜良记的前身菜农曰。不要因为名字改了,头像换了,大家就迷路了哦~
最近为了扩展语言面,这周大概了解了一下 Python 的玩法,学完之后发现,哎嘛,真香。不知道大家刚学一门语言的时候有没有觉得这语言有点意思,什么都想试一试。
说到 Python 大家的反应可能就是 爬虫、自动化测试,比较少会说到用 python 来做 web 开发,相对来说,在国内 web 开发使用比较多的语言还是 java~ 但是并不是说 python 不适合用于做 web 开发,据我了解到常用的 web框架有Django和flask 等~
Django 是一个很重的框架,它提供了很多很方便的工具,对很多东西也进行封装,不需要自己过多的造轮子
Flask 的优点是小巧,但缺点也是小巧,灵活的同时意味着自己需要造更多的轮子,或者花更多的时间配置
但是咱们这篇的重点不是介绍 python 的 web 开发,也不是介绍 python 的基础入门,而是聊聊 python 的自动化测试和爬虫入门~
在我看来,如果你有其他语言的开发经验,小菜还是比较建议直接从一个案例入手,一边看一边学,语法之类其实都是相同的(后面会出结合 java 去学 python 的内容),代码基本能读个八九不离十,但是如果没有任何语言开发经验的同学,那小菜还是建议从头系统的学习,视频和书籍都是不错的选择,这里推荐 廖雪峰老师 的博客,内容相当不错 Python教程
一、自动化测试
python 能干的事情很多,能干有趣的事情也很多
学习一门语言,当然得找兴趣点才能学得更快,比如说你想要爬某某网站的图片或视频,是吧~
什么是自动化测试?那就是 自动化 + 测试,只要你编写好了一段脚本(.py 文件),运行后会自动帮你在后台进行测试的流程运行,那么使用自动化测试,有一个很好的工具可以帮助你完成,那就是 Selenium
Selenium 是一款 web 自动化测试工具,可以很方便地模拟真实用户对浏览器的操作,它支持各种主流浏览器,比如IE、Chrome、Firefox、Safari、Opera 等,这里使用 python 进行演示说明,并不是说 Selenium 只支持 python,它有多重编程语言的客户端驱动,语法简介~ 下面我们做一个简单的示例演示!
1)前置准备
为了保证演示的顺利,我们需要做一些前置准备,不然可能会造成浏览器无法正常打开的情况~
步骤1
查看浏览器版本,我们以下是使用 Edge,我们可在网址输入框输入 edge://version 查看浏览器版本,然后到对应的驱动商店进行对应版本驱动的安装 Microsoft Edge - Webdriver (windows.net)
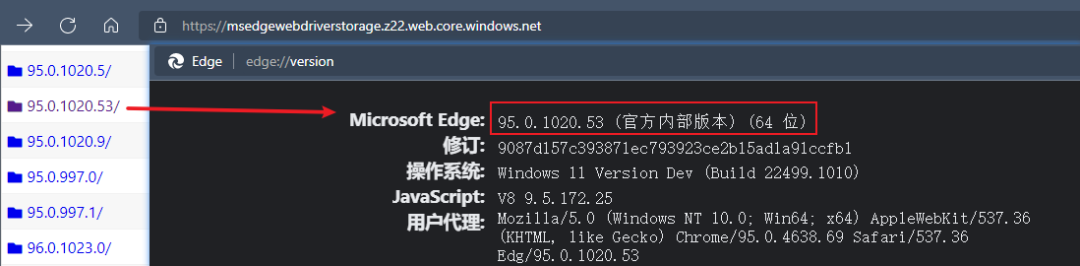
步骤2
然后我们将下载好的驱动文件解压到你 python 的安装目录下的 Scripts文件夹下
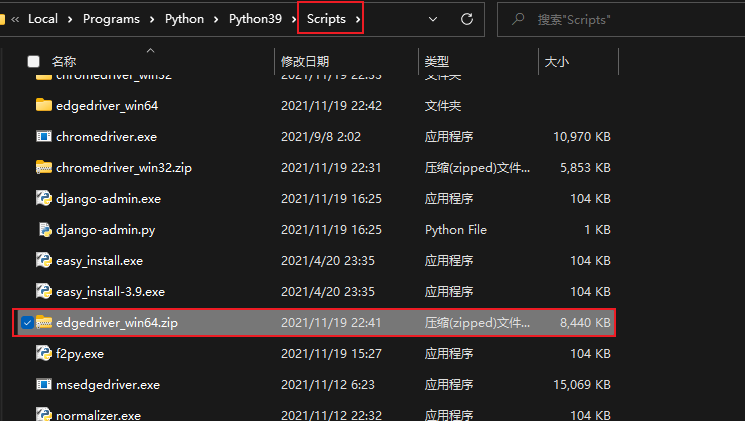
2)浏览器操作
做好前置准备,我们来看下面一段简单代码:
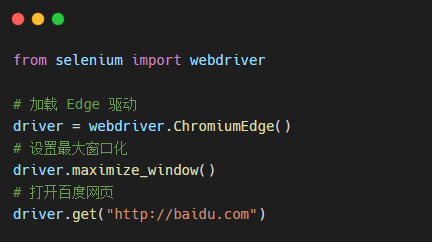
加上导包总共也才 4 行代码,并在终端输入 python autoTest.py,并得到了以下演示效果:
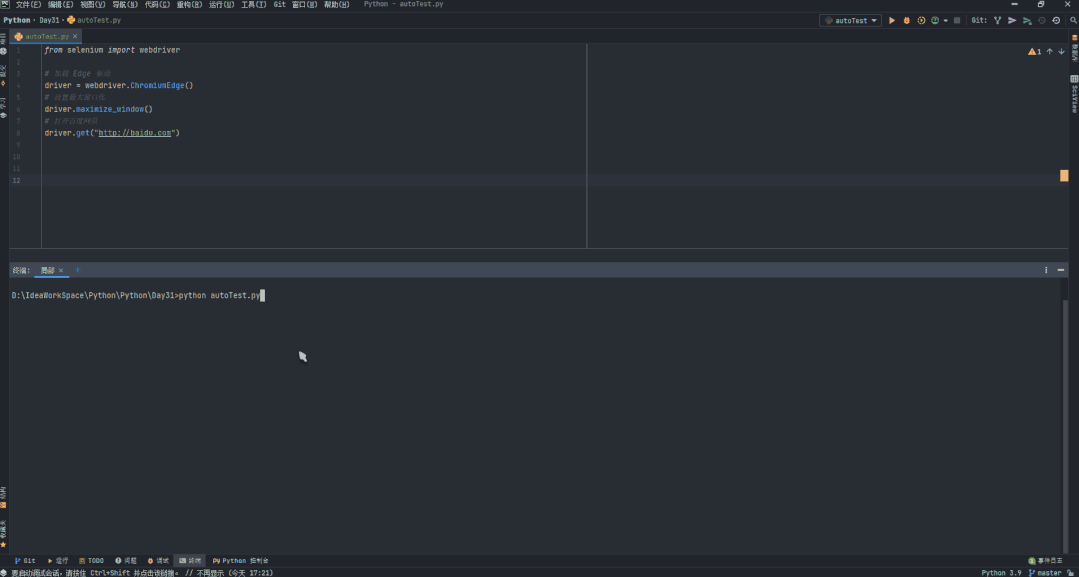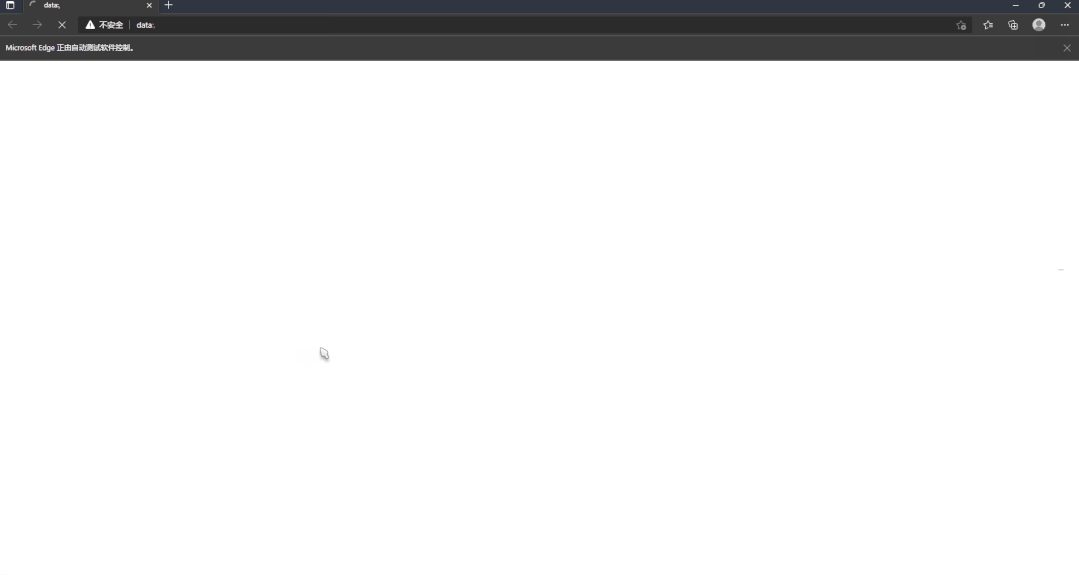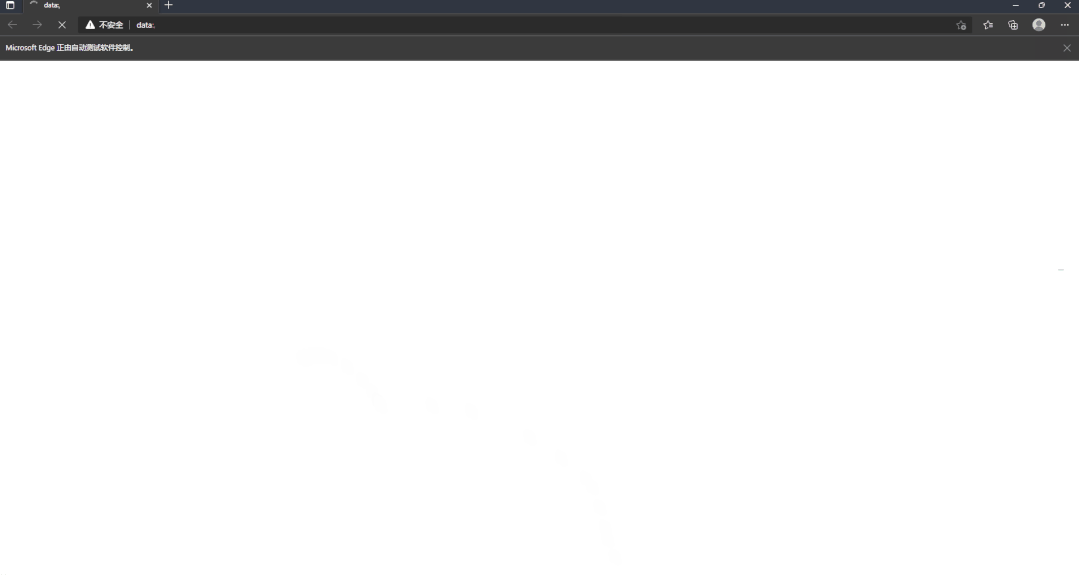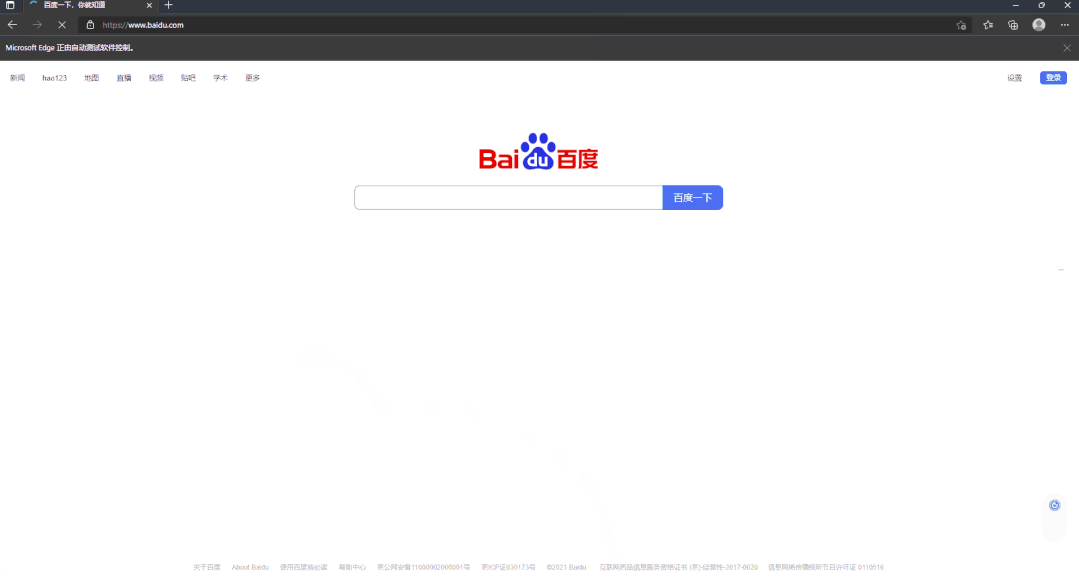
可以看到利用该脚本已经实现了自动打开浏览器、自动放大窗口、自动打开百度网页,三个自动化操作,将我们的学习向前拉近了一步,是不是觉得有点意思~ 下面让你逐渐沉沦!
这里介绍几个针对浏览器操作的常用方法:
| 方法 | 说明 |
|---|---|
| webdriver.xxx() | 用于创建浏览器对象 |
| maximize_window() | 窗口最大化 |
| get_window_size() | 获取浏览器尺寸 |
| set_window_size() | 设置浏览器尺寸 |
| get_window_position() | 获取浏览器位置 |
| set_window_position(x, y) | 设置浏览器位置 |
| close() | 关闭当前标签/窗口 |
| quit() | 关闭所有标签/窗口 |
这几个当然是 Selenium 的基本常规操作,更出色的还在后面~
当我们打开了浏览器,想做的当然不只是打开网页这种简单的操作,毕竟程序员的野心是无限的!我们还想自动操作页面元素,那么这就需要说到 Selenium 的定位操作了
3)定位元素
页面的元素定位对于前端来说并不陌生,用 JS 可以很轻松的实现元素定位,比如以下几种:
通过 id 进行定位
document.getElementById("id")
通过 name 进行定位
document.getElementByName("name")
通过标签名进行定位
document.getElementByTagName("tagName")
通过 class 类进行定位
document.getElementByClassName("className")
通过 css 选择器进行定位
document.querySeletorAll("css selector")
以上几种方式都能实现元素的选取定位,当然我们这节的主角是 Selenium,作为主推的自动化测试工具,怎么能示弱呢~ 它实现页面元素定位的方式有 8 种,如下:
id定位
driver.find_element_by_id("id")
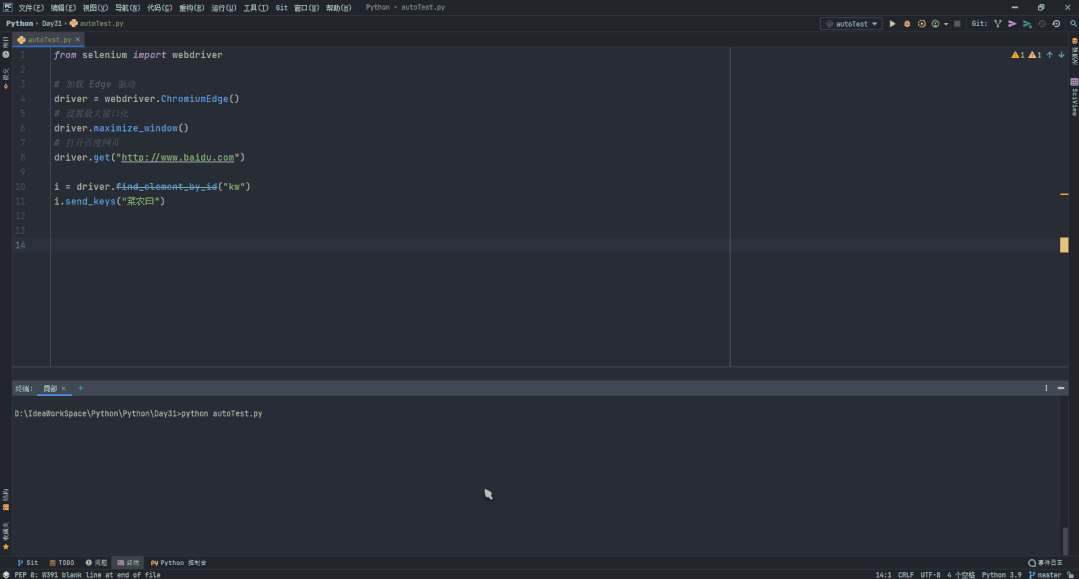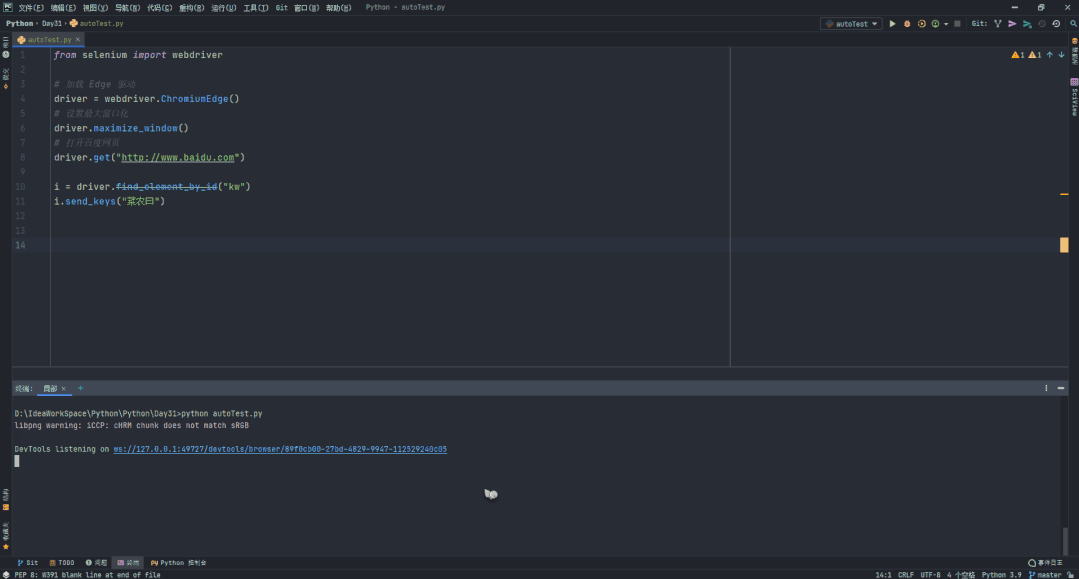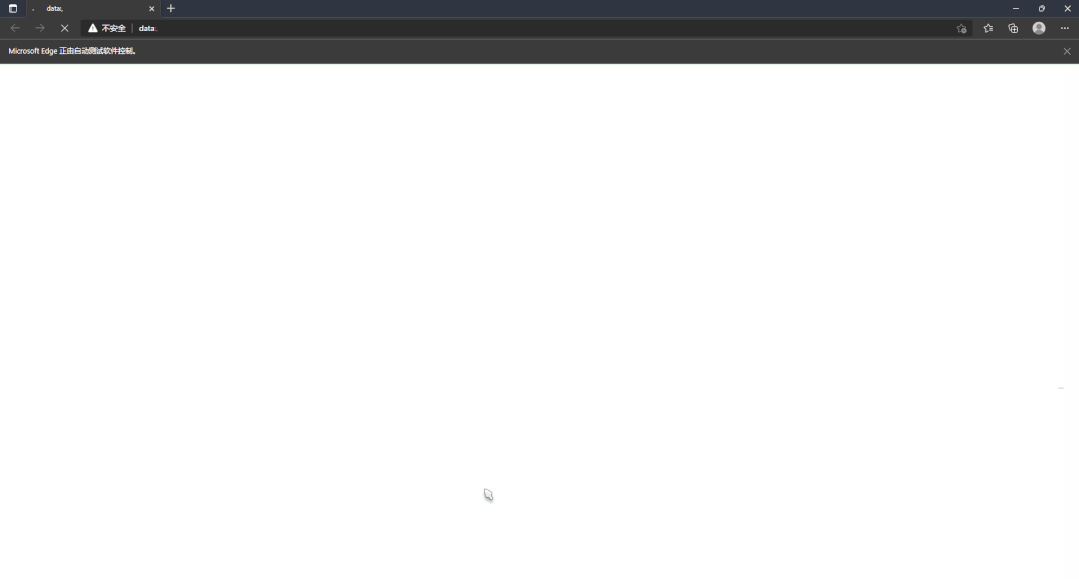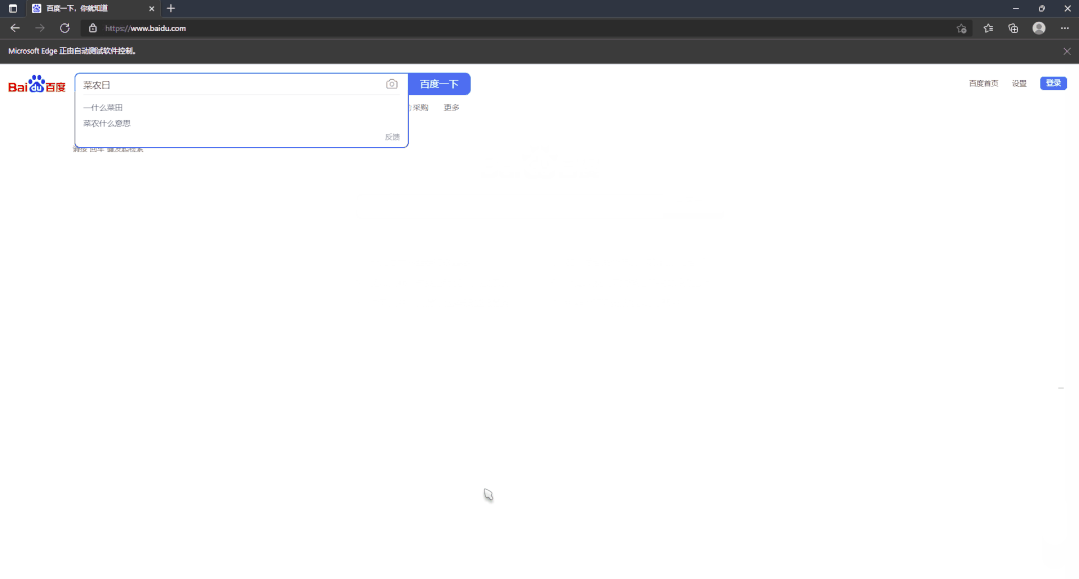
我们打开百度页面,可以发现该输入框的 id 是 kw,
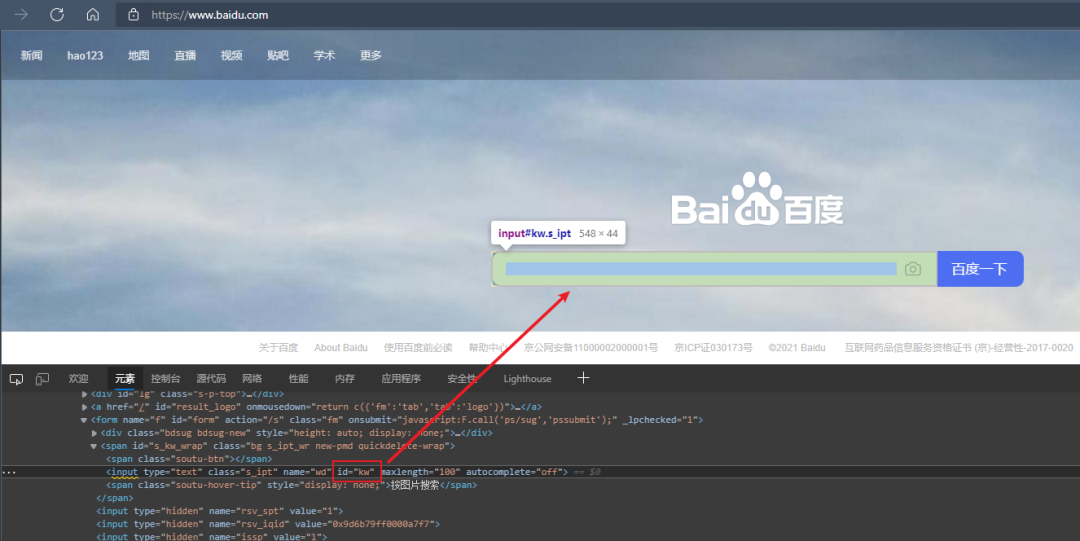
在清楚了元素 ID 之后,我们就可以使用 id 进行元素定位,方式如下
from selenium import webdriver
# 加载 Edge 驱动
driver = webdriver.ChromiumEdge()
# 设置最大窗口化
driver.maximize_window()
# 打开百度网页
driver.get("http://baidu.com")
# 通过 id 定位元素
i = driver.find_element_by_id("kw")
# 往输入框输入值
i.send_keys("菜农曰")
name属性值定位
driver.find_element_by_name("name")
name 定位的方式与 id 相似,都是需要通过查找name的值,然后调用对应的 api,使用方式如下:
from selenium import webdriver
# 加载 Edge 驱动
driver = webdriver.ChromiumEdge()
# 设置最大窗口化
driver.maximize_window()
# 打开百度网页
driver.get("http://baidu.com")
# 通过 id 定位元素
i = driver.find_element_by_name("wd")
# 往输入框输入值
i.send_keys("菜农曰")
类名定位
driver.find_element_by_class_name("className")
与 id 和 name 定位方式一致,需要找到对应的 className 然后进行定位~
标签名定位
driver.find_element_by_tag_name("tagName")
这种方式我们在日常中使用还是比较少的,因为在 HTML 是通过 tag 来定义功能的,比如 input 是输入,table 是表格... 每个元素其实都是一个 tag,一个 tag 往往用来定义一类功能,在一个页面中可能存在多个 div,input,table 等,因此使用 tag 很难精准定位元素~
css选择器
driver.find_element_by_css_selector("cssVale")
这种方式需要连接 css 的五大选择器
五大选择器
元素选择器 最常见的css选择器便是元素选择器,在HTML文档中该选择器通常是指某种HTML元素,例如:
html {background-color: black;}
p {font-size: 30px; backgroud-color: gray;}
h2 {background-color: red;}
类选择器
.加上类名就组成了一个类选择器,例如:.deadline { color: red;}
span.deadline { font-style: italic;}
id 选择器 ID选择器和类选择器有些类似,但是差别又十分显著。首先一个元素不能像类属性一样拥有多个类,一个元素只能拥有一个唯一的ID属性。使用ID选择器的方法为井号
#加上id值,例如:#top { ...}
属性选择器 我们可以根据元素的属性及属性值来选择元素,例如:
a[href][title] { ...}
派生选择器 它又名上下文选择器,它是使用文档DOM结构来进行css选择的。例如:
body li { ...}
h1 span { ...}
当然这边选择器只是做一个简单的介绍,更多内容自行文档查阅~
在了解选择器之后我们就可以愉快的进行 css 选择器 定位了:
from selenium import webdriver
# 加载 Edge 驱动
driver = webdriver.ChromiumEdge()
# 设置最大窗口化
driver.maximize_window()
# 打开百度网页
driver.get("http://baidu.com")
# 通过 id选择器 定位元素
i = driver.find_elements_by_css_selector("#kw")
# 往输入框输入值
i.send_keys("菜农曰")
链接文本定位
driver.find_element_by_link_text("linkText")
这种方式是专门用来定位文本链接的,比如我们可以看到百度的首页上有个 新闻、hao123、地图... 等链接元素
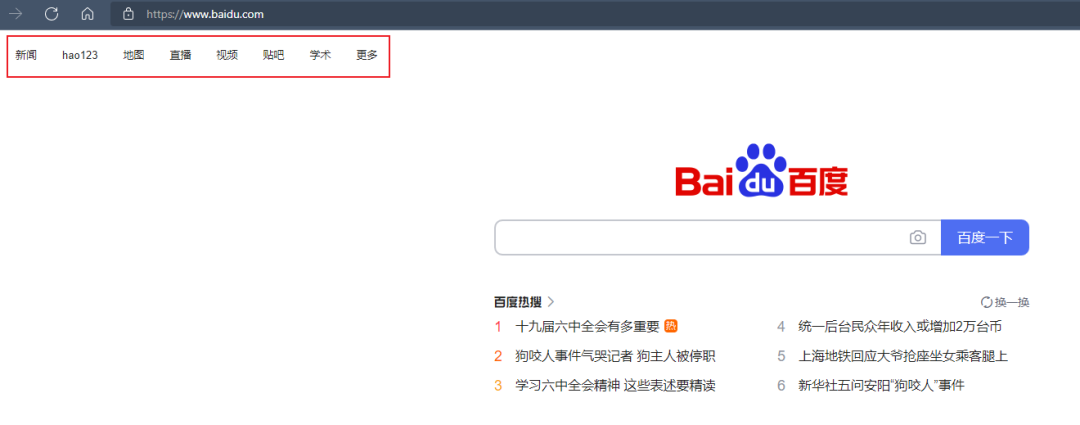
那么我们就可以利用链接文本来进行定位
from selenium import webdriver
# 加载 Edge 驱动
driver = webdriver.ChromiumEdge()
# 设置最大窗口化
driver.maximize_window()
# 打开百度网页
driver.get("http://baidu.com")
# 通过 链接文本 定位元素并 点击
driver.find_element_by_link_text("hao123").click()
部分链接文本
driver.find_element_by_partial_link_text("partialLinkText")
这种方式是对 link_text 的辅助,有时候可能一个超链接文本特别长,如果我们全部输入既麻烦又不美观
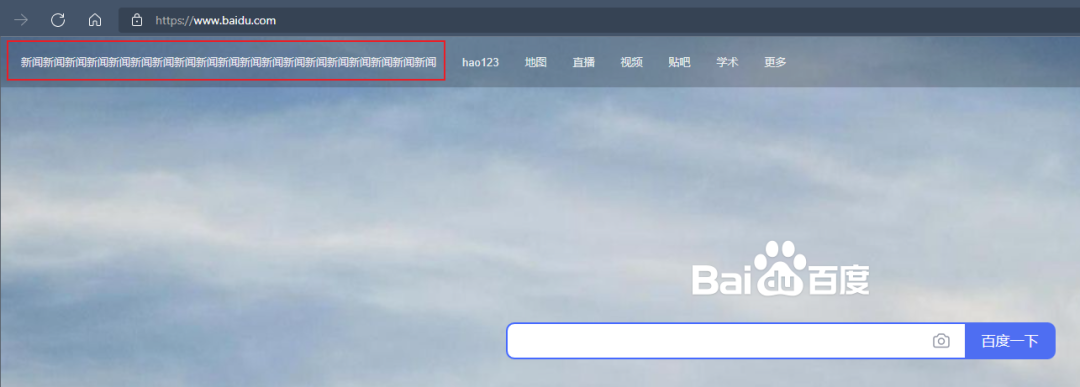
那其实我们只需要截取一部分字符串让 selenium 理解我们要选取的内容即可,那么就是使用 partial_link_text 这种方式~
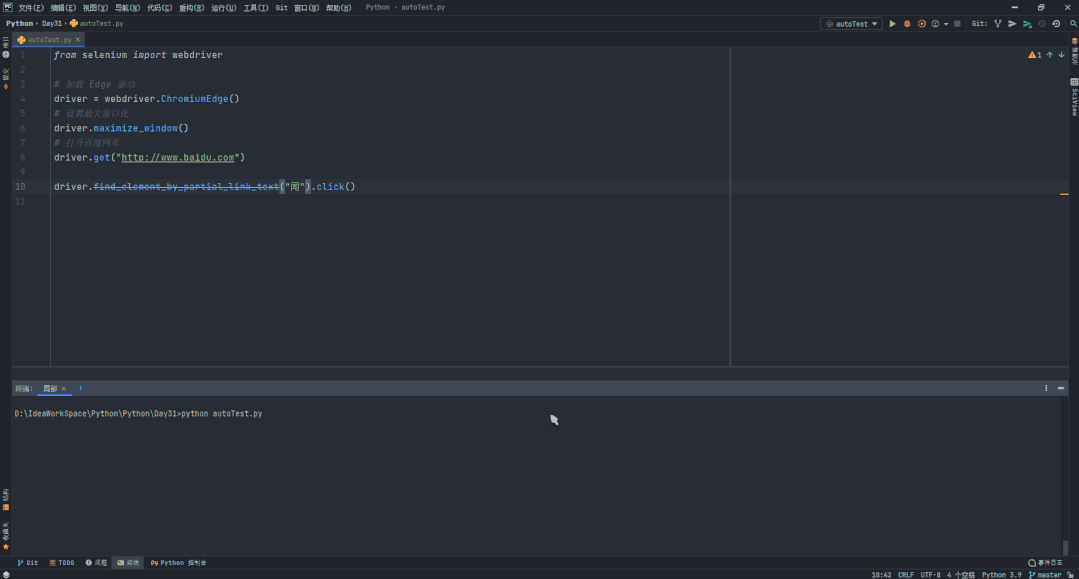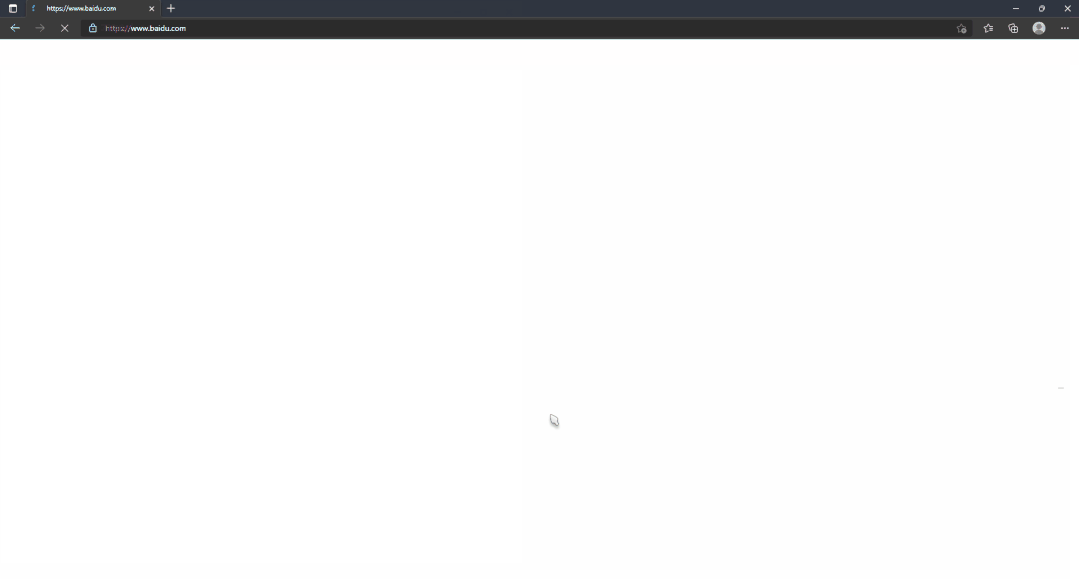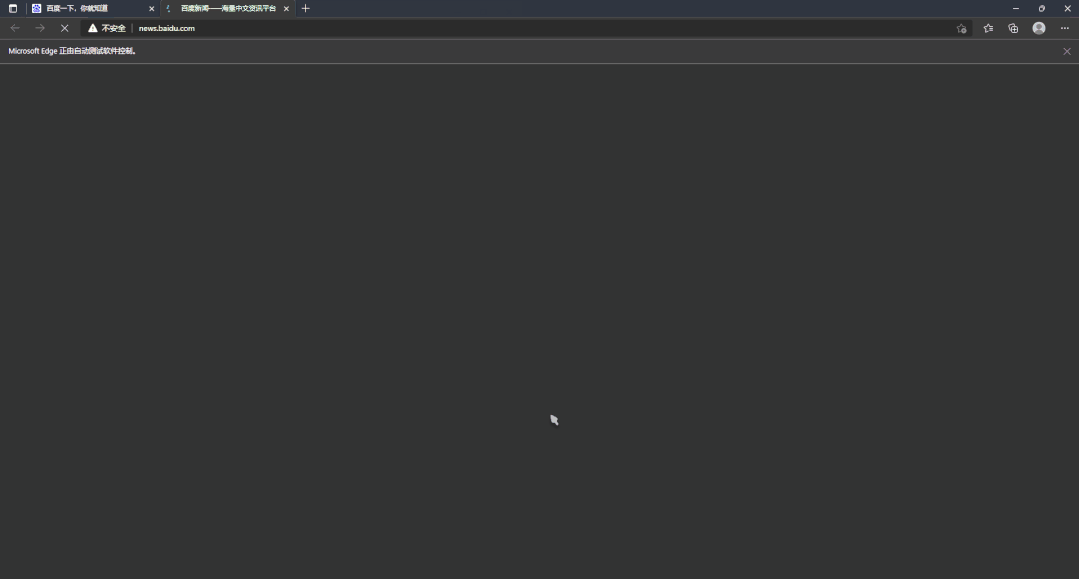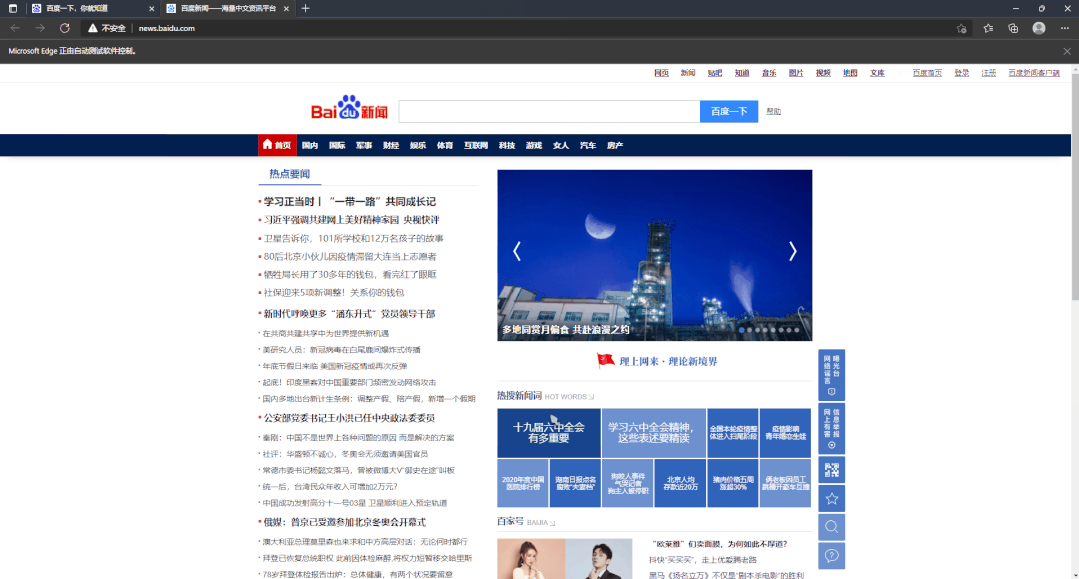
xpath 路径表达式
driver.find_element_by_xpath("xpathName")
前面介绍的几种定位方法都是在理想状态下,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。但是有时候我们要定位的元素并没有id,name,class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。那么这个时候我们就只能通过xpath或者CSS来定位了。当然 xpath 的值并不需要你去计算我们只需要打开页面然后在 F12 中找到对应元素,右击复制 xpath 即可
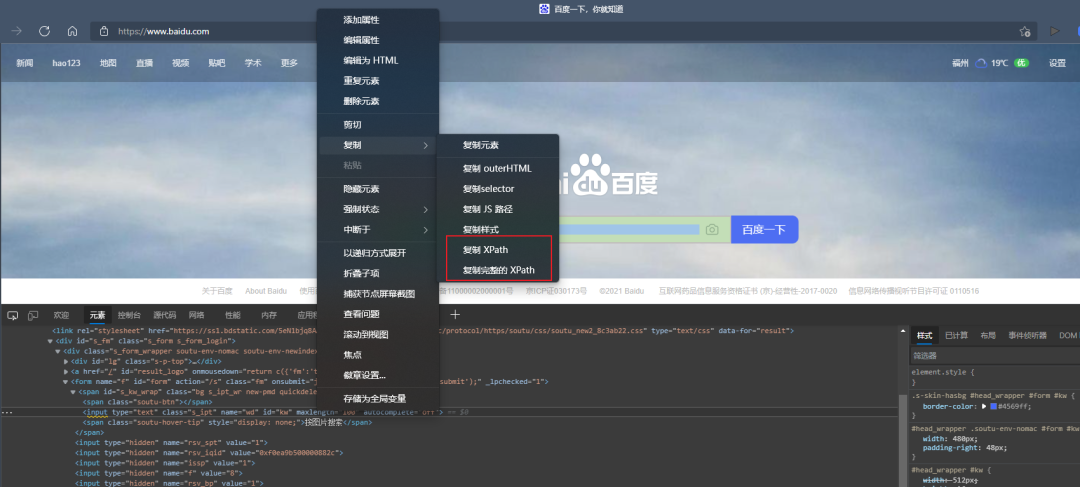
然后在代码中进行定位:
from selenium import webdriver
# 加载 Edge 驱动
driver = webdriver.ChromiumEdge()
# 设置最大窗口化
driver.maximize_window()
# 打开百度网页
driver.get("http://www.baidu.com")
driver.find_element_by_xpath("//*[@id='kw']").send_keys("菜农曰")
4)元素操作
我们想做的当然不只是元素的选取,而是选取元素后的操作,我们在上面演示中其实就已经进行了两种操作 click() 和 send_keys("value"),这里继续介绍几种其他操作~
| 方法名 | 说明 |
|---|---|
| click() | 点击元素 |
| send_keys("value") | 模拟按键输入 |
| clear() | 清除元素的内容,比如 输入框 |
| submit() | 提交表单 |
| text | 获取元素的文本内容 |
| is_displayed | 判断元素是否可见 |
看完是不是有一种似曾相似的感觉,这不就是 js 的基本操作吗~!
5)实操练习
学完以上操作,我们就可以模拟一个小米商城的购物操作,代码如下:
from selenium import webdriver
item_url = "https://www.mi.com/buy/detail?product_id=10000330"
# 加载 Edge 驱动
driver = webdriver.ChromiumEdge()
# 设置最大窗口化
driver.maximize_window()
# 打开商品购物页
driver.get(item_url)
# 隐式等待 设置 防止网络阻塞页面未及时加载
driver.implicitly_wait(30)
# 选择地址
driver.find_element_by_xpath("//*[@id='app']/div[3]/div/div/div/div[2]/div[2]/div[3]/div/div/div[1]/a").click()
driver.implicitly_wait(10)
# 点击手动选择地址
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div["
"1]/div/div/div[2]/span[1]").click()
# 选择福建
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div/div/div/div["
"1]/div[2]/span[13]").click()
driver.implicitly_wait(10)
# 选择市
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div/div/div/div["
"1]/div[2]/span[1]").click()
driver.implicitly_wait(10)
# 选择区
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div/div/div/div["
"1]/div[2]/span[1]").click()
driver.implicitly_wait(10)
# 选择街道
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div/div/div/div["
"1]/div[2]/span[1]").click()
driver.implicitly_wait(20)
# 点击加入购物车
driver.find_element_by_class_name("sale-btn").click()
driver.implicitly_wait(20)
# 点击去购物车结算
driver.find_element_by_xpath("//*[@id='app']/div[2]/div/div[1]/div[2]/a[2]").click()
driver.implicitly_wait(20)
# 点击去结算
driver.find_element_by_xpath("//*[@id='app']/div[2]/div/div/div/div[1]/div[4]/span/a").click()
driver.implicitly_wait(20)
# 点击同意协议
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div[3]/button[1]").click()
效果如下:
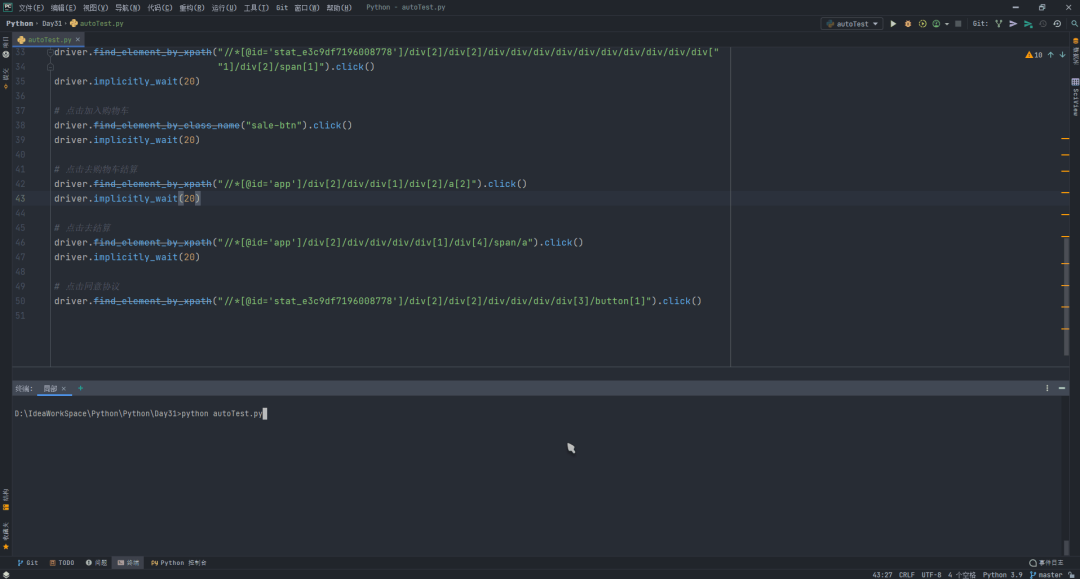
while 循环去轮询访问!二、爬虫测试
上面我们实现了如何使用 Selenium 来实现自动化测试,使用须合法~ 接下来我们来展示 python 另一个强大的功能,那就是用于 爬虫
在学习爬虫之前,我们需要了解几个必要的工具
1)页面下载器
python 标准库中已经提供了 :urllib、urllib2、httplib 等模块以供 http 请求,但是 api 不够好用优雅~,它需要巨量的工作,以及各种方法的覆盖,来完成最简单的任务,当然这是程序员所不能忍受的,各方豪杰开发除了各种好用的第三方库以供使用~
request
request 是使用 apaches2 许可证的基于 python 开发的http库,它在 python 内置模块的基础上进行了高度的封装,从而使使用者在进行网络请求时可以更加方便的完成浏览器可有的所有操作~
scrapy
request 和 scrapy 的区别可能就在于,scrapy 是一个比较重量级的框架,它属于网站级爬虫,而 request 是页面级爬虫,并发数和性能没有 scrapy 那么好
2)页面解析器
BeautifulSoup
BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后便可以使用他提供的方法进行快速查找指定元素,从而使得在HTML或XML中查找指定元素变得简单。
scrapy.Selector
Selector 是基于parsel,一种比较高级的封装,通过特定的 XPath 或者 CSS 表达式来选择HTML文件中的某个部分。它构建于 lxml 库之上,这意味着它们在速度和解析准确性上非常相似。
具体使用可以查阅Scrapy 文档,介绍的相当详细
3)数据存储
当我们爬下来内容后,这个时候就需要有一个对应的存储源进行存储
具体数据库操作会在后续的 web 开发博文中进行介绍~
txt 文本
使用文件 file 的常用操作
sqlite3
SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中
mysql
不做过多介绍,懂的都懂,web 开发老情人了
4)实操练习
网络爬虫,其实叫作网络数据采集更容易理解。它就是通过编程向网络服务器请求数据(HTML表单),然后解析HTML,提取出自己想要的数据。
我们可以简单分为 4 个步骤:
根据给定 url 获取 html 数据 解析 html,获取目标数据 存储数据
当然这一切需要建立在你懂 python 的简单语法和 html 的基本操作~
我们接下来使用 request + BeautifulSoup + text 的组合进行操作练习,假定我们想要爬取廖雪峰老师的python教程内容~
# 导入requests库
import requests
# 导入文件操作库
import codecs
import os
from bs4 import BeautifulSoup
import sys
import json
import numpy as np
import importlib
importlib.reload(sys)
# 给请求指定一个请求头来模拟chrome浏览器
global headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'}
server = 'https://www.liaoxuefeng.com/'
# 廖雪峰python教程地址
book = 'https://www.liaoxuefeng.com/wiki/1016959663602400'
# 定义存储位置
global save_path
save_path = 'D:/books/python'
if os.path.exists(save_path) is False:
os.makedirs(save_path)
# 获取章节内容
def get_contents(chapter):
req = requests.get(url=chapter, headers=headers)
html = req.content
html_doc = str(html, 'utf8')
bf = BeautifulSoup(html_doc, 'html.parser')
texts = bf.find_all(class_="x-wiki-content")
# 获取div标签id属性content的内容 \xa0 是不间断空白符
content = texts[0].text.replace('\xa0' * 4, '\n')
return content
# 写入文件
def write_txt(chapter, content, code):
with codecs.open(chapter, 'a', encoding=code)as f:
f.write(content)
# 主方法
def main():
res = requests.get(book, headers=headers)
html = res.content
html_doc = str(html, 'utf8')
# HTML解析
soup = BeautifulSoup(html_doc, 'html.parser')
# 获取所有的章节
a = soup.find('div', id='1016959663602400').find_all('a')
print('总篇数: %d ' % len(a))
for each in a:
try:
chapter = server + each.get('href')
content = get_contents(chapter)
chapter = save_path + "/" + each.string.replace("?", "") + ".txt"
write_txt(chapter, content, 'utf8')
except Exception as e:
print(e)
if __name__ == '__main__':
main()
当我们运行程序后便可以在 D:/books/python 位置看到我们所爬取到的教程内容!
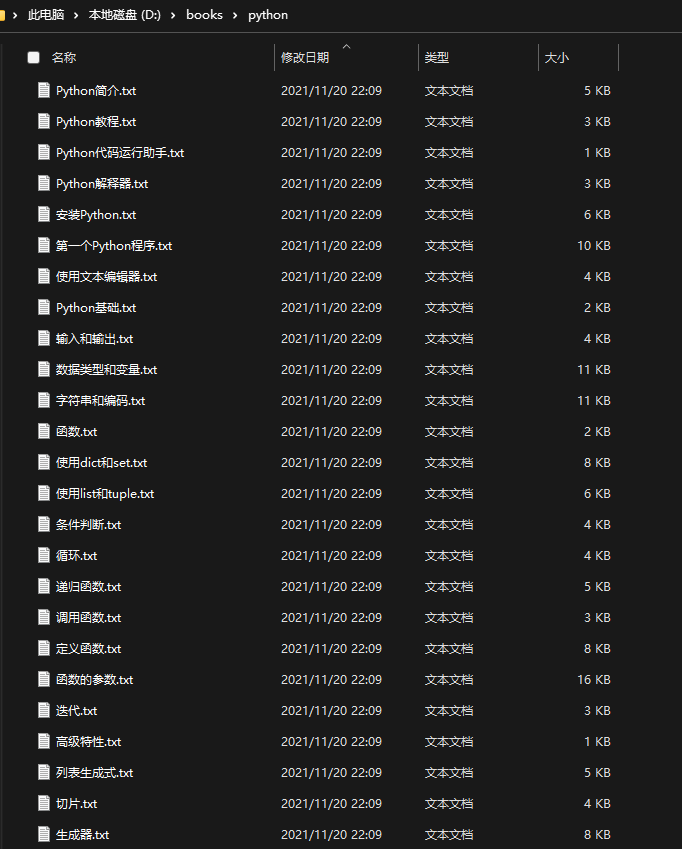
这样子我们就已经简单的实现了爬虫,不过爬虫需谨慎~!
咱们这篇以两个维度 自动化测试 和 爬虫 认识了 python的使用,希望能够激发出你的兴趣点~
不要空谈,不要贪懒,和小菜一起做个吹着牛X做架构的程序猿吧~点个关注做个伴,让小菜不再孤单。咱们下文见!

今天的你多努力一点,明天的你就能少说一句求人的话!
我是小菜,一个和你一起变强的男人。💋微信公众号已开启,菜农曰,没关注的同学们记得关注哦!