
机器学习常用损失函数总览:基本形式、原理、特点
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自 | 视觉算法

目录:
-
前言 -
均方差损失 Mean Squared Error Loss -
平均绝对误差损失 Mean Absolute Error Loss -
Huber Loss -
分位数损失 Quantile Loss -
交叉熵损失 Cross Entropy Loss -
合页损失 Hinge Loss -
总结
损失函数 Loss Function 通常是针对单个训练样本而言,给定一个模型输出 和一个真实 ,损失函数输出一个实值损失
代价函数 Cost Function 通常是针对整个训练集(或者在使用 mini-batch gradient descent 时一个 mini-batch)的总损失
目标函数 Objective Function 是一个更通用的术语,表示任意希望被优化的函数,用于机器学习领域和非机器学习领域(比如运筹优化)
基本形式与原理:

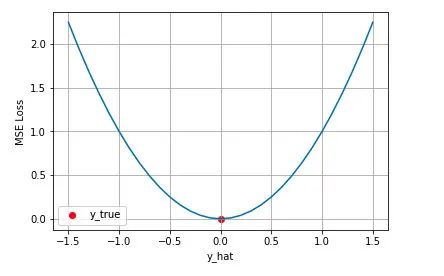
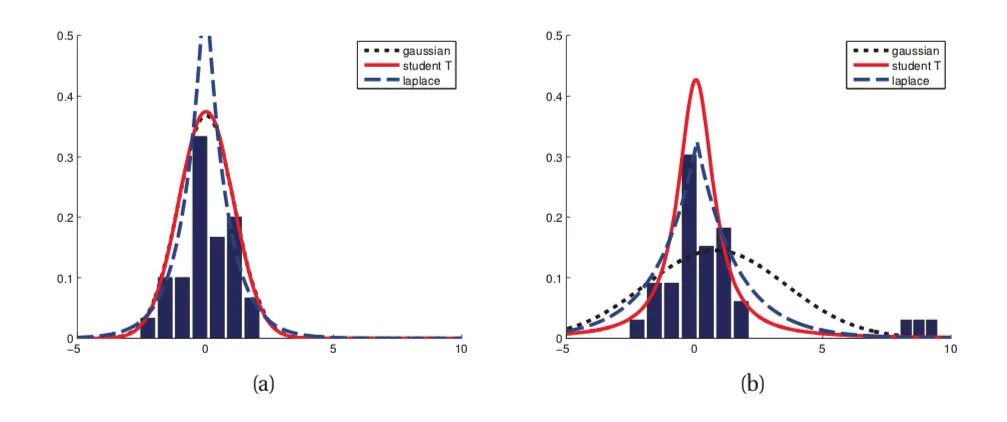
背后的假设:




因此在这个假设能被满足的场景中(比如回归),均方差损失是一个很好的损失函数选择;当这个假设没能被满足的场景中(比如分类),均方差损失不是一个好的选择。
03 平均绝对误差损失
基本形式与原理:

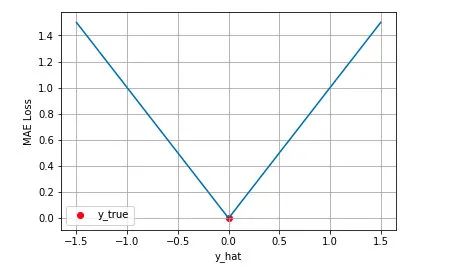
背后的假设:


MAE 与 MSE 区别:
-
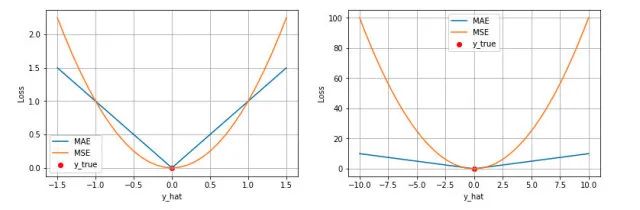
第一个角度是直观地理解,下图是 MAE 和 MSE 损失画到同一张图里面,由于MAE 损失与绝对误差之间是线性关系,MSE 损失与误差是平方关系,当误差非常大的时候,MSE 损失会远远大于 MAE 损失。因此当数据中出现一个误差非常大的 outlier 时,MSE 会产生一个非常大的损失,对模型的训练会产生较大的影响。

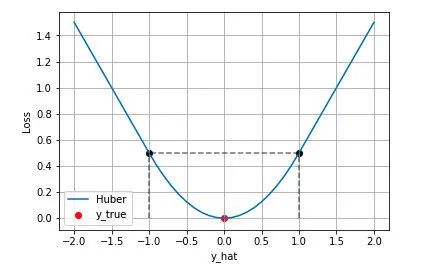
Huber Loss 的特点:
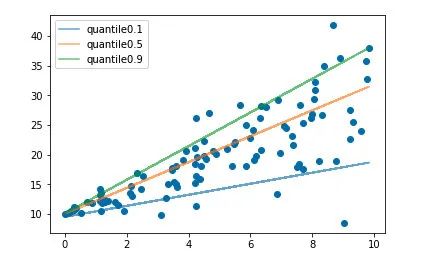
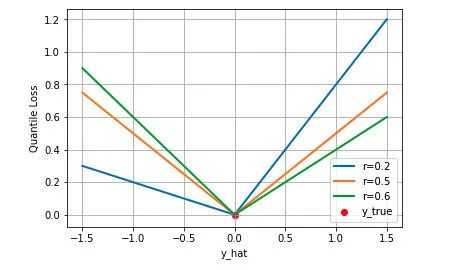
05 分位数损失 Quantile Loss


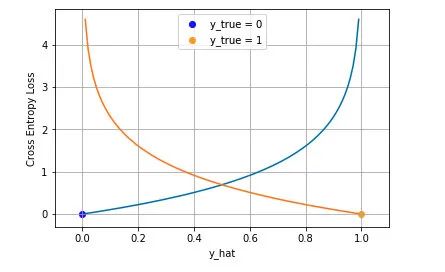
二分类:




多分类:



Cross Entropy is good. But WHY?





可以看到通过最小化交叉熵的角度推导出来的结果和使用最大化似然得到的结果是一致的。
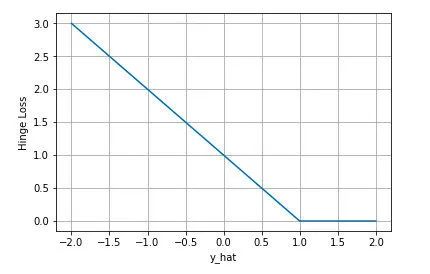
07 合页损失 Hinge Loss
合页损失 Hinge Loss 是另外一种二分类损失函数,适用于 maximum-margin 的分类,支持向量机 Support Vector Machine (SVM) 模型的损失函数本质上就是 Hinge Loss + L2 正则化。

Machine Learning: A Probabilistic Perspective
Picking Loss Functions - A comparison between MSE, Cross Entropy, and Hinge Loss
5 Regression Loss Functions All Machine Learners Should Know
Quantile Regression Demo
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~