
文生图模型之Emu:开启微调时代
 点蓝色字关注 “机器学习算法工程师 ”
点蓝色字关注 “机器学习算法工程师 ”
设为 星标 ,干货直达!
Meta在Meta Connect 2023大会上发布了自家的文生图模型Emu:Expressive Media Universe。值得可敬的是,Meta同时也公布了Emu的技术论文,这真要比OpenAI良心多了,要知道OpenAI近发布的DALLE 3是一点技术细节也没公开。这篇文章将简单解读一下Emu的技术报告。
写在前面
首先,Emu在技术上并没有太大的创新,它的模型架构还是基于Stable Diffusion。Emu最大的贡献是发现文生图模型在经过大规模预训练之后,使用极少量的高质量数据进行微调就可以大幅度提升生成图像的质量,而且不丢失泛化性。论文里面将这个微调称为quality-tuning,它的目标就是提升模型生成图像的美学质量。这个quality-tuning可以类比为LLMs中的instruction-tuning。大语言模型经过instruction-tuning之后文生生成质量也有一个明显的提升。而且这里的quality-tuning和LLMs中的instruction-tuning在方法上有很多类似之处:首先是都需要高质量数据,而且质量往往比数量更重要,比如Llama2使用27K高质量文本进行微调,这里的Emu仅需要2000张高质量图像(之前Meta的工作LIMA: Less Is More for Alignment使用1000个高质量文本就够了);二是经过微调后,基本没有丢失泛化性,即原来预训练阶段学习的知识没有遗忘。虽然Meta在论文中强调他们第一个指出quality-tuning对文生图模型生成图像质量的重要性。但其实自从Stable Diffusion开源之后,社区其实已经进行了大量的quality-tuning工作(即所谓的炼丹),比如C站上海量的基于开源Stable Diffusion微调的模型,只不过学术界一直没有特别重视quality-tuning。尽管quality-tuning和instruction-tuning在技术上没太多复杂性,但是要想得到好的微调模型,还是需要比较高超的“炼丹术”。所以,Meta的Emu的技术报告还是有一定的学习价值,特别是在构建高质量图像数据方面。
模型结构
Emu和Stable Diffusion一样基于latent diffusion,扩散模型的UNet参数量为2.8B,比SDXL还大一些,这是通过增加UNet的通道数和每个stage的block数量来实现(即增加网络的深度和宽度)。至于text encoder,Emu是选用了OpenAI的CLIP ViT-L和谷歌的T5-XXL(SDXL则是使用CLIP ViT-L和OpenCLIP ViT-G),根据之前Imagen的实验,采用纯文本训练的T5-XXL有助于提升文本理解能力(即生成的图像与输入文本prompt更一致)。Emu在模型结构上相比Stable Diffusion的一个改动是采用了**channel数为16的AE (autoencoder)**。Stable Diffusion所采用的AE一直是4-channel的,对于512x512x3的图像,latent的维度为64x64x4,其中下采样率为8,而channel数为4。这个AE的压缩率还是比较大的,所以会造成图像的细节丢失,具体表现就是小物体容易出现畸变,比如较小的文字和人脸,这也是为什么SDXL直接生成1024x1024的图像原因之一,因为可以在一定程度上避免AE容易畸变的问题。如果将latent的channel数增加到16,那么畸变问题就基本上缓解了,下面为一个具体的对比(用AE重建的图像): 可以看到4 channel的AE明显可以看到文字的畸变,但是16 channel的AE的文字基本无变形了。从定量指标对比来看,16 channel的AE的PSNR也是明显高于4 channel的AE:
可以看到4 channel的AE明显可以看到文字的畸变,但是16 channel的AE的文字基本无变形了。从定量指标对比来看,16 channel的AE的PSNR也是明显高于4 channel的AE:
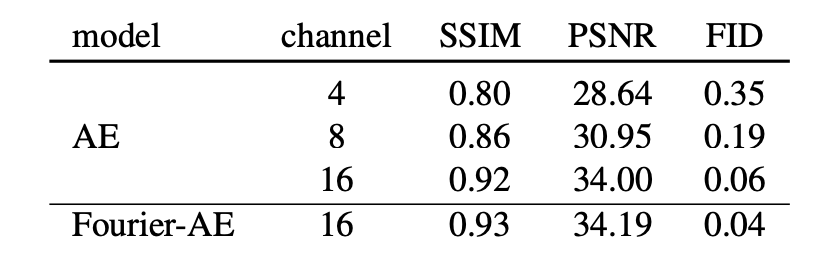 这里的Fourier-AE是使用傅立叶特征变换使RGB图像的输入特征维度增加,从而更好地增强细节,同时增加了对抗损失。Fourier-AE相比原始的AE只有微弱提升,所以增加channel数量才是最重要的。不过,使用16 channel的AE,扩散模型的训练难度会有一定增加。
这里的Fourier-AE是使用傅立叶特征变换使RGB图像的输入特征维度增加,从而更好地增强细节,同时增加了对抗损失。Fourier-AE相比原始的AE只有微弱提升,所以增加channel数量才是最重要的。不过,使用16 channel的AE,扩散模型的训练难度会有一定增加。
Pre-training
Emu的预训练数据集包含11亿个图像,但是Meta并没有说明这么大的数据集是如何构建的(估计是担心版权问题),可能是基于LAION-2B数据集,也有可能是自制的。Emu和SDXL一样都是最终生成1024x1024的图像,所以也采用了和SDXL类似的渐进式训练方案:256x256 -> 512x512 -> 1024x1024。在最后的1024x1024训练阶段(论文并没有说明是否和SDXL一样采用了多尺度训练,但很可能只是固定在1024x1024上训练),同样采用了系数为0.02的noise offset,这个是用来解决模型只能生成中等亮度的图像这个问题,这个对于生成高对比度图像是比较重要的。预训练可以看成是一个知识学习阶段,通过大量的数据让模型可以输入任意的文本来生成图像,但是由于预训练阶段所采用的数据往往噪音很大,所以预训练后得到模型往往生成的图像比较一般。这就需要后面的quality-tuning来提升模型生成图像的质量。
Quality-tuning
对于quality-tuning,最重要的是构建高质量图像数据集,对比Meta总结了三个要点:
- 用于quality-tuning的数据集可以很小,Emu最终只用了2000个高质量图像;
- 数据集中的图像质量要很高,所以很难全自动构建,需要一定的人工;
- 尽管数据集中包含的图像比较少,quality-tuning不仅可以大大提升模型生成图像的美学质量,而且也没有出现过拟合。
为了构建quality-tuning的数据集,Meta从数十亿张图像开始,经过自动筛查和人工筛查,最终只得到2000张高质量图像。这个筛选还是相当凶残的,也怪不得论文的题目用了“大海捞针”(Needles in a Haystack)来描述这个过程。第一步是自动筛选,这个过程是使用一些自动化的方法来进行数据过滤,不涉及到人工。首先是使用一些常规的过滤器进行过滤,主要包括:攻击性内容删除(即NSFW检测),美学评分过滤(应该类似laion aesthetic score),通过OCR来过滤掉文字过多的图像,通过CLIP score来过滤掉文本和图像一致性差的图像。这些都是文生图模型训练最常采用的数据过滤方法,这个过程将数十亿张图像(这个数据的来源也未交代,应该就是预训练数据)减少到只有几亿。然后再通过图像的大小和长宽比来过滤图像,这个也是常规做法。接着是采用一个图像分类器来获取图像的所属领域和类别,比如肖像、食物、动物、风景、汽车等,这个主要为了平衡数据集的分布以保证多样性。最后是基于图像的自有属性比如喜欢数来将数据量减少至200K(从这里可以猜测Meta可能是基于自己的社交产品来构建的数据集,毕竟喜欢数这些属于比较隐私的数据)。第二步是人工筛选,这个过程主要包括两个阶段。第一个阶段是训练了一个通用的标注器(应该类似LAION Aesthetics Predictor,就是先人工标注一部分数据,然后训练一个打分模型)来将候选图像进一步减少到20K,毕竟第一阶段得到的200K还是池子有点大,所以还需要这样一个半自动化筛选来先排除一些低质量图像。第二个阶段就是完全的人工了,这里是让一些对摄影原则有深入理解的专业人士来进行高质量图像筛选,而筛选标准是基于摄影的基本原则,这个就非常专业了,具体包括:
- 构图(composition):构图这个东西有点抽象,大致是一个好的构图会主体比较突出而且画面比较均衡。摄影有很多构图法,比如论文里面所提到的“三分构图法”,就是用两条竖线和两条横线分割画面得到4个交叉点,将画面重点或者主体放在4个交叉点中的一个,比如下图中的树:
 对于构图,论文也举了一些反例,比如拍摄主体都在集中在画面的一侧,拍摄角度不好,拍摄对象被遮挡,或者周围不重要的物体分散了拍摄对象的注意力,这些都造成了视觉失衡。
对于构图,论文也举了一些反例,比如拍摄主体都在集中在画面的一侧,拍摄角度不好,拍摄对象被遮挡,或者周围不重要的物体分散了拍摄对象的注意力,这些都造成了视觉失衡。
- 灯光(lighting):这里主要是找那些具有平衡曝光的动态灯光,比如来自某个角度的灯光突出了所选的主体(有点难理解)。反例是人工或暗淡的灯光,以及过暗或过曝的灯光。
- 颜色和对比度(color and contrast)。正例是色彩鲜艳和对比高的图像。反例是单色图像或单一颜色占主导的图像。
- 主体和背景(subject and background):主体应该要突出,而且细节丰富;背景要简洁也不能过分简单或者单调,而且要和主体之间有一定的深度感。
- 额外的主观评价(additional subjective assessments):除此之外,还通过设置额外的问题还收集筛选员对图像的主体评价,比如这个图像是否是您见过的针对该特定内容的最佳照片之一吗?
从上述的筛选原则可以看到,这件事真的只有靠专业人士来完成,普通人没有经过学习和训练估计做不了这个工作。下图为筛选出来的一些示例图,可以看到图像的视觉质量确实比较高: 经过人工筛选后最后只得到了2000张图像,对于每个图像,需要人工来生成文本描述。一个细节是这2000张图像中有一部分图像的分辨率是低于1024x1024的,所以需要采用一个超分模型来提升图像的分辨率,这是采用的超分模型是参考Imagen训练的pixel diffusion upsampler(不太明白为啥在筛选时不增加对分辨率的严格控制,而是要采用超分)。在quality-tuning阶段,训练的batch size比较小只有64(预训练阶段的batch size一般较大,常用的是2048),同时采用0.1的noise offset。另外一个重要的点是训练步数不能太大,这里采用的是15K,在很小的数据集上微调模型如果训练足够久必然是会过拟合的,这个训练步数需要做一定的实验才能确定。另外一个比较重要的参数是学习速率,在微调的时候学习速率一般也要采用相对小的值,不过论文并没有特别说明。
经过人工筛选后最后只得到了2000张图像,对于每个图像,需要人工来生成文本描述。一个细节是这2000张图像中有一部分图像的分辨率是低于1024x1024的,所以需要采用一个超分模型来提升图像的分辨率,这是采用的超分模型是参考Imagen训练的pixel diffusion upsampler(不太明白为啥在筛选时不增加对分辨率的严格控制,而是要采用超分)。在quality-tuning阶段,训练的batch size比较小只有64(预训练阶段的batch size一般较大,常用的是2048),同时采用0.1的noise offset。另外一个重要的点是训练步数不能太大,这里采用的是15K,在很小的数据集上微调模型如果训练足够久必然是会过拟合的,这个训练步数需要做一定的实验才能确定。另外一个比较重要的参数是学习速率,在微调的时候学习速率一般也要采用相对小的值,不过论文并没有特别说明。
模型评测
文生图模型的评测一般包括两个方面:生成图像的质量,以及生成的图像和文本的一致性。Emu论文中采用的两个评测指标:visual appeal和text faithfulness,其实对应的就是上述两者。Imagen论文中的叫法是sample quality和image-text alignment,虽然大家的叫法不同,但是所表述的含义都是一样的。对于图像质量,常采用的指标是FID,但是这个指标往往和人工评测结果相关性较弱,所以FID越低不代表模型生成的图像质量就高;对于图像和文本的一致性,常采用的指标是CLIP score,但是这个指标也不是那么可靠。鉴于此,Emu直接采用了人工评测(SDXL也是直接采用人工评测),这里是单独对两个方面分别评测,就是说在评测图像质量时,让参与者忽略图像和文本的一致性,而反之亦然。评测共采用了两套文本prompts:一个是包含1600个prompts的PartiPrompts,一个是自己构建的包含2100个prompts的OUI Prompts。前者是谷歌的Parti中所采用的评测集,而后者是Meta基于真实应用场景所收集的评测集,它包含了大家比较常用的类别和概念,具体分布如下所示: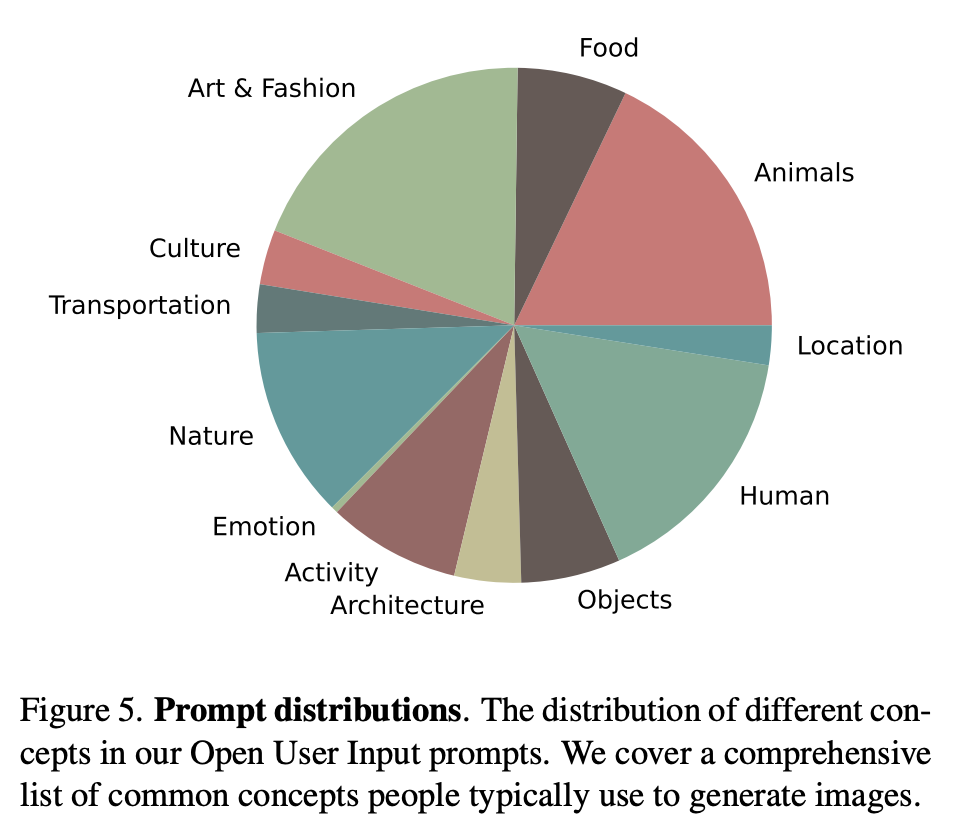 这里首先对比的是quality-tuning前后的模型,如下图所示,可以看到在两个评测集上,quality-tuning之后的模型在图像质量有明显的提升,同时在图像和文本的一致性上也有一定的提升。这说明适当的quality-tuning可以在提升生成图像质量的同时不丢失原来的泛化性。(这里的stylized prompts是评测集中风格化的子集,比如草图和漫画,这个对比可以说明提升是比较全面的)。
这里首先对比的是quality-tuning前后的模型,如下图所示,可以看到在两个评测集上,quality-tuning之后的模型在图像质量有明显的提升,同时在图像和文本的一致性上也有一定的提升。这说明适当的quality-tuning可以在提升生成图像质量的同时不丢失原来的泛化性。(这里的stylized prompts是评测集中风格化的子集,比如草图和漫画,这个对比可以说明提升是比较全面的)。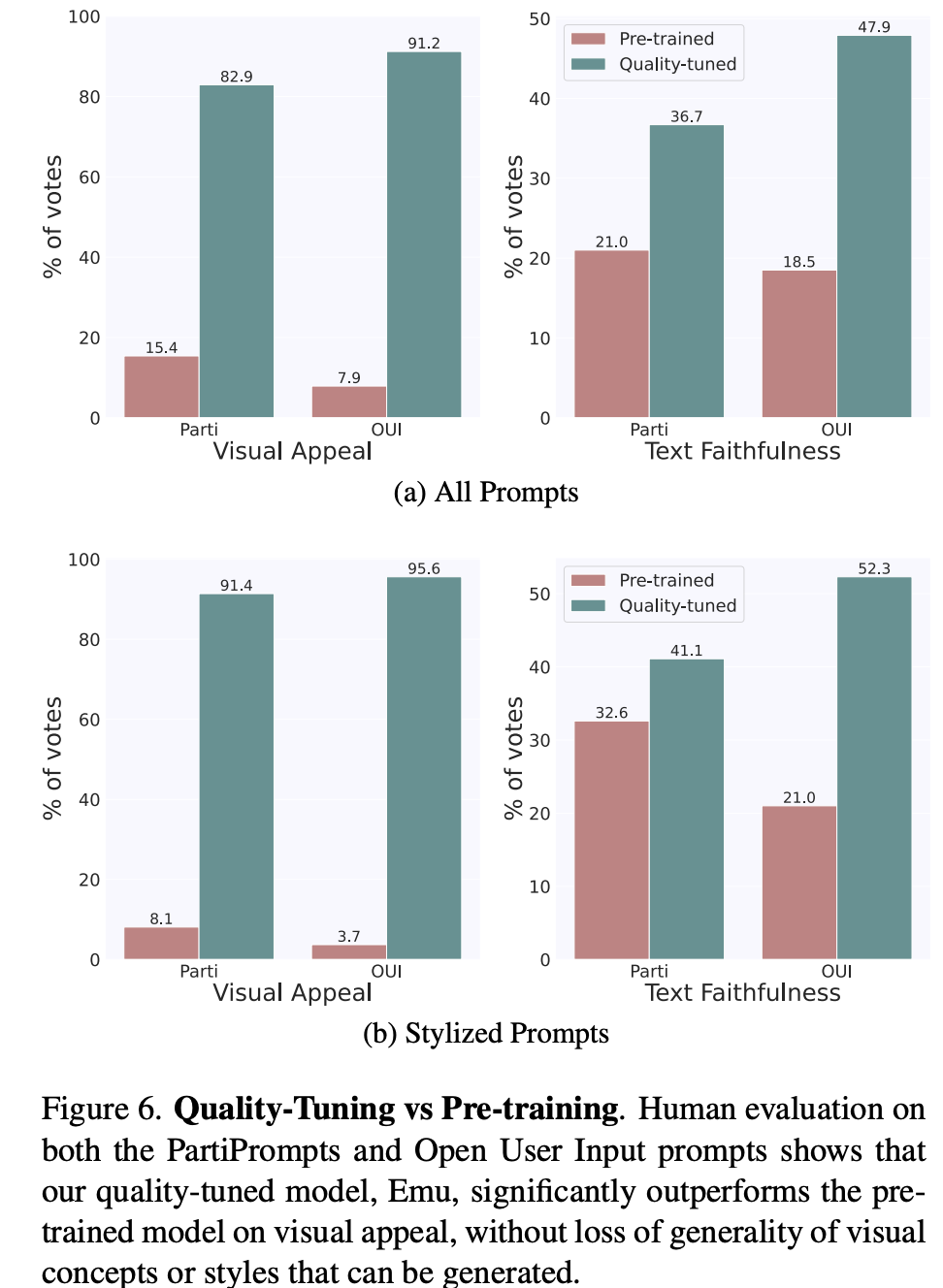 对于图像和文本的一致性方面的提升,这应该是归功于这2000张高质量图像的文本描述是人工生成的,相比预训练数据集的标注噪音很小。下面展示了几个具体的生成图像对比,可以看到经过quality-tuning之后,生成图像的质量确实有明显的提升,而且美感也和用于quality-tuning训练的高质量图像比较类似。
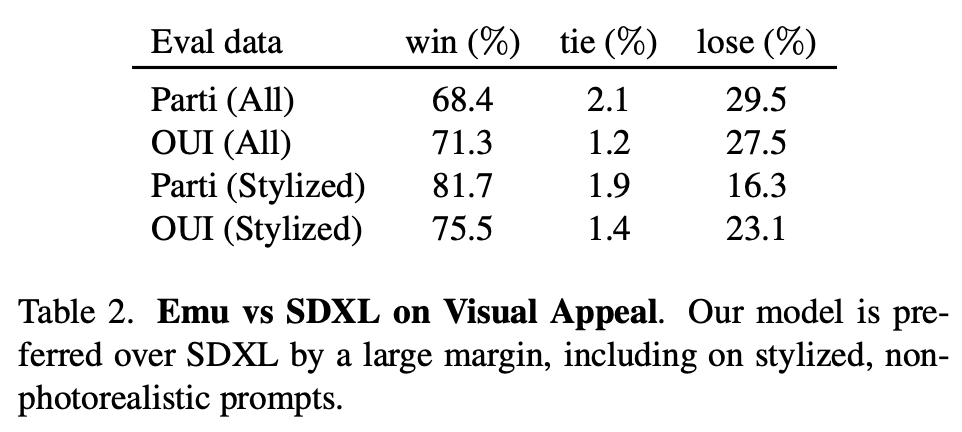
对于图像和文本的一致性方面的提升,这应该是归功于这2000张高质量图像的文本描述是人工生成的,相比预训练数据集的标注噪音很小。下面展示了几个具体的生成图像对比,可以看到经过quality-tuning之后,生成图像的质量确实有明显的提升,而且美感也和用于quality-tuning训练的高质量图像比较类似。 论文还将Emu和SDXL进行了对比,可以看到Emu在图像质量上也明显优于SDXL(毕竟SDXL没有进行quality-tuning)。
论文还将Emu和SDXL进行了对比,可以看到Emu在图像质量上也明显优于SDXL(毕竟SDXL没有进行quality-tuning)。
 另外,论文还进行了数据量的实验,如下表所示,可以看到只需要100张高质量图像,模型的生成质量就有一个明显的提升,这说明数据并不需要太多。不过,这里缺少的是数据量更大(超过2000张)的实验,2000可能并不是最佳值。
另外,论文还进行了数据量的实验,如下表所示,可以看到只需要100张高质量图像,模型的生成质量就有一个明显的提升,这说明数据并不需要太多。不过,这里缺少的是数据量更大(超过2000张)的实验,2000可能并不是最佳值。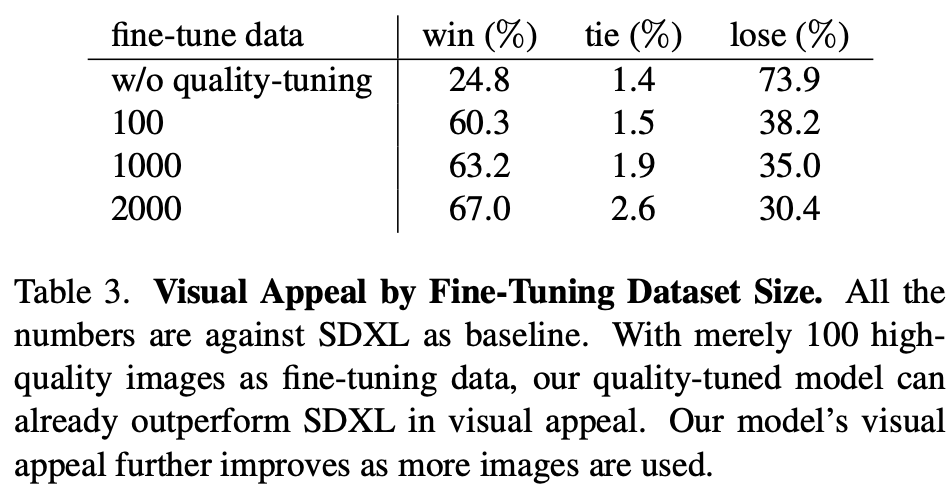
quality-tuning是通用的,它不仅可以应用在latent diffusion文生图模型上,也可以应用在pixel diffusion(参考谷歌的Imagen)和masked generative transformer(参考谷歌的Muse)架构上: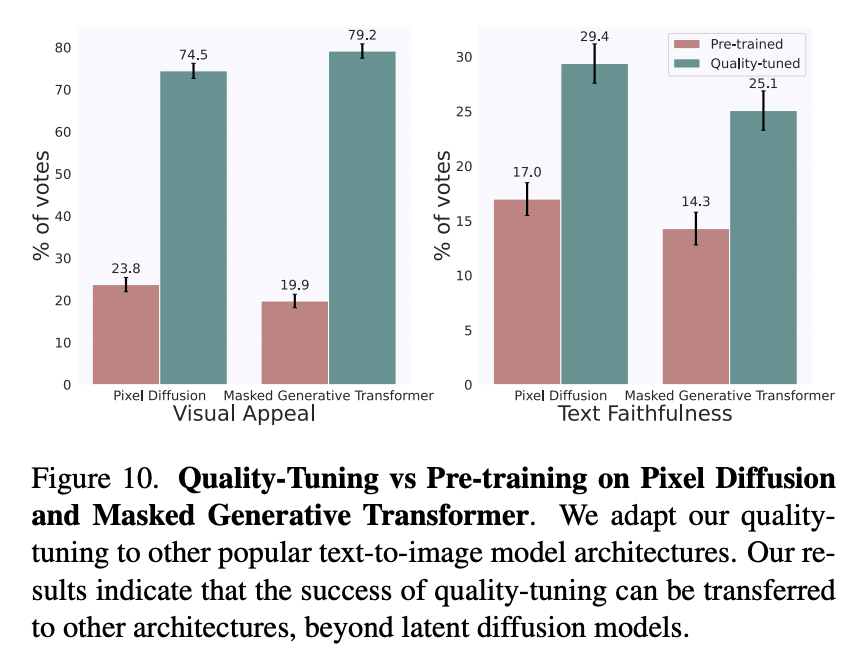 下面展示了更多的生成样例,可以看出生成图像的质量还是非常高的:
下面展示了更多的生成样例,可以看出生成图像的质量还是非常高的:
 image.png
image.png
结语
正如前言所说,学术界在文生图方面的大部分的工作主要是提升基底模型(即pre-training模型)以及一些个性化生成(如DreamBooth)和可控生成(如ControlNet),但是对于quality-tuning方面却比较少(虽然之前有少部分工作通过强化学习来提升模型,但并没有太惊艳),而社区早已经大量使用quality-tuning了,相信这个工作之后会有更多的关于quality-tuning的学术论文。另外我也非常赞同论文中所提到的一个观点:
Our hypothesis is that a strongly pre-trained model is already capable of generating highly aesthetic images, but the generation process is not properly guided towards always producing images with these statistics. Quality-tuning effectively restricts outputs to a high-quality subset.
这就是说预训练模型其实很强大,它本身已经具有生成高质量样本的能力,但是由于预训练数据往往噪音很大,使得预训练模型在实际生成中往往更容易生成低质量样本。而quality-tuning所做的就是通过适当的微调将预训练模型收缩到高质量空间,这个引导可能并不需要太大的数据量。对于LLMs,我觉得这个观点也是适用的。所以,预训练模型其实还是相当重要的,它其实在一定程度上决定了上限,因为基于少量数据的微调只是一种引导,并不太可能在模型中引入新的知识。当然,要找到这个高质量空间,还是需要比较多的tricks,炼丹也是很重要。
参考
- https://ai.meta.com/research/publications/emu-enhancing-image-generation-models-using-photogenic-needles-in-a-haystack/
- Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
推荐阅读
使用PyTorch 2.0加速Transformer:训练推理均拿下!
机器学习算法工程师
一个用心的公众号
