
浅谈to B和to C数据开发的差异
共 3720字,需浏览 8分钟
·
2021-08-13 22:48
背景
通常来说,大数据开发的整体架构基本一样,都涉及到底层的数据平台架构、数据中间件的选择、数仓模型的建立、可视化展现,其中数据层面主要是数据的采集(埋点、业务数据)、数据处理(离线、实时)、数据治理(数据分层、数据字典、指标体系、数据监控、数据安全、数据数仓)、数据展现(BI、可视化)。
但是C端和B端对应的用户群、核心诉求都不太一样,会导致两块的数据目标、对数据的要求以及产品的思维方式都是不太相同的。
本人有幸针对电商C端做大数据开发2年,针对B端也做了2年,下面是我对这两个维度的数据产品以及开发思维的一些见解:
产品思维方式的不同
1、B端数据产品经理面对的是企业内部的业务协同与业务过程,产品目标是通过数据提升业务的决策效率,为业务过程提供定制化的数据产品服务。从而将消费者的需求精准而快速地传递给供应链,使得品牌与消费者的互动更加简洁和频繁。
2、C端产品需要用数据思维做产品设计,产品设计本身就是业务过程,产品的目标是通过数据能够快速的做用户圈选、用户画像、用户行为分析,为产品的迭代和优化方案提供可靠的数据支撑,方便快速进行产品迭代,能够很好的服务客户。
服务对象不同
1、B端服务的对象是企业。核心诉求是:功能,流程,效率。作为B端某个方向的负责人的话,是对整个方向产品线负责,要学会在实际的业务需求中发现问题,解决问题,考虑系统的延展性与弹性,从而提升整个业务工作效率;
2、C端服务的对象是个人,侧重满足个人生活需求,给用户提供愉悦感(满足便利、新鲜感、虚荣心、欲望冲动),好玩。核心诉求是:交互、体验、使用成本。
数据的需求不同
1、B端根据客户的战略或服务于线下已有的流程,构建生态体系,推动将流程系统化,提高效率。客户关心的是软件是否满足企业的需求,是否符合实际业务流程,是否提高企业运作效率,是否实现规范化管理,同时更关心投入产出比(ROI)。。
2、C端更多的关注是如转化率、功能留存、增长、页面停留时长等指标,只有关注这些指标才能更好的对产品进行优化和迭代。同时需要深挖消费者的心智模型,使用习惯,付费习惯,构建出能够满足消费者需求的有用户价值产品,进而在用户价值的基础上建立商业模式,产生商业价值。
to B相比to C在经营模式上需要一支链条更长的团队来运作。
to C,有产品经理、研发、再加一个推广运营就OK了,一支团队、三个角色可能就够了;但是to B不一样,得有市场营销,有了线索之后得有销售去转化,销售过程中可能还需要售前的配合,要给客户出方案,而客户不仅是一个人更是一个团队,还需要产品、研发、客服和技术支持等等,每个环节都是人在运作。链条一旦复杂之后,如果没有很好的战略能力、战略定力和组织能力,to B很难经营得很好。
to C的客户是一个个的人,我们自己也是一个个的人,我们可以问自己,问身边的人,观察周围的人;但to B我们面对的是一个个特定行业、特定场景里的组织,我们得真正理解这个行业。
项目
C端项目,之前主要做了2大块:
1、APP的各个页面、模块的健康度(针对APP的优化升级和版本迭代)
业务需求:
APP版本迭代,验证每个页面、页面上的每个模块是否满足用户需求,验证各个模块的调整是否符合用户习惯,验证新上线的活动是否达到预期目标,验证每个模块带来的商品加购和成交转化率是否达标。
技术方案:
设计埋点规范,前端对页面进行埋点,并对触发进行监控,保障数据回传的准确性;
数据采集,保障数据的准确性和完整性,确保不丢失数据(加入第三方数据校验);
数据校验,上线之前,对埋点数据进行校验,保障埋点数据的不丢失;
数据ETL,将采集的数据进行解析,并生成格式化数据存储到HDFS;
数据聚合,统计每个页面、每个模块的访问和点击情况、页面的停留时长、曝光商品数、带来的加购和成交等核心数据指标;
数据展现,将统计结果的数据存到可视化平台(QuickBI、Matebase等),进行可视化展现,并发现访问的趋势等;
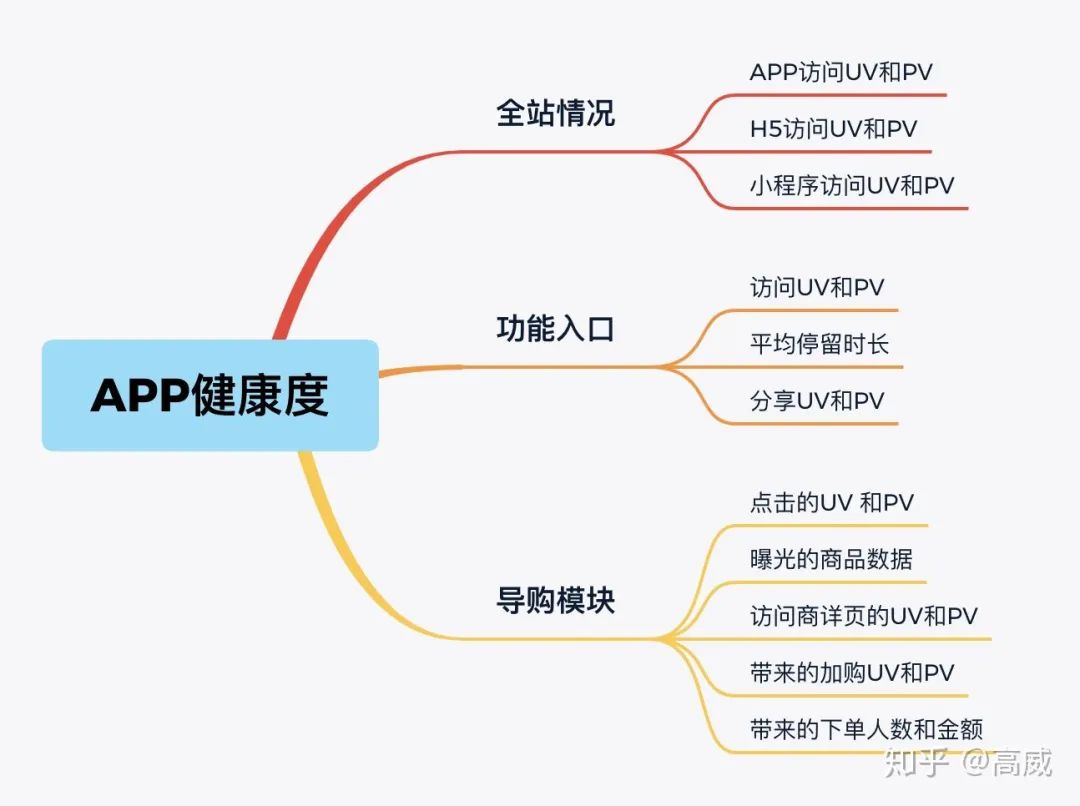
粗略的大概是以上指标,但是UV又区分到用户分层和活跃用户的情况,订单也涉及到首次加购和复购情况,商品详情页也分为普通商品、活动页等等。。
基于以上的数据指标可以分析出:
APP的日活是否正常;
一些功能入口设计没有带来访问和停留,是否可以优化或者替换;
导购模块链路是否合理,一些导购入口访问量很大,但是带来的商品详情页的访问和下单加购确不合理,是否是因为一些功能设计不够合理;
每个模块带来的订单转化对比,定期迭代相应的模块,提高转化率;
2、APP用户链路分析(针对用户活跃、留存、拉新、增长、分层等)
用户规模、用户活跃、用户留存、用户复购、用户分层等。
业务需求:
用户分群和精准推送、用户画像、搜索推荐等
技术方案:
埋点数据采集和ETL;
业务数据的监听和采集;
不同维度数据的聚合和ETL;
数仓模型搭建和数据聚合,完成业务数据支撑;
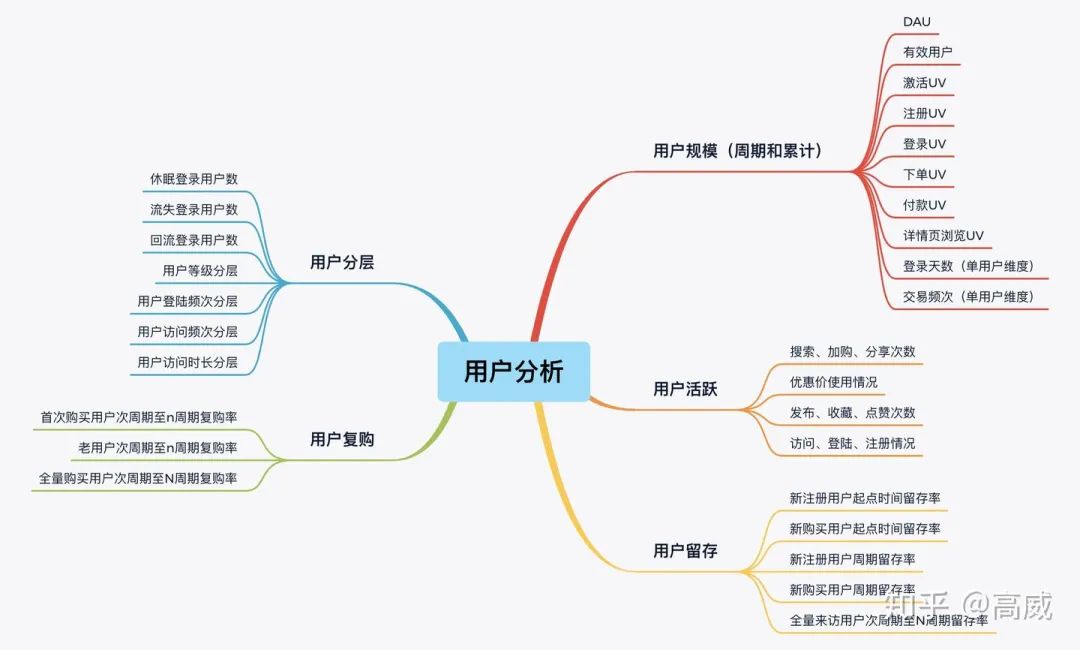
这块统计涉及到维度和统计范围都是比较广的,涉及到埋点日志、业务数据、推广和投放等各个渠道的数据。如何对这部分数据进行ETL和聚合是这块的主要技术难点。
B端项目,主要也做了2大块
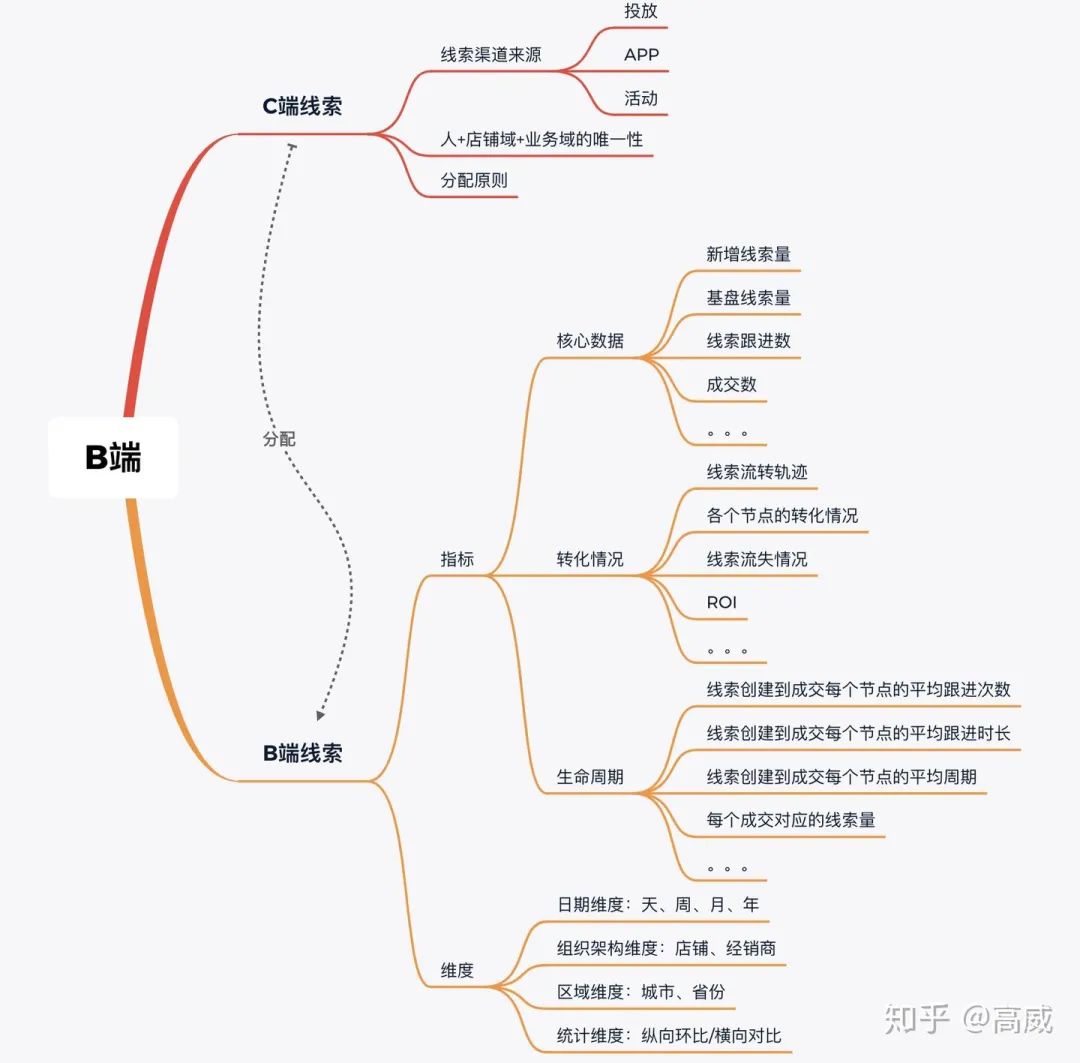
1、B端线索分配数据
业务需求:
整合B端售前数据,提供工作台展现各个门店的核心指标数据以及ROI;
整合线索流转的轨迹,和各个阶段的转化率和流失率;
挖掘影响最后成交的核心点,对该点进行优化;
按照区域、大区去发现门店适合做什么活动方便门店快速的成交。
技术方案:
业务流程的数据治理和整合,打通了线索分配到车商后的整个流转过程;
建立线索分配后各个节点的DW层数据,方便后续聚合;
将各个流程模块化,相互之间强关联,但是弱耦合。强关联是为了分析整个业务流程的趋势,以及各个流程之间的相关关联和转化程度,弱耦合是为了保障各个模块独立性,每个模块的数据单独展现,可以随时在模块中新增、删除或者替换指标,并不影响整个工作台看板数据的展现。
建立数仓模型,以线索创建为事实表,并对后续跟进、约见、成交、活动等事实表进行维度上卷,聚合成线索+门店为唯一性主键的大宽表;
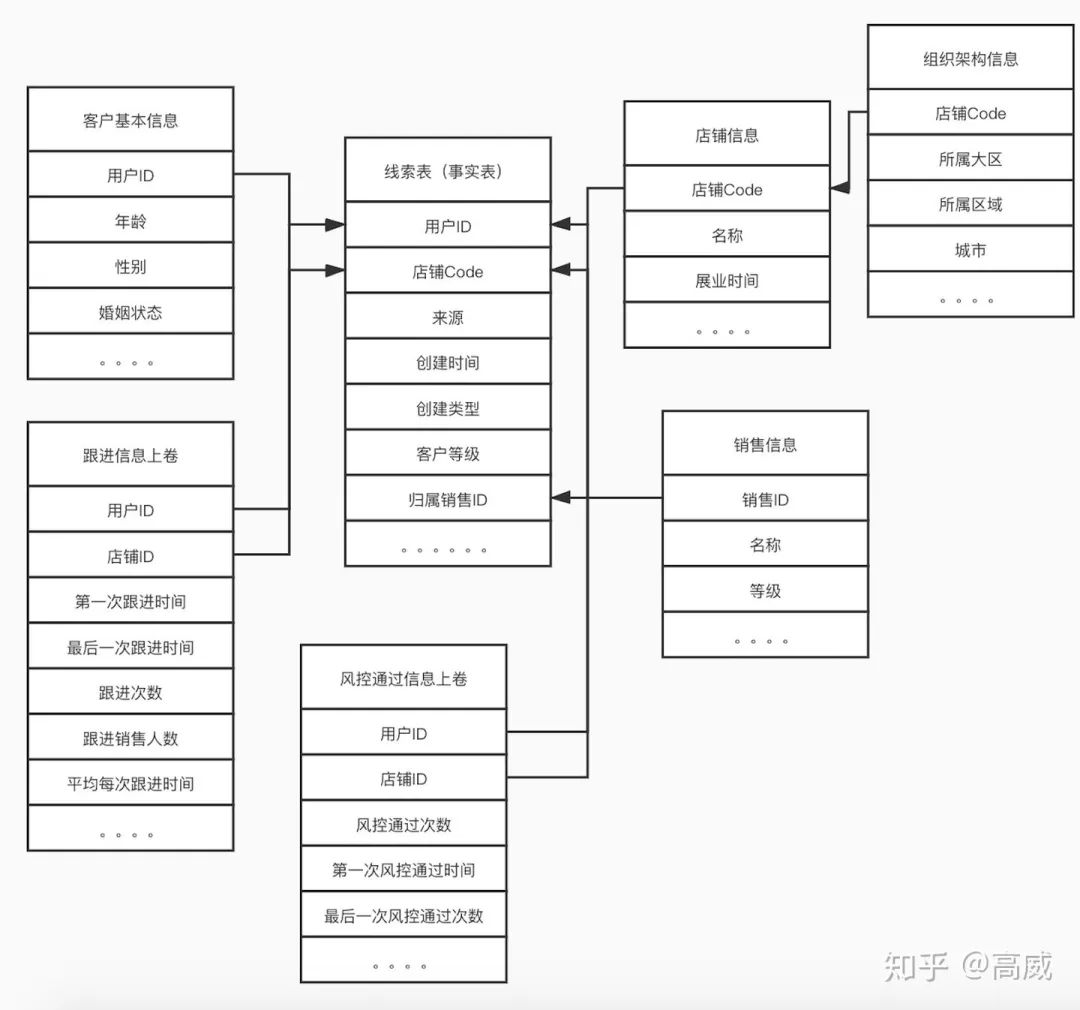
基础数据流程:
数仓模型-雪花模型(线索域)
2、B端店铺分层/门店健康分分层(在to C的时候也做过对入驻APP的店铺进行分层)
业务目标:
按照一定的维度进行店铺分层,区分头部、腰部、尾部的店铺,通过对头部店铺的行为进行分析,将一些好的行为和活动赋能给其他的门店,希望能够提升所有门店的结果。
前提:验证店铺好不好的唯一标准就是成单量(ORI)
技术方案:
确定和店铺健康程度相关的一些指标;
列出对应的加分项和减分项;
将指标进行关联性性分析,对于同一节点中强相关的指标可以选择一个重要指标作为唯一指标。
筛选出固定指标后,例如历史数据的情况来添加权重,建立分层模型。
预测未来几个月不同层级店铺成单情况,如果符合模型预测,则这个模型没啥问题,不符合重新调整参数。
分析头部门店的销售能力、业务操作,将其规范化赋能给其他店铺。
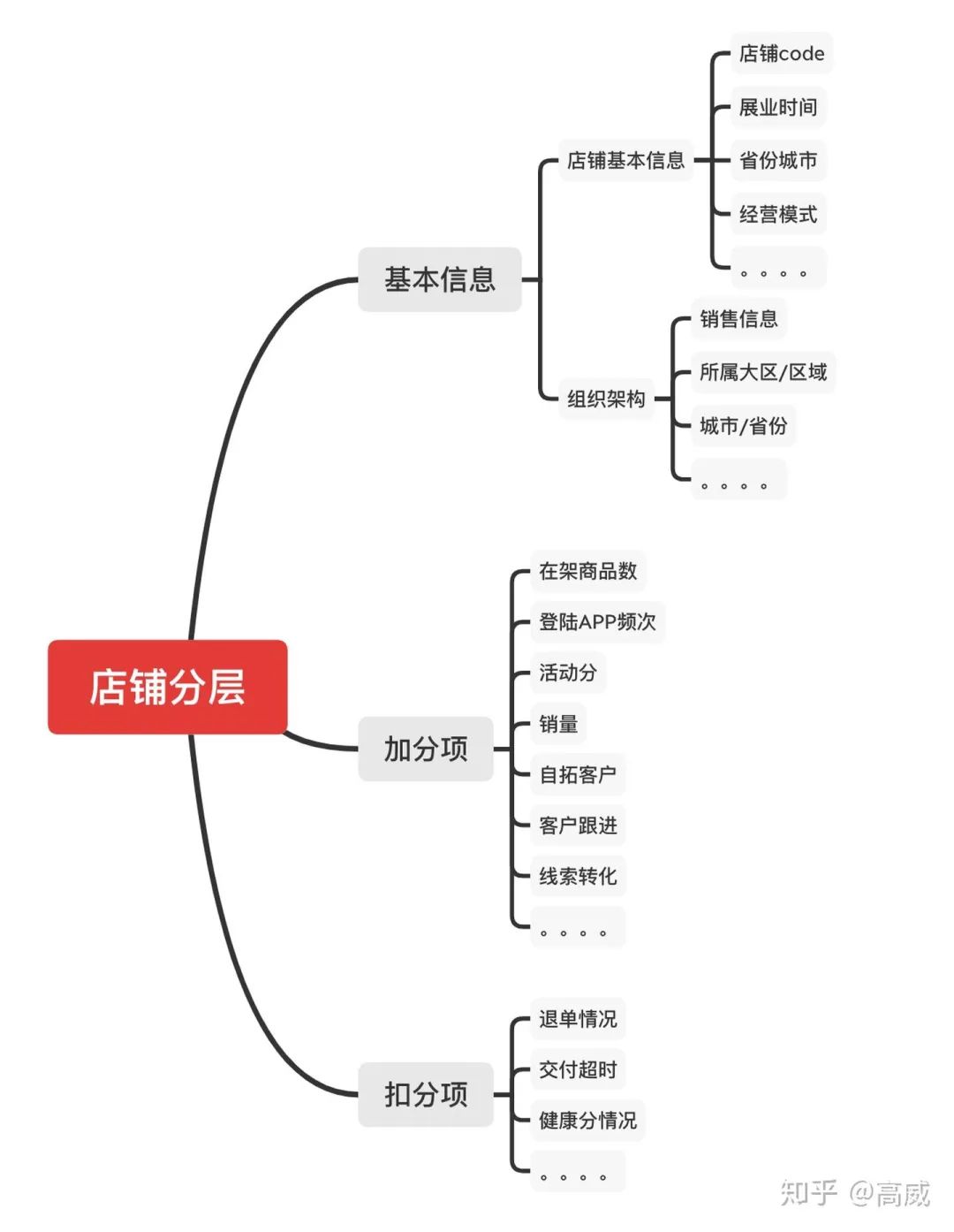
通过过去6个月的数据来确定各个指标对应的数值或者权重。
例如:
销量为例:销量得分总分为100分。
对店铺按照销量进行排序,如果该店铺销量在全部店铺排名为前1%,那么得分为100。
当然还可以按照优先级进行权重评判。
结论
当然上面的情况只是在两家公司的总结,并不能作为一个普适的标准,就算to C的电商公司卖的商品也会有很大的区别,例如买小型商品和奢侈品的平台在商业模式是是有很大的区别的。在电商公司看来很重要的加购行为,在拼多多是不能适用的。
但是to B和to C还有有点本质差别的:
to C讲究的是创新和匠心,特别看中玩法,不论像之前的搭伙、拼团,还是后面的红包、优惠券,都是不同的玩法,如何抓住新用户(创新)、维护一批忠实客户(匠心)是C端产品主要研究的点。
to B讲究的是赋能,或者像网易所说的“合能”,主要是聚集在效率上,希望跟你合一起,帮助你成长,相对来说在模式上需要一个更长的链路去支撑,尤其是市场营销,而且这一块大部分偏线下,不太好把控。
相对来说,to B更加的困难。
to B卖出去产品仅仅是一系列工作的开始。要实现产品价值,还有漫长的过程。
B 端获客周期长,获客成本高。
难获真实需求,主观臆想易犯低级错误,to C你本身可能就是核心用户,所以在定义用户需求中,不会犯特别低级的错误。
要用标准化产品满足碎片化需求,企业服务的竞争力核心,就是如何尽量用标品、尽量用产品化的方式,来解决用户不同的问题。
提高效率是to B的最主要的赋能方式。
营销环节是to B独有而且重要的环节,To B 业务的价值链长很多,首先做好产品本身就不容易,因为客户个性化需求多。其次光做好产品还不行,还需要销售、服务、客户成功等多部门的协同配合,这就对组织能力提出了更高的要求。
当然上面都是一个数据开发人员的视角,可能只是一个片面的结论。
开发人员能做的就是切合到具体的业务场景,根据它具体的业务模式和数据情况来分析出能够赋能业务的数据指标。