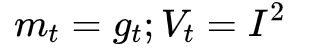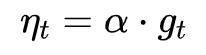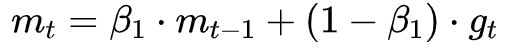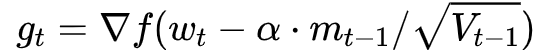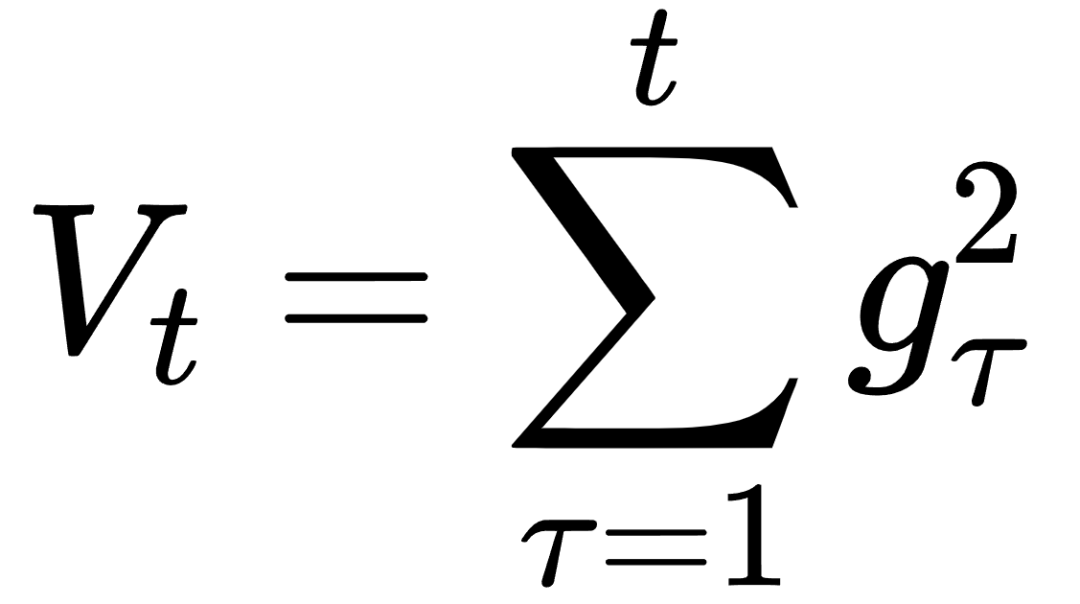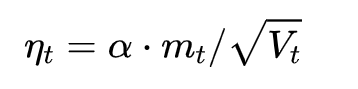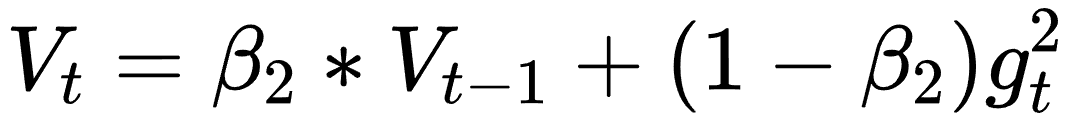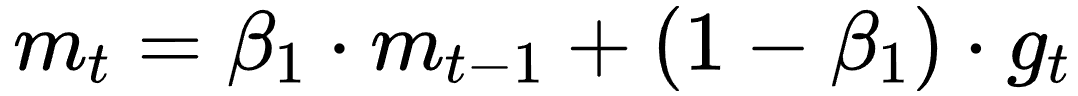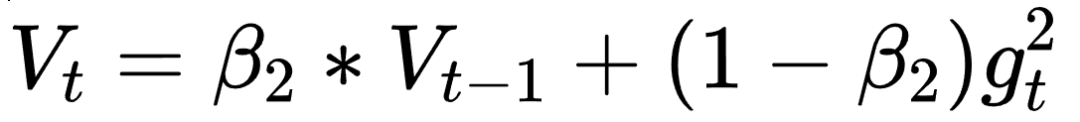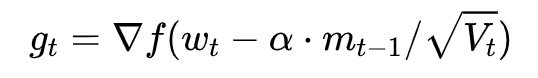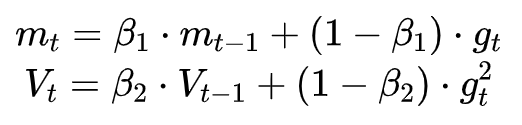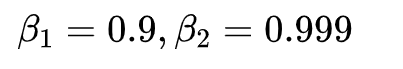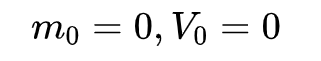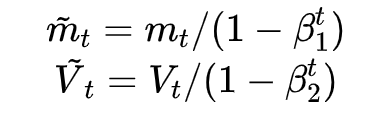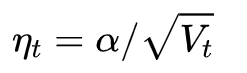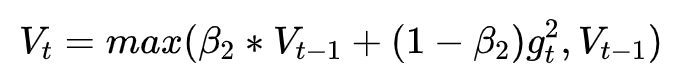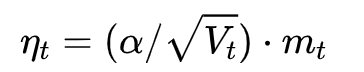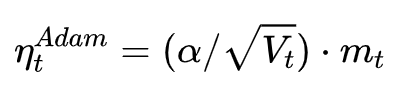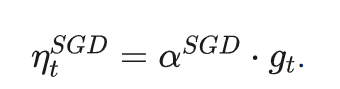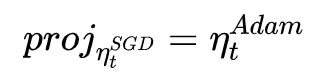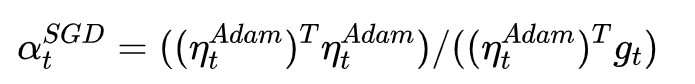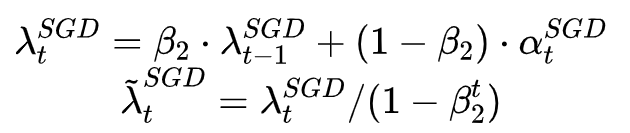Despite the fact that our experimental evidence demonstrates that adaptive methods are not advantageous for machine learning, the Adam algorithm remains incredibly popular. We are not sure exactly as to why ……
无奈与酸楚之情溢于言表。
01
一个框架回顾优化算法
首先我们来回顾一下各类优化算法。
深度学习优化算法经历了 SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam 这样的发展历程。Google一下就可以看到很多的教程文章,详细告诉你这些算法是如何一步一步演变而来的。在这里,我们换一个思路,用一个框架来梳理所有的优化算法,做一个更加高屋建瓴的对比。
深度神经网络往往包含大量的参数,在这样一个维度极高的空间内,非凸的目标函数往往起起伏伏,拥有无数个高地和洼地。有的是高峰,通过引入动量可能很容易越过;但有些是高原,可能探索很多次都出不来,于是停止了训练。 近期Arxiv上的两篇文章谈到这个问题。 第一篇就是前文提到的吐槽Adam最狠的 The Marginal Value of Adaptive Gradient Methods in Machine Learning 。文中说到,同样的一个优化问题,不同的优化算法可能会找到不同的答案,但自适应学习率的算法往往找到非常差的答案。他们通过一个特定的数据例子说明,自适应学习率算法可能会对前期出现的特征过拟合,后期才出现的特征很难纠正前期的拟合效果。 另外一篇是 Improving Generalization Performance by Switching from Adam to SGD,进行了实验验证。他们CIFAR-10数据集上进行测试,Adam的收敛速度比SGD要快,但最终收敛的结果并没有SGD好。他们进一步实验发现,主要是后期Adam的学习率太低,影响了有效的收敛。他们试着对Adam的学习率的下界进行控制,发现效果好了很多。 于是他们提出了一个用来改进Adam的方法:前期用Adam,享受Adam快速收敛的优势;后期切换到SGD,慢慢寻找最优解。这一方法以前也被研究者们用到,不过主要是根据经验来选择切换的时机和切换后的学习率。这篇文章把这一切换过程傻瓜化,给出了切换SGD的时机选择方法,以及学习率的计算方法,效果看起来也不错。
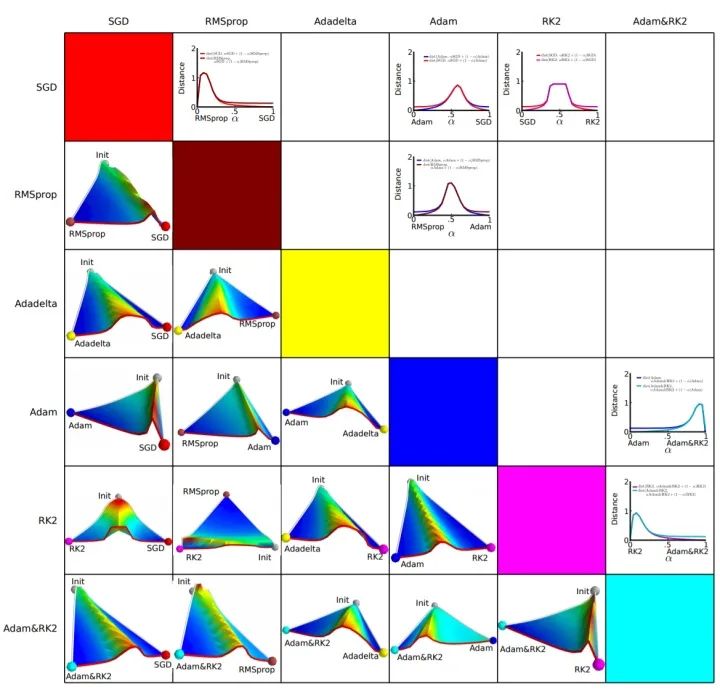
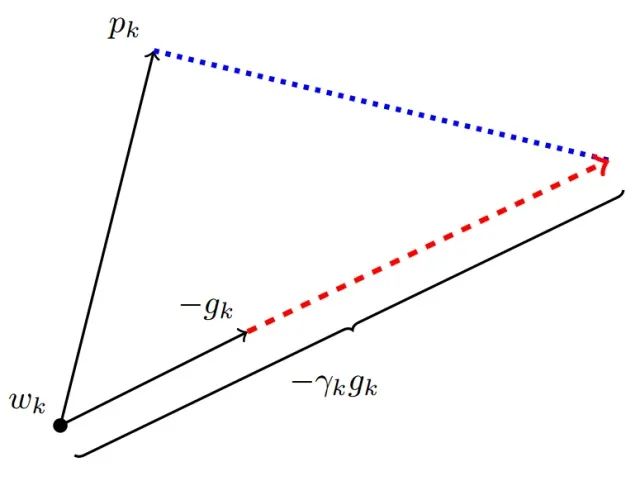
这个式子中,前半部分是实际的学习率(也即下降步长),后半部分是实际的下降方向。SGD算法的下降方向就是该位置的梯度方向的反方向,带一阶动量的SGD的下降方向则是该位置的一阶动量方向。自适应学习率类优化算法为每个参数设定了不同的学习率,在不同维度上设定不同步长,因此其下降方向是缩放过(scaled)的一阶动量方向。 由于下降方向的不同,可能导致不同算法到达完全不同的局部最优点。An empirical analysis of the optimization of deep network loss surfaces这篇论文中做了一个有趣的实验,他们把目标函数值和相应的参数形成的超平面映射到一个三维空间,这样我们可以直观地看到各个算法是如何寻找超平面上的最低点的。 上图是论文的实验结果,横纵坐标表示降维后的特征空间,区域颜色则表示目标函数值的变化,红色是高原,蓝色是洼地。他们做的是配对儿实验,让两个算法从同一个初始化位置开始出发,然后对比优化的结果。可以看到,几乎任何两个算法都走到了不同的洼地,他们中间往往隔了一个很高的高原。这就说明,不同算法在高原的时候,选择了不同的下降方向。
1. 首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑 SGD+Nesterov Momentum或者Adam.(Standford 231n : The two recommended updates to use are either SGD+Nesterov Momentum or Adam)
5. 先用小数据集进行实验。 有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。(The mathematics of stochastic gradient descent are amazingly independent of the training set size. In particular, the asymptotic SGD convergence rates are independent from the sample size. [2])因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。