浅析eslint原理
在前端开发过程中,eslint规范已经成为必不可少的一环,我们需要eslint来保证代码规范,相对统一同学们的代码风格,不然就会出现所有同学都随意引入自己偏好的风格或者规范,让所有人一起分担引入规范的代价。
同时,有些lint规则可以避免bug的产生,在提高代码可读性的前提下,减少问题数量,将问题更多的暴露在开发阶段。
一、eslint的规则
说起eslint,第一想到的就是eslints里面的每条规则,我们通过以下简单的配置就可以来控制规则的开启及关闭。其中:0 1 2 分别对应 'off' 'warn' 'error';如果是个数组,第二个参数可以自定义配置。
{
"rules": {
"arrow-body-style" : 0, // 0 1 2
"quotes" : [ "error" , "single" ]
}
}
其中rules的每一个key就是对应的一条规则,透过使用去思考,eslint如何去实现的这条规则呢?🤔
eslint的核心rules
eslint 的核心就是 rules,理解一个 rule 的结构对于理解 eslint 的原理和创建自定义规则非常重要。
我们看一下自定义eslint 规则[1] 再结合目前已有的某条规则来分析
看一下最简单的一条规则 no-with
module.exports = {
meta: { // 包含规则的元数据
// 指示规则的类型,值为 "problem"、"suggestion" 或 "layout"
type: "suggestion",
docs: { // 对 ESLint 核心规则来说是必需的
description: "disallow `with` statements", // 提供规则的简短描述在规则首页展示
// category (string) 指定规则在规则首页处于的分类
recommended: true, // 配置文件中的 "extends": "eslint:recommended"属性是否启用该规则
url: "https://eslint.org/docs/rules/no-with" // 指定可以访问完整文档的 url
},
// fixable 如果没有 fixable 属性,即使规则实现了 fix 功能,ESLint 也不会进行修复。如果规则不是可修复的,就省略 fixable 属性。
schema: [], // 指定该选项 这样的 ESLint 可以避免无效的规则配置
// deprecated (boolean) 表明规则是已被弃用。如果规则尚未被弃用,你可以省略 deprecated 属性。
messages: {
unexpectedWith: "Unexpected use of 'with' statement."
}
},
// create (function) 返回一个对象,其中包含了 ESLint 在遍历 js 代码的抽象语法树 AST (ESTree 定义的 AST) 时,用来访问节点的方法。
create(context) {
// 如果一个 key 是个节点类型或 selector,在 向下 遍历树时,ESLint 调用 visitor 函数
// 如果一个 key 是个节点类型或 selector,并带有 :exit,在 向上 遍历树时,ESLint 调用 visitor 函数
// 如果一个 key 是个事件名字,ESLint 为代码路径分析调用 handler 函数
// selector 类型可以到 estree 查找
return {
// 入参为节点node
WithStatement(node) {
context.report({ node, messageId: "unexpectedWith" });
}
};
}
};
有两部分组成:meta create;
meta:(对象)包含规则的元数据,包括 规则的类型,文档,是否推荐规则,是否可修复等信息;
creat:(函数)返回一个对象其中包含了 ESLint 在遍历 JavaScript 代码的抽象语法树 AST (ESTree[2] 定义的 AST) 时,用来访问节点的方法,入参为该节点。
如果一个 key 是个节点类型或 selector[3],在 向下 遍历树时,ESLint 调用 visitor 函数 如果一个 key 是个节点类型或 selector[4],并带有 :exit,在 向上 遍历树时,ESLint 调用 visitor 函数如果一个 key 是个事件名字,ESLint 为代码路径分析[5]调用 handler 函数
二、eslint 命令的执行
在package.json里配置bin
"bin": {
"eslint": "bin/eslint.js" // 告诉 npm 你的命令是什么
}
然后创建对应的文件
#!/usr/bin/env node
console.log("console.log output")
这就是eslint命令行的入口
(async function main() {
// 监听异常处理
process.on("uncaughtException", onFatalError);
process.on("unhandledRejection", onFatalError);
// 如果参数有 --init 就执行初始化
if (process.argv.includes("--init")) {
await require("../lib/init/config-initializer").initializeConfig();
return;
}
// 否则就执行 检查代码的代码
process.exitCode = await require("../lib/cli").execute(
process.argv,
process.argv.includes("--stdin") ? await readStdin() : null
);
}()).catch(onFatalError);
代码检查的函数是 cli.execute() ****从lib中引入的cli对象。
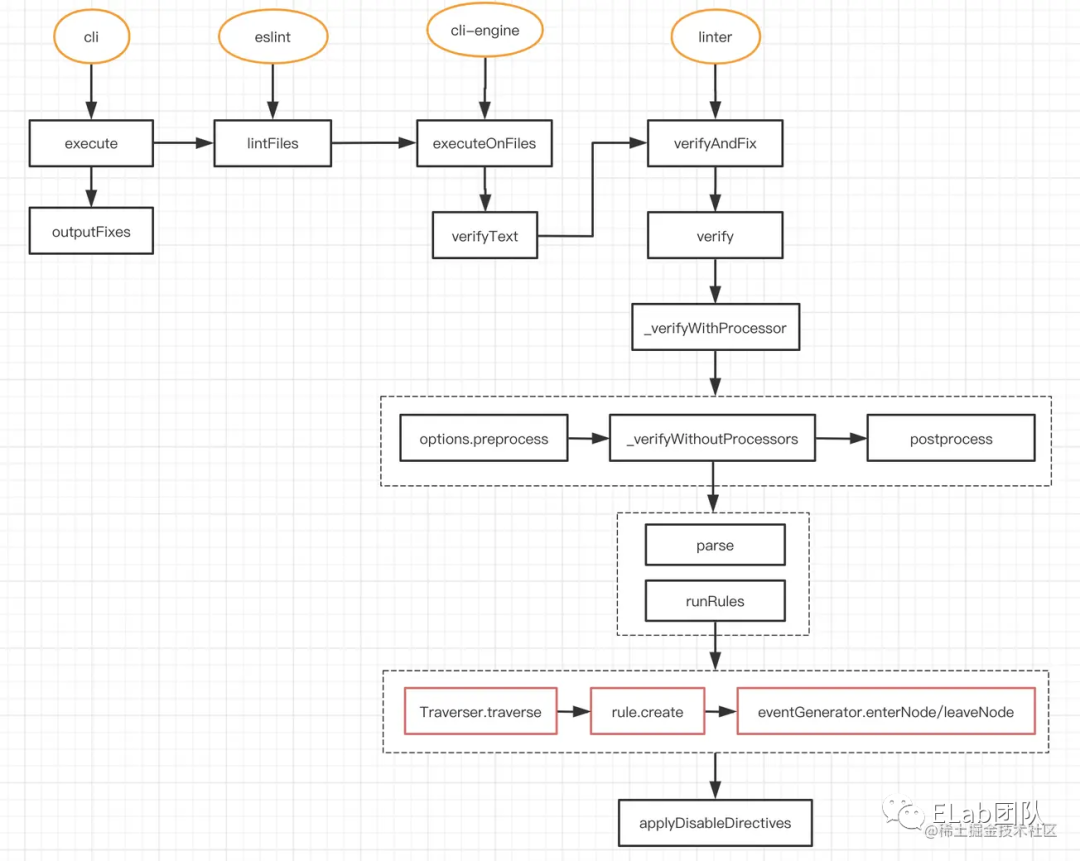
三、eslint 执行的调用栈
execute() 函数
这是 eslint 的主要代码执行逻辑,主要流程如下:
解析命令行参数,校验参数正确与否及打印相关信息; 初始化 根据配置实例一个engine对象 CLIEngine实例;engine.executeOnFiles读取源代码进行检查,返回报错信息和修复结果。
execute(args, text) {
if (Array.isArray(args)) {
debug("CLI args: %o", args.slice(2));
}
let currentOptions;
try {
// 先校验参数 如果输入 --halp 提示 --help,并通过options的配置给默认值
currentOptions = options.parse(args);
} catch (error) {
log.error(error.message);
return 2;
}
const files = currentOptions._;
const useStdin = typeof text === "string";
// ---省略很多---参数校验及输出
// ...
// 根据配置实例一个engine对象
const engine = new CLIEngine(translateOptions(currentOptions));
// report 就是最后的结果
const report = useStdin ? engine.executeOnText(text, currentOptions.stdinFilename, true) : engine.executeOnFiles(files);
// ...
// ---省略很多---参数校验及输出
return 0;
}
可以看到eslint就是在执行 engine.executeOnFiles(files) 之后获得检查的结果
executeOnFiles (files) 函数
可以看到eslint就是在执行 engine.executeOnFiles(files) 之后获得检查的结果;该函数主要作用是对一组文件和目录名称执行当前配置。
简单看一下 executeOnFile s ()
该函数输入文件目录,返回lint之后的结果
主要执行逻辑如下:
fileEnumerator 类,迭代所有的文件路径及信息; 检查是否忽略的文件,lint缓存 等等一堆操作; 调用 verifyText() 函数执行检查 储存lint之后的结果
/**
* Executes the current configuration on an array of file and directory names.
* @param {string[]} patterns An array of file and directory names.
* @returns {LintReport} The results for all files that were linted.
*/
executeOnFiles(patterns) {
// .....
// fileEnumerator 类,迭代所有的文件路径及信息
for (const { config, filePath, ignored } of fileEnumerator.iterateFiles(patterns)) {
// ....... 检查是否忽略的文件,缓存 等等一堆操作
// Do lint.
const result = verifyText({
text: fs.readFileSync(filePath, "utf8"),
filePath,
config,
cwd,
fix,
allowInlineConfig,
reportUnusedDisableDirectives,
extensionRegExp: fileEnumerator.extensionRegExp,
linter
});
results.push(result);
/*
* Store the lint result in the LintResultCache.
* NOTE: The LintResultCache will remove the file source and any
* other properties that are difficult to serialize, and will
* hydrate those properties back in on future lint runs.
*/
if (lintResultCache) {
lintResultCache.setCachedLintResults(filePath, config, result);
}
}
}
verifyText() 函数
其实就是调用了 linter.verifyAndFix() 函数
verifyAndFix() 函数
这个函数是核心函数,顾名思义verify & fix
代码核心处理逻辑是通过一个 do while 循环控制;以下两个条件会打断循环
没有更多可以被fix的代码了 循环超过十次 其中 verify 函数对源代码文件进行代码检查,从规则维度返回检查结果数组 applyFixes 函数拿到上一步的返回,去fix代码 如果设置了可以fix,那么使用fix之后的结果 代替原本的text
/**
* This loop continues until one of the following is true:
*
* 1. No more fixes have been applied.
* 2. Ten passes have been made.
* That means anytime a fix is successfully applied, there will be another pass.
* Essentially, guaranteeing a minimum of two passes.
*/
do {
passNumber++; // 初始值0
// 这个函数就是 verify 在 verify 过程中会把代码转换成ast
debug(`Linting code for ${debugTextDescription} (pass ${passNumber})`);
messages = this.verify(currentText, config, options);
// 这个函数就是 fix
debug(`Generating fixed text for ${debugTextDescription} (pass ${passNumber})`);
fixedResult = SourceCodeFixer.applyFixes(currentText, messages, shouldFix);
/*
* 如果有 syntax errors 就 break.
* 'fixedResult.output' is a empty string.
*/
if (messages.length === 1 && messages[0].fatal) {
break;
}
// keep track if any fixes were ever applied - important for return value
fixed = fixed || fixedResult.fixed;
// 使用fix之后的结果 代替原本的text
currentText = fixedResult.output;
} while (
fixedResult.fixed &&
passNumber < MAX_AUTOFIX_PASSES // 10
);
在verify过程中,会调用 parse 函数,把代码转换成AST
// 默认的ast解析是espree
const espree = require("espree");
let parserName = DEFAULT_PARSER_NAME; // 'espree'
let parser = espree;
parse函数会返回两种结果 {success: false, error: Problem} 解析AST成功 {success: true, sourceCode: SourceCode} 解析AST失败
最终会调用 runRules() 函数
这个函数是代码检查和修复的核心方法,会对代码进行规则校验。
创建一个 eventEmitter 实例。是eslint自己实现的很简单的一个事件触发类 on监听 emit触发; 递归遍历 AST,深度优先搜索,把节点添加到 nodeQueue。一个node放入两次,类似于A->B->C->...->C->B->A; 遍历 rules,调用 rule.create()(rules中提到的meta和create函数) 拿到事件(selector)映射表,添加事件监听。 包装一个 ruleContext 对象,会通过参数,传给 rule.create(),其中包含 report() 函数,每个rule的 handler 都会执行这个函数,抛出问题; 调用 rule.create(ruleContext), 遍历其返回的对象,添加事件监听;(如果需要lint计时,则调用process.hrtime()计时); 遍历 nodeQueue,触发当前节点事件的回调,调用 NodeEventGenerator 实例里面的函数,触发 emitter.emit()。
// 1. 创建一个 eventEmitter 实例。是eslint自己实现的很简单的一个事件触发类 on监听 emit触发
const emitter = createEmitter();
// 2. 递归遍历 AST,把节点添加到 nodeQueue。一个node放入两次 A->B->C->...->C->B->A
Traverser.traverse(sourceCode.ast, {
enter(node, parent) {
node.parent = parent;
nodeQueue.push({ isEntering: true, node });
},
leave(node) {
nodeQueue.push({ isEntering: false, node });
},
visitorKeys: sourceCode.visitorKeys
});
// 3. 遍历 rules,调用 rule.create() 拿到事件(selector)映射表,添加事件监听。
// (这里的 configuredRules 是我们在 .eslintrc.json 设置的 rules)
Object.keys(configuredRules).forEach(ruleId => {
const severity = ConfigOps.getRuleSeverity(configuredRules[ruleId]);
// 通过ruleId拿到每个规则对应的一个对象,里面有两部分 meta & create 见 【编写rule】
const rule = ruleMapper(ruleId);
// ....
const messageIds = rule.meta && rule.meta.messages;
let reportTranslator = null;
// 这个对象比较重要,会传给 每个规则里的 rule.create函数
const ruleContext = Object.freeze(
Object.assign(
Object.create(sharedTraversalContext),
{
id: ruleId,
options: getRuleOptions(configuredRules[ruleId]),
// 每个rule的 handler 都会执行这个函数,抛出问题
report(...args) {
if (reportTranslator === null) {
reportTranslator = createReportTranslator({
ruleId,
severity,
sourceCode,
messageIds,
disableFixes
});
}
const problem = reportTranslator(...args);
// 省略一堆错误校验
// ....
// 省略一堆错误校验
// lint的结果
lintingProblems.push(problem);
}
}
)
);
// 包装了一下,其实就是 执行 rule.create(ruleContext);
// rule.create(ruleContext) 会返回一个对象,key就是事件名称
const ruleListeners = createRuleListeners(rule, ruleContext);
/**
* 在错误信息中加入ruleId
* @param {Function} ruleListener 监听到每个node,然后对应的方法rule.create(ruleContext)返回的对象中对应key的value
* @returns {Function} ruleListener wrapped in error handler
*/
function addRuleErrorHandler(ruleListener) {
return function ruleErrorHandler(...listenerArgs) {
try {
return ruleListener(...listenerArgs);
} catch (e) {
e.ruleId = ruleId;
throw e;
}
};
}
// 遍历 rule.create(ruleContext) 返回的对象,添加事件监听
Object.keys(ruleListeners).forEach(selector => {
const ruleListener = timing.enabled
? timing.time(ruleId, ruleListeners[selector]) // 调用process.hrtime()计时
: ruleListeners[selector];
// 对每一个 selector 进行监听,添加 callback
emitter.on(
selector,
addRuleErrorHandler(ruleListener)
);
});
});
// 只有顶层node类型是Program才进行代码路径分析
const eventGenerator = nodeQueue[0].node.type === "Program"
? new CodePathAnalyzer(new NodeEventGenerator(emitter, { visitorKeys: sourceCode.visitorKeys, fallback: Traverser.getKeys }))
: new NodeEventGenerator(emitter, { visitorKeys: sourceCode.visitorKeys, fallback: Traverser.getKeys });
// 4. 遍历 nodeQueue,触发当前节点事件的回调。
// 这个 nodeQueue 是前面push进所有的node,分为 入口 和 离开
nodeQueue.forEach(traversalInfo => {
currentNode = traversalInfo.node;
try {
if (traversalInfo.isEntering) {
// 调用 NodeEventGenerator 实例里面的函数
// 在这里触发 emitter.emit()
eventGenerator.enterNode(currentNode);
} else {
eventGenerator.leaveNode(currentNode);
}
} catch (err) {
err.currentNode = currentNode;
throw err;
}
});
// lint的结果
return lintingProblems;
执行节点匹配 NodeEventGenerator
在该类里面,会根据前面 nodeQueque 分别调用 进入节点和离开节点,来区分不同的调用时机。
// 进入节点 把这个node的父节点push进去
enterNode(node) {
if (node.parent) {
this.currentAncestry.unshift(node.parent);
}
this.applySelectors(node, false);
}
// 离开节点
leaveNode(node) {
this.applySelectors(node, true);
this.currentAncestry.shift();
}
// 进入还是离开 都执行的这个函数
// 调用这个函数,如果节点匹配,那么就触发事件
applySelector(node, selector) {
if (esquery.matches(node, selector.parsedSelector, this.currentAncestry, this.esqueryOptions)) {
// 触发事件,执行 handler
this.emitter.emit(selector.rawSelector, node);
}
}
四、总体运行机制
概括来说就是,ESLint 会遍历前面说到的 AST,然后在遍历到「不同的节点」或者「特定的时机」的时候,触发相应的处理函数,然后在函数中,可以抛出错误,给出提示。
Tips: espree需要更换解析器
问题:espree无法识别 TypeScript 的一些语法,所以在我们项目中的 .eslintrc.json 里才要配置
{
"parser": '@typescript-eslint/parser'
}
给eslint指定解析器,替代掉默认的解析器。
eslint 中涉及到规则的校验源码调用栈大致就如上分析,但其实eslint远不止这些,还有很多可以值得学习的点,如:迭代文件路径、fix修复文本、报告错误及自定义格式等等,欢迎感兴趣的同学一起讨论交流,也欢迎同学批评指正~
参考资料
https://zhuanlan.zhihu.com/p/53680918
https://juejin.cn/post/7054741990558138376
https://www.teqng.com/2022/03/14/%E4%BB%8E%E9%9B%B6%E5%BC%80%E5%A7%8B%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3-eslint-%E6%A0%B8%E5%BF%83%E5%8E%9F%E7%90%86/#ESLint_shi_ru_he_gong_zuo_de
我们看一下自定义eslint 规则: https://eslint.bootcss.com/docs/developer-guide/working-with-rules
[2]ESTree: https://github.com/estree/estree
[3]selector: https://eslint.bootcss.com/docs/developer-guide/selectors
[4]selector: https://eslint.bootcss.com/docs/developer-guide/selectors
[5]代码路径分析: https://eslint.bootcss.com/docs/developer-guide/code-path-analysis

往期推荐


最后
欢迎加我微信,拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...