
数仓要了解的BI数据分析方法
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

数仓开发经常需要与数据表打交道,那么数仓表开发完成之后就万事大吉了吗?显然不是,还需要思考一下如何分析数据以及如何呈现数据,因为这是发挥数据价值很重要的一个方面。通过数据的分析与可视化呈现可以更加直观的提供数据背后的秘密,从而辅助业务决策,实现真正的数据赋能业务。通过本文你可以了解到:
帕累托分析方法与数据可视化 RFM分析与数据可视化 波士顿矩阵与数据可视化
帕累托分析与数据可视化
基本概念
帕累托(Pareto)分析法,又称ABC分析法,即我们平时所提到的80/20法则。关于帕累托(Pareto)分析法,在不同的行业都有不同的应用。
举个栗子
在企业的库存管理中,可以发现少数品种在总需用量(或是总供给额、库存总量、储备金总额)中,占了很大的比重,但在相应的量值中所占的比重很少。因此可以运用帕累托分析法,将企业所需的各种物品,按其需用量的大小、物品的重要程度、资源短缺和采购的难易程度、单价的高低、占用储备资金的多少等因素分为若干类,实施分类管理。
商品销售额分析中,某些商品的销售额占了总销售额的很大部分,某些商品的销售额仅占很小的比例,这样就可以将其分为A、B、C几大类,对销售额占比较多的分类进行投入,以获得更多的销售额。
在质量分析中,对某种原因导致产品质量不合格的产品数量进行分析,使用帕累托(Pareto)分析法,可以很直观的看出哪些原因造成了产品质量不合格以及哪些原因比较严重。这样就可以着重解决重要的问题,明确目标,更易于操作。
另一种表述方式
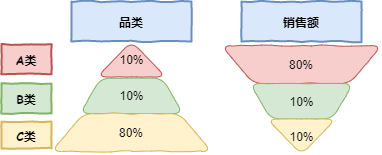
根据事物在技术或经济方面的主要特征,进行分类,分清重点与非重点。对每一种分类进行区别对待管理,把被分析的对象分成 A、B、C 三类,三类物品没有明确的划分数值界限。
| 分类与重要程度 | 描述 |
|---|---|
| A类(非常重要) | 数量占比少,价值占比大 |
| B类(比较重要) | 没有A类那么重要,介于 A、C 之间 |
| C类(一般重要) | 数量占比大但价值占比很小 |
分类的核心思想:少数贡献了大部分价值。以商品品类和销售额为例:A 品类数量占总体 10% ,却贡献了 80% 的销售额。
数据分析案例
效果图
实现步骤
假设有如下数据集格式:
| 品牌 | 销售额 |
|---|---|
| NEW BALANCE(新百伦) | 8750 |
| ZIPPO(之宝) | 9760 |
| OCTMAMI(十月妈咪) | 5800 |
需要将数据加工成下面的格式:
| 品牌 | 销售额 | 销售总额 | 累计销售额 | 累计销售额占比 |
|---|---|---|---|---|
| =∑所有品牌销售额 | =当前品牌销售额 +上一个品牌销售额 | 累计销售额/销售总额 |
具体的SQL实现如下:
SELECT
brand, -- 品牌
total_money, -- 销售额
sum(total_money) over() AS sum_total_money,-- 销售总额
sum(total_money) over(ORDER BY total_money DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS acc_sum_total_money -- 累计销售额
FROM sales_money
上面给出了具体的SQL实现,其实BI工具已经内置了许多的处理函数和拖拽式的数据处理,不需要写SQL也可以将一份明细数据加工成上面的形式。
结论分析
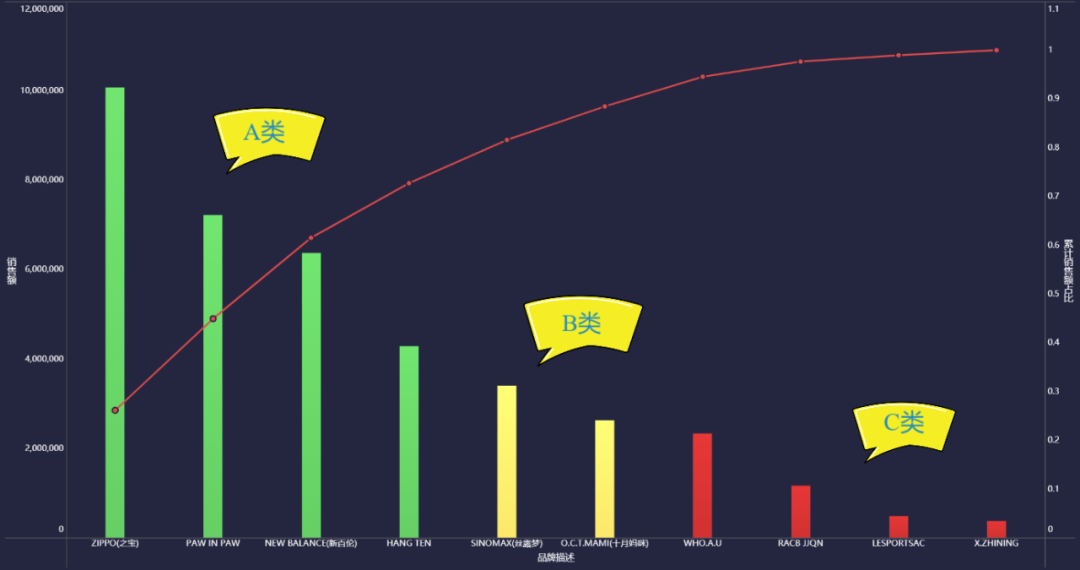
从上面的帕累托图中可以看出:A类的(绿色部分)占了总销售额的80%左右,B类(黄色部分)占总销售额的10%,C类(红色部分)占总销售额的10%。接下来可以进行长尾分析,制定营销策略等等。
RFM分析与数据可视化
基本概念
RFM模型是在客户关系管理(CRM)中常用到的一个模型,RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱三项指标来描述该客户的价值状况。
RFM模型较为动态地层示了一个客户的全部轮廓,这对个性化的沟通和服务提供了依据,同时,如果与该客户打交道的时间足够长,也能够较为精确地判断该客户的长期价值(甚至是终身价值),通过改善三项指标的状况,从而为更多的营销决策提供支持。
在RFM模式中,包括三个关键的因素,分别为:
R(Recency):表示客户最近一次购买的时间有多远,即最近的一次消费,消费时间越近的客户价值越大 F(Frequency):表示客户在最近一段时间内购买的次数,即消费频率,经常购买的用户也就是熟客,价值肯定比偶尔来一次的客户价值大 M (Monetary):表示客户在最近一段时间内购买的金额,即客户的消费能力,通常以客户单次的平均消费金额作为衡量指标,消费越多的用户价值越大。
最近一次消费、消费频率、消费金额是测算消费者价值最重要也是最容易的方法,这充分的表现了这三个指标对营销活动的指导意义。而其中,最近一次消费是最有力的预测指标。
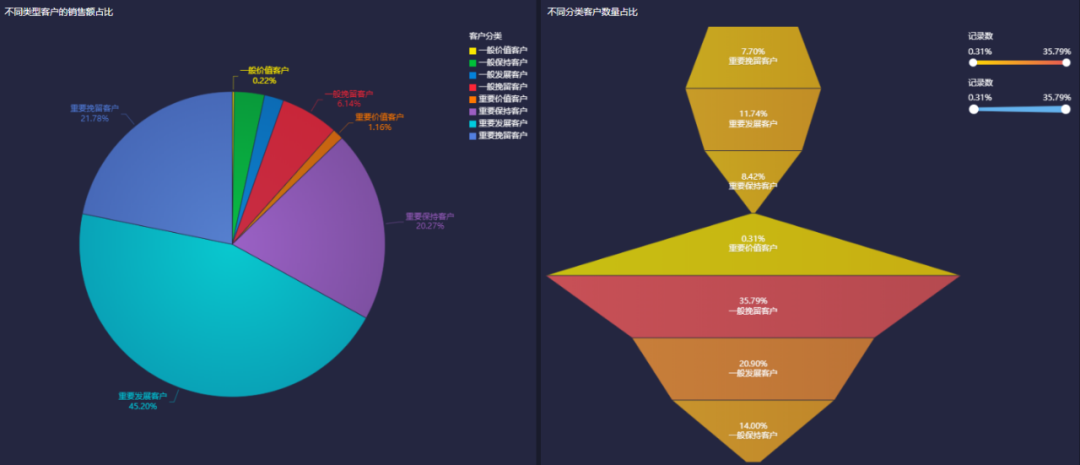
通过上面分析可以对客户群体进行分类:
| 客户类型与等级 | R | F | M | 客户特征 |
|---|---|---|---|---|
| 重要价值客户 (A级/111) | 高(1) | 高(1) | 高(1) | 最近消费时间近、消费频次和消费金额都很高 |
| 重要发展客户 (A级/101) | 高(1) | 低(0) | 高(1) | 最近消费时间较近、消费金额高,但频次不高,忠诚度不高,很有潜力的用户,必须重点发展 |
| 重要保持客户 (B级/011) | 低(0) | 高(1) | 高(1) | 最近消费时间交远,消费金额和频次都很高。 |
| 重要挽留客户 (B级/001) | 低(0) | 低(0) | 高(1) | 最近消费时间较远、消费频次不高,但消费金额高的用户,可能是将要流失或者已经要流失的用户,应当基于挽留措施。 |
| 一般价值客户 (B级/110) | 高(1) | 高(1) | 低(0) | 最近消费时间近,频率高,但消费金额低,需要提高其客单价。 |
| 一般发展客户 (B级/100) | 高(1) | 低(0) | 低(0) | 最近消费时间较近、消费金额,频次都不高。 |
| 一般保持客户 (C级/010) | 低(0) | 高(1) | 低(0) | 最近消费时间较远、消费频次高,但金额不高。 |
| 一般挽留客户 (C级/000) | 低(0) | 低(0) | 低(0) | 都很低 |
数据分析案例
效果图
实现步骤
假设有如下的样例数据:
| 客户名称 | 日期 | 消费金额 | 消费数量 |
|---|---|---|---|
| 上海****有限公司 | 2020-05-20 | 76802 | 2630 |
需要将数据集加工成如下格式:

具体SQL实现
SELECT
customer_name,-- 客户名称
customer_avg_money,-- 当前客户的平均消费金额
customer_frequency, -- 当前客户的消费频次
total_frequency,-- 所有客户的总消费频次
total_avg_frequency, -- 所有客户平均消费频次
customer_recency_diff, -- 当前客户最近一次消费日期与当前日期差值
total_recency, -- 所有客户最近一次消费日期与当前日期差值的平均值
monetary,-- 消费金额向量化
frequency, -- 消费频次向量化
recency, -- 最近消费向量化
rfm, -- rfm
CASE
WHEN rfm = "111" THEN "重要价值客户"
WHEN rfm = "101" THEN "重要发展客户"
WHEN rfm = "011" THEN "重要保持客户"
WHEN rfm = "001" THEN "重要挽留客户"
WHEN rfm = "110" THEN "一般价值客户"
WHEN rfm = "100" THEN "一般发展客户"
WHEN rfm = "010" THEN "一般保持客户"
WHEN rfm = "000" THEN "一般挽留客户"
END AS rfm_text
FROM
(SELECT
customer_name,-- 客户名称
customer_avg_money,-- 当前客户的平均消费金额
customer_frequency, -- 当前客户的消费频次
total_avg_money ,-- 所有客户的平均消费总额
total_frequency,-- 所有客户的总消费频次
total_frequency / count(*) over() AS total_avg_frequency, -- 所有客户平均消费频次
customer_recency_diff, -- 当前客户最近一次消费日期与当前日期差值
avg(customer_recency_diff) over() AS total_recency, -- 所有客户最近一次消费日期与当前日期差值的平均值
if(customer_avg_money > total_avg_money,1,0) AS monetary, -- 消费金额向量化
if(customer_frequency > total_frequency / count(*) over(),1,0) AS frequency, -- 消费频次向量化
if(customer_recency_diff > avg(customer_recency_diff) over(),0,1) AS recency, -- 最近消费向量化
concat(if(customer_recency_diff > avg(customer_recency_diff) over(),0,1),if(customer_frequency > total_frequency / count(*) over(),1,0),if(customer_avg_money > total_avg_money,1,0)) AS rfm
FROM
(SELECT
customer_name, -- 客户名称
max(customer_avg_money) AS customer_avg_money , -- 当前客户的平均消费金额
max(customer_frequency) AS customer_frequency, -- 当前客户的消费频次
max(total_avg_money) AS total_avg_money ,-- 所有客户的平均消费总额
max(total_frequency) AS total_frequency,-- 所有客户的总消费频次
datediff(CURRENT_DATE,max(customer_recency)) AS customer_recency_diff -- 当前客户最近一次消费日期与当前日期差值
FROM
(SELECT
customer_name, -- 客户名称
avg(money) over(partition BY customer_name) AS customer_avg_money, -- 当前客户的平均消费金额
count(amount) over(partition BY customer_name) AS customer_frequency, -- 当前客户的消费频次
avg(money) over() AS total_avg_money,-- 所有客户的平均消费总额
count(amount) over() AS total_frequency, --所有客户的总消费频次
max(sale_date) over(partition BY customer_name) AS customer_recency -- 当前客户最近一次消费日期
FROM customer_sales) t1
GROUP BY customer_name)t2) t3
通过上面的分析,可以为相对应的客户打上客户特征标签,这样就可以针对某类客户指定不同的营销策略。
波士顿矩阵与数据可视化
基本概念
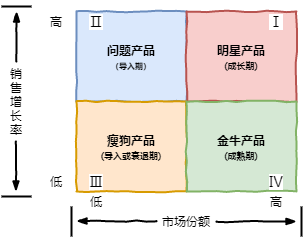
波士顿矩阵BCG Matrix又称市场增长率-相对市场份额矩阵、波士顿咨询集团法、四象限分析法、产品系列结构管理法等。
BCG矩阵区分出4种业务组合:
1.明星型业务(Stars,指高增长、高市场份额) 2.问题型业务(Question Marks,指高增长、低市场份额) 3.现金牛业务(Cash cows,指低增长、高市场份额) 4.瘦狗型业务(Dogs,指低增长、低市场份额)
波士顿矩阵通过销售增长率(反映市场引力的指标)和市场占有率(反映企业实力的指标)来分析决定企业的产品结构。
案例
效果图
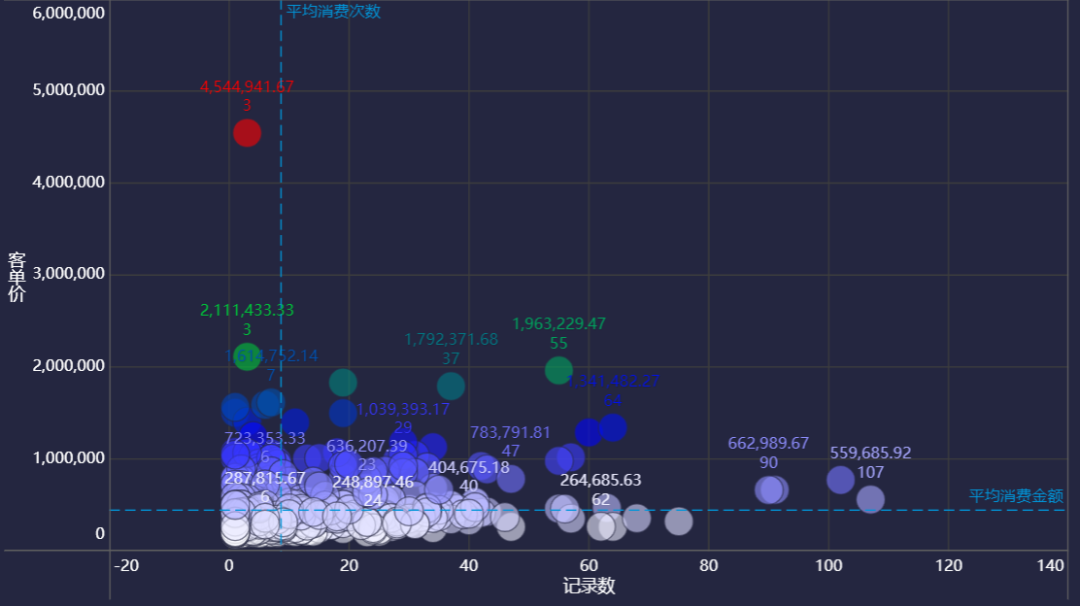
实现步骤
本案例以分析客户为背景,将客户分类,找到明星客户、现金牛客户、问题客户以及瘦狗客户。
假设数据集的样式如下:
| 客户类型 | 客户名称 | 消费金额 | 消费日期 |
|---|---|---|---|
| A类 | 上海****公司 | 20000 | 2020-05-30 |
首先需要计算客单价:每个客户的平均消费金额,即客单价=某客户总消费金额)/某客户消费次数
其次需要计算记录数:每个客户的消费次数,即某个客户总共消费的次数
接着需要计算平均消费金额:所有客户的平均消费金额,即所有客户的总消费金额/所有客户消费次数
最后计算平均消费次数:所有客户的平均消费次数,即所有客户的总消费次数/总客户数
具体SQL实现:
SELECT
customer_name, -- 客户名称
customer_avg_money, -- 客单价
customer_frequency , -- 当前客户的消费次数
total_avg_money,-- 所有客户的平均消费金额
total_frequency / count(*) over() AS total_avg_frequency -- 平均消费次数
FROM
(SELECT
customer_name, -- 客户名称
max(customer_avg_money) AS customer_avg_money, -- 客单价
max(customer_frequency) AS customer_frequency , -- 当前客户的消费次数
max(total_avg_money) AS total_avg_money,-- 所有客户的平均消费金额
max(total_frequency) AS total_frequency --所有客户的总消费频次
FROM
(
SELECT
customer_name, -- 客户名称
avg(money) over(partition BY customer_name) AS customer_avg_money, -- 客单价
count(*) over(partition BY customer_name) AS customer_frequency, -- 当前客户的消费次数
avg(money) over() AS total_avg_money,-- 所有客户的平均消费金额
count(*) over() AS total_frequency --所有客户的总消费频次
FROM customer_sales ) t1
GROUP BY customer_name) t2
经过上面的分析,大致可以看出客户画像:
某客户的消费次数超过平均值,并且每次消费力度(客单价)也超过平均水平的客户:判定为明星客户,这类客户需要重点关注; 某客户的消费次数超过平均值,但每次消费力度未达到平均水平的客户:被判定为现金牛客户,这类客户通常消费频次比较频繁,能给企业带来较为稳定的现金流,这类客户是企业利润基石; 某客户的消费次数未达到平均值,但每次消费力度超过平均水平的客户:是问题客户,这类客户最有希望转化为明星客户,但是因为客户存在一定的潜在问题,导致消费频次不高,这类客户需要进行重点跟进和长期沟通; 消费次数未达到平均值,消费力度也未达到平均水平的客户:属于瘦狗客户,这类客户通常占企业客户的大多数,只需要一般性维护,如果企业资源有限,则可以不用投入太多的精力。
总结
本文主要介绍了数仓开发应该要了解的常见的数据分析方法,主要有三种:帕累托分析、RFM分析以及波士顿矩阵分析。本文分别介绍了三种分析方法的基本概念、操作步骤以及SQL实现,并给出了相应的可视化分析图表,每个案例都是企业的真实应用场景。希望给数仓开发的同学提供一些观察数据的分析角度,从而在实际的开发过程中能够多思考一下数据的应用价值以及数据如何赋能业务,进一步提升自己的综合能力。