
应用深度学习进行乳腺癌检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:AI算法与图像处理

01.概述
癌症是人类主要的死亡原因之一,仅次于心脏病[A]。美国2017年近60万人死于癌症。乳腺癌在癌症排行榜中排名第二,也是女性最常见的疾病。组织学检查通常是患者癌症治疗过程中的转折点。如果常规的乳房X射线检测到异常肿块,则将进行活检以便进一步确诊。但是,复查和评估活检玻片所需的时间很长,可能会给患者带来巨大的压力。一种能够识别癌组织并减少误诊率的有效算法可使患者更早开始治疗并改善患者预后效果。
卷积神经网络(CNN)已经尝试应用于癌症检查,但是基于CNN模型的共同缺点是不稳定性以及对训练数据的依赖。部署模型时,假设训练数据和测试数据是从同一分布中提取的。这可能是医学成像中的一个问题,在这些医学成像中,诸如相机设置或化学药品染色的年龄之类的元素在设施和医院之间会有所不同,并且会影响图像的颜色。这些变化对人眼来说可能并不明显,但是它们可能会影响CNN的重要特征并导致模型性能下降。因此,重要的是要开发一种能够适应域之间差异的鲁棒算法。
过去已经举行了数项竞赛,以开发组织学幻灯片中的癌症检测算法,例如ICIAR系列(BACH)[C],乳腺癌组织病理学数据库(BreakHist)[D]和Kaggle组织病理学癌症检测[E] 。在此项目中,我们将探索如何使用域适应来开发更强大的乳腺癌分类模型,以便将模型部署到多个医疗机构中。
02.背景
“癌症是人体内不受控制异常生长的细胞。当人体的控制机制不工作的时候,癌症就会发展。” [G] 在美国,预计八分之一的女性都会患乳腺癌。到2020年,预计将识别出300,000例乳腺癌病例,结果38人中将有1人死亡。
组织学用于评估患者的身体组织并鉴定癌细胞。在评估之前,将组织样本染色以突出显示组织的不同部分。苏木精和曙红是常见的染色剂,因为它们可以有效地突出异常细胞团。苏木素是一个碱基,与嗜碱性结构(如细胞核)结合,将它们染成紫色,而曙红将嗜酸性结构(如细胞质)染成粉红色[H]。理想中,不同的颜色和结构足以识别组织异常。但是,染色组织的确切阴影可能会根据变量(例如年龄,染色化学物质的浓度,湿度和样本大小)而变化(图1)。这些颜色变化可能会使CNN模型分辨不清。
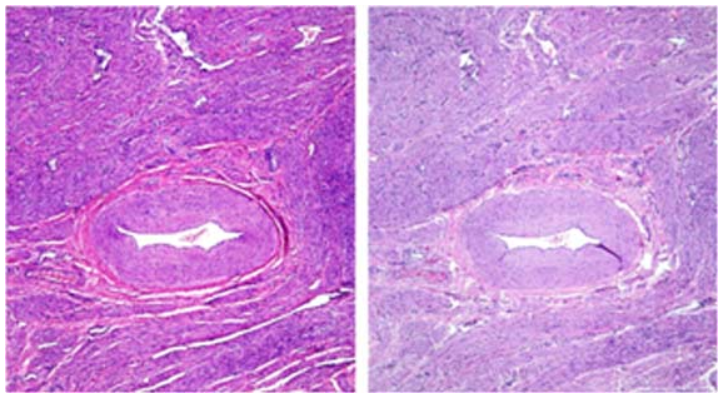
图1.薄和厚组织切片中的颜色差异[I]。
03.数据
我们使用了来自ICIAR BACH 2018案例竞赛[C]和BreakHist数据库[D]的数据。每张图片都经过几位医学专家的审查标记。示例图像可以在图2中看到。
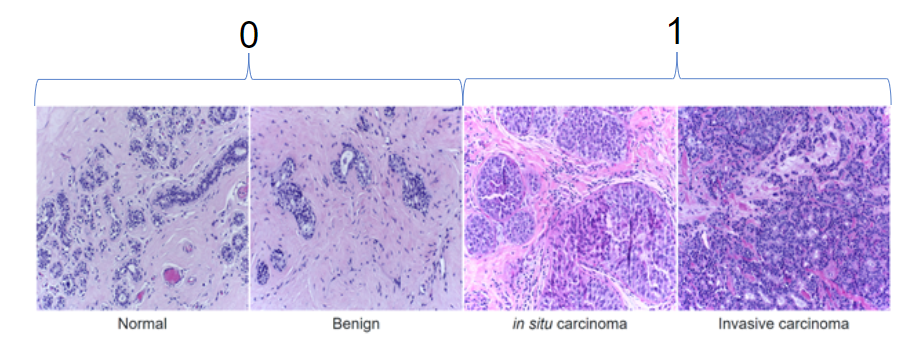
图2. BreakHist数据库的示例图像。
BACH数据集提供了400张图像,分为四类:正常,良性,原位和有创。良性肿瘤是异常的细胞团,对患者构成最小的风险。通常在被识别时,它就被单独放置[J]。一个原位肿瘤是未跨过身体系统扩散细胞的激进组。通常,它被认为是恶性前癌症,随着时间的流逝将变得恶性[J]。浸润性癌症是最严重的癌症类型,因为它已转移至超出其在体内原始位置的位置。对于此分析,我们将正常和良性标签视为健康组织,并将原位和浸润性视为癌性组织。
BreakHist数据集提供了在多个缩放级别(40x,100x,200x和400x)下拍摄的约8000张良性和恶性肿瘤图像。这些组中包括的不同类型的肿瘤在下面列出。
• 良性肿瘤:腺瘤,纤维腺瘤,叶状肿瘤和肾小管腺瘤
• 恶性肿瘤:癌,小叶癌,粘液癌和乳头状癌(K)
04.预处理
为了开发用于领域适应的强大模型,我们选择将BreakHist数据用于我们的训练集。多个缩放级别是模型鲁棒性的一个很好的起点,因为幻灯片图像的大小/放大倍数在整个行业中通常没有标准化。
为了减少计算时间,将所有图像缩放到224x224像素。对于CNN模型,权重和节点的数量随着输入图像大小的增加而呈指数增长。不幸的是,当整个幻灯片图像从其原始尺寸减小时,很多信息可能会丢失。因此,需要在模型复杂度和准确性之间进行权衡。
图1和图2展示了污渍中存在的各种颜色。为了使我们的模型可跨域使用,我们为训练集中的每个原始图像实施了九种颜色增强。这些增色改变了图像的颜色和强度。此外,我们对每个变换后的图像进行了3次旋转,以说明相机定位和组织样本方向的差异。这些预处理步骤将我们的训练集的大小从7,909张图像增加到285,000张图像。
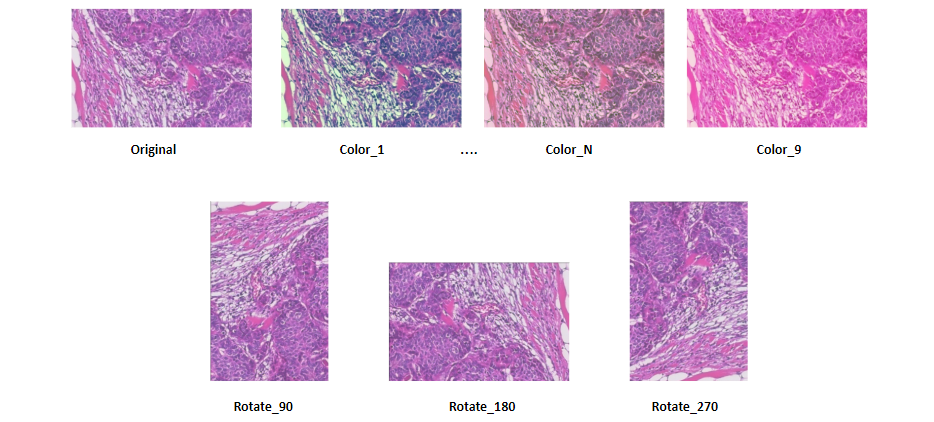
图3.训练集中单个图像的图像增强摘要。
05.建模与训练
基准模型
为了了解自适应的优势,我们首先在原始BreakHist数据集上训练了CNN模型,并在ICIAR数据集上对该模型进行了测试。此初始模型使我们能够了解模型应用于其他领域时的准确性,而无需进行设计考虑。
如前所述,BreakHist数据集包含大约8,000张图像。每个图像都从其原始尺寸缩小到224x224正方形图像。因此,CNN的输入是所有224x224像素的RGB值。ResNet34模型架构经过十个阶段的培训;并记录了从原始BreakHist数据集中提取的验证集上模型的准确性。为了确定模型的准确性是否可以延续到另一个领域,在ICIAR数据集中的400张图像上对模型进行了测试。
方法1
为了提高我们在第二个领域中检测癌症的能力,我们使用了颜色归一化技术和旋转功能来增强BreakHist数据。处理完所有这些数据后,我们获得了约285,000张图像。有了这么多图像,运行一个历时就花费了七个多小时。为了找到一种在计算上更可行的解决方案,我们将训练数据降采样为25,000张图像的平衡集。
新的CNN接受了25,000张增强图像的培训。所有其他模型参数,例如ResNet34架构和时期数,都保持与以前相同。确定了该模型在验证集上的准确性。然后,在ICIAR数据集上测试了该模型,以确定增强后的图像是否提高了我们在不同领域中检测癌症的能力。
方法2
为了提高模型准确性并进一步探索领域适应性,以与BreakHist训练集相同的方式对ICIAR测试集进行了预处理。对测试集中的每个图像进行色彩增强,以产生原始图像的九种变体。这9个变体通过了CNN模型,并对其输出进行了多数表决,以确定原始图像的预测标签。然后通过将多数投票标签与真实标签进行比较来确定模型的准确性。
06.结果
基准模型
测试的第一个模型是我们的基准模型,它使我们能够量化域自适应的优势。在包含来自与训练集相同来源的数据的验证集上对该模型进行测试时,该模型达到了89.31%的准确性。这表明该模型在用于培训的同一领域中使用时成功诊断了癌症。但是,随后对该模型进行了不同领域的数据测试,仅产生了45%的准确性。该准确性比随机猜测差,并且表明必须考虑设计因素才能生成可在多种医疗保健环境中使用的模型。这些不良结果的可能解释包括扫描仪和染色技术的差异。此测试的混淆矩阵如图4所示。该模型似乎没有高估任何癌症。
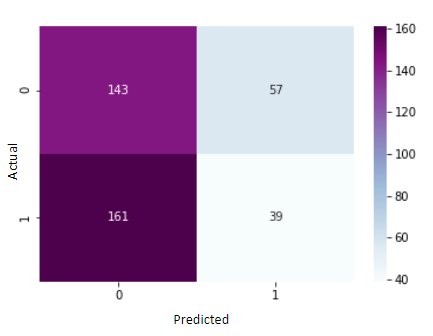
图4:未增强/预处理的结果
方法1
先前的研究和期刊出版物已经表明,域适应可以提高乳腺癌分类器的准确性。为了验证该想法,我们在增强图像上训练了一个新模型,以使该模型对颜色和方向的变化更加鲁棒。对来自不同域的数据进行模型测试时,准确性为55.25%。尽管此域中的性能仍然明显小于原始域中的性能,但它确实证明了域自适应可以对基线模型进行一些改进。此外,我们可以观察到模型预测的巨大变化。基线模型倾向于高估没有癌症。但是,这种新模型存在相反的问题,并且高估了癌症。该模型的混淆矩阵如图5所示。

图5.方法1的测试结果
方法2
为了使训练域和测试域更加相似,对测试图像进行了预处理,并对训练集使用了相同的增强方法。然后,将增强的测试图像通过方法1的CNN模型传递。不幸的是,在这种方法下,模型精度降低到53.75%。该模型的混淆矩阵如图6所示。

图6.方法2的测试结果
07.未来工作
该项目的目的是了解医疗领域中算法的域适应带来的挑战。先前的研究表明,深度学习模型可以有效地缓解医师缓慢而单调的工作,但在实际应用中必须经过充分的培训和测试。从我们的模型可以看出,验证准确度(最少的预处理/扩充)为89%,但在不同的领域中使用时,很快下降到了45%。这凸显了域适应的挑战。一旦我们考虑到了领域变化而进行了设计考虑,我们模型的测试准确性就提高到了55.25%。这表明,通过更多的数据,准备工作和培训,我们可以提高模型的准确性。
但是,在将该模型用于诊断癌症之前,有必要进行进一步的改进。由于项目的限制,我们将训练集从285,000张图像减少到25,000张图像。此外,每个图像的大小均缩小到224x224像素。这些修改可能会限制我们模型的性能,尤其是在此域中,因为色阶看起来与人眼非常相似,并且缩小尺寸可能导致过多的信息丢失,尤其是在数据集之间。未来的工作应该探索使用更多的可用数据,并且在寻找精细细节时,关于颜色排列和大量相同颜色如何影响模型和各种类型的CNN滤镜,可以做更多的研究。此分析的另一个局限性是我们无法解释模型错误的可能原因,因为组织学切片的解释需要一定程度的主题专业知识。对于更大范围的解释,让病理学家识别潜在趋势并提供见解会有所帮助。
也可以使用其他方法来潜在地提高模型的准确性。例如,可以对来自多个域的数据进行训练。我们希望该模型能够展示出更高的性能,因为这将减轻对特定来源特有模式的过度拟合。对于乳腺癌,这必须由医院提供,并且由于HIPAA代码的缘故,通常无法免费获得。
该项目证明了CNN模型可能非常脆弱,领域适应性至关重要,并强调了鲁棒性的需求,尤其是在医疗领域,决策可能会对患者的生活产生重大影响。我们希望将来可以改进此模型,以提高乳腺癌诊断的准确性并为癌症患者提供更好的结果。
资源:
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~