
Apache拯救世界之数据质量监控工具 - Apache Griffin

Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。

概述
batch数据:通过数据连接器从Hadoop平台收集数据
streaming数据:可以连接到诸如Kafka之类的消息系统来做近似实时数据分析
特性
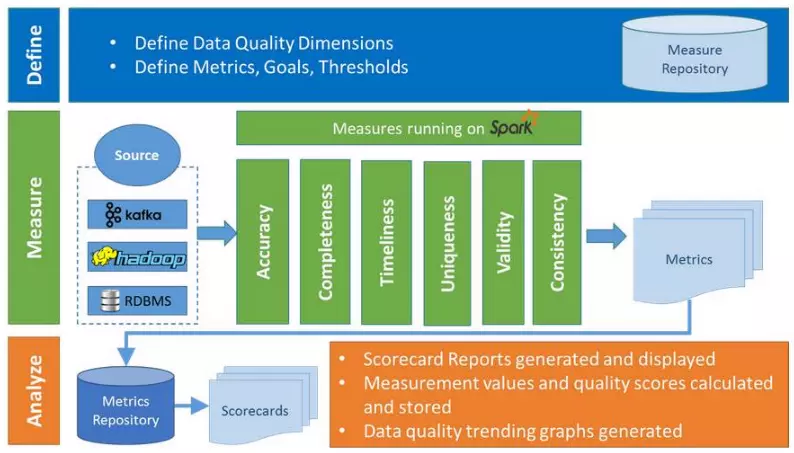
度量:精确度、完整性、及时性、唯一性、有效性、一致性。
异常监测:利用预先设定的规则,检测出不符合预期的数据,提供不符合规则数据的下载。
异常告警:通过邮件或门户报告数据质量问题。
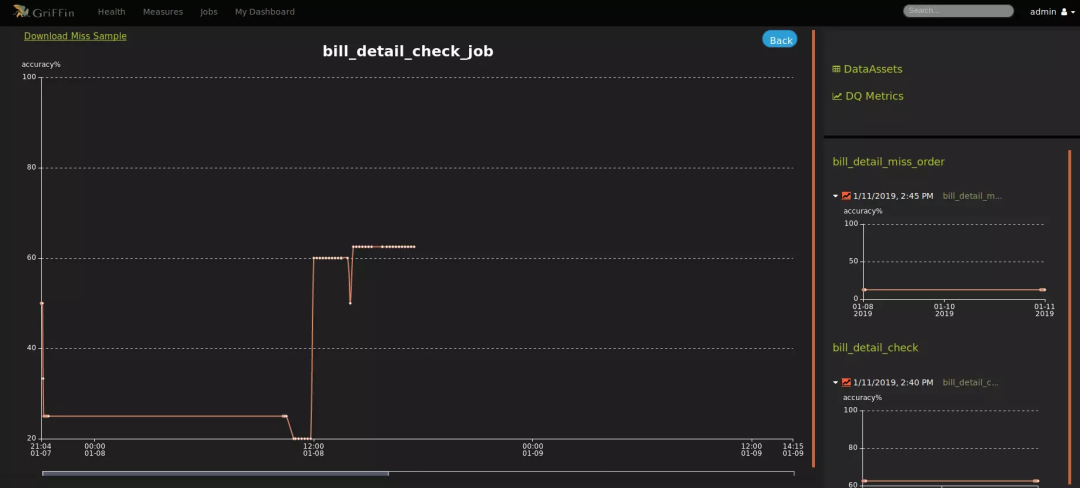
可视化监测:利用控制面板来展现数据质量的状态。
实时性:可以实时进行数据质量检测,能够及时发现问题。
可扩展性:可用于多个数据系统仓库的数据校验。
可伸缩性:工作在大数据量的环境中,目前运行的数据量约1.2PB(eBay环境)。
自助服务:Griffin提供了一个简洁易用的用户界面,可以管理数据资产和数据质量规则;同时用户可以通过控制面板查看数据质量结果和自定义显示内容。
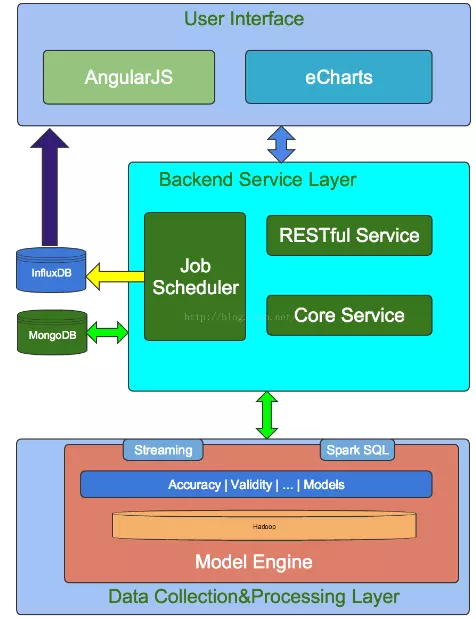
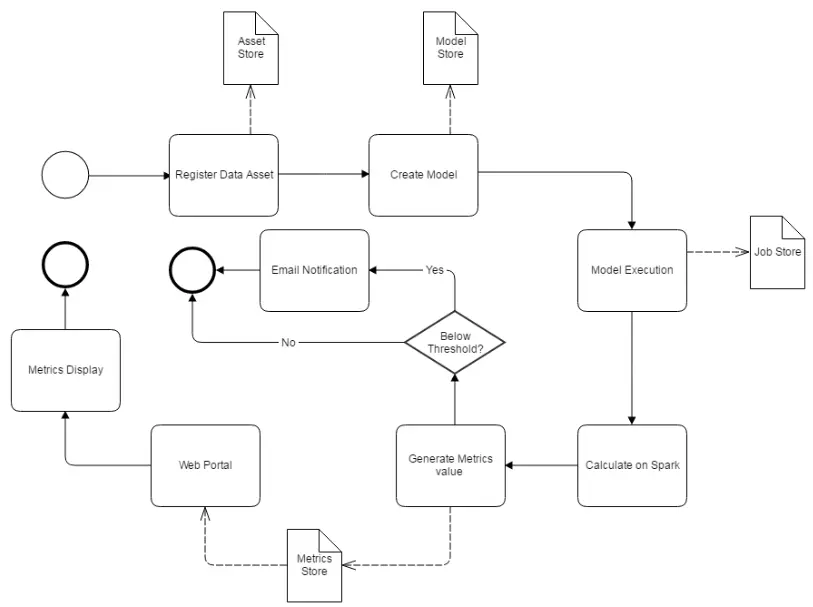
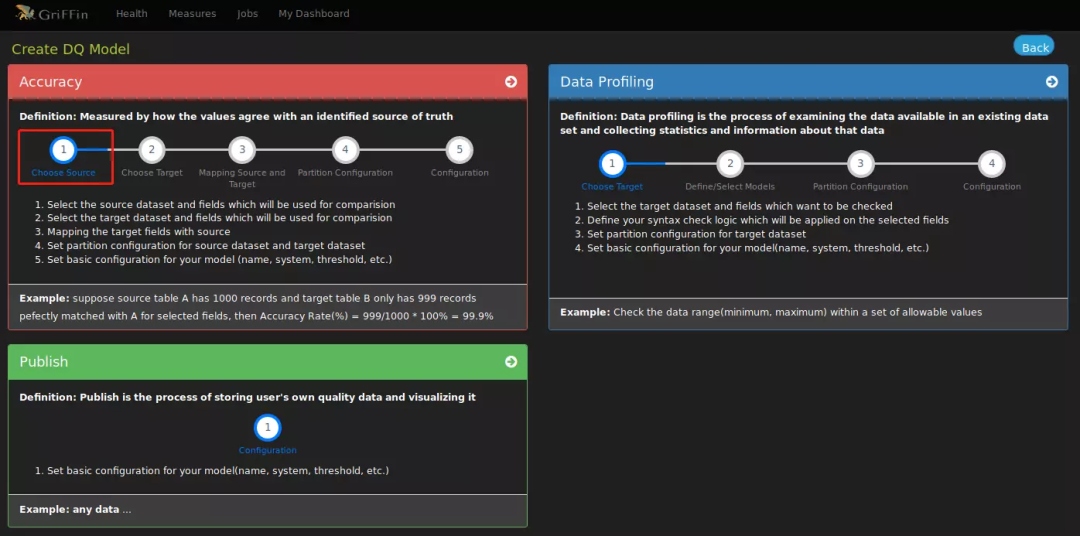
Griffin的系统架构
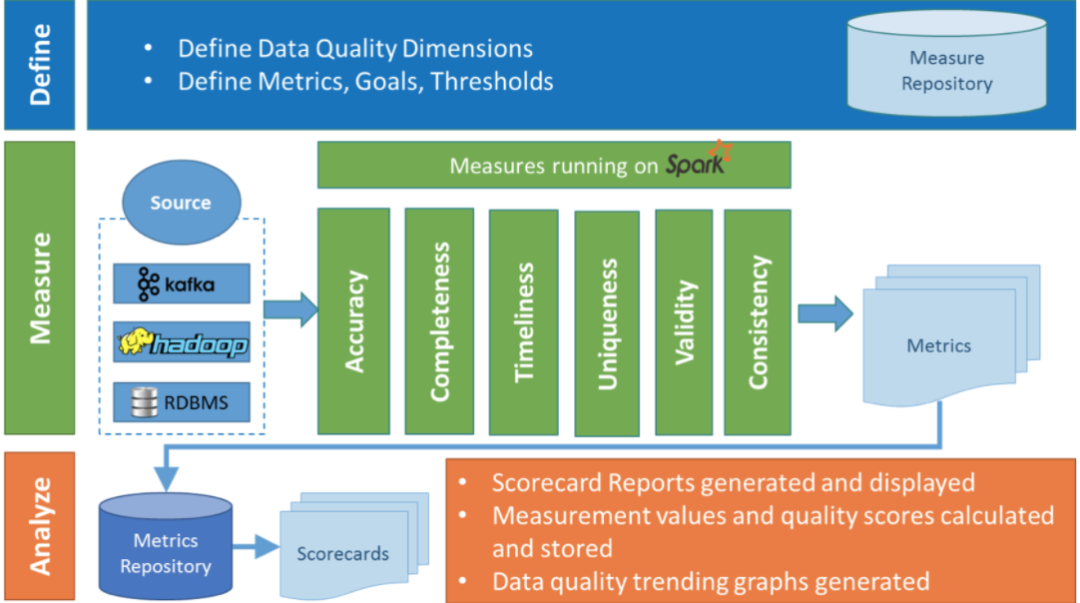
Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)
Measure:主要负责执行统计任务,生成统计结果
Analyze:主要负责保存与展示统计结果
安装部署
JDK (1.8 or later versions)
MySQL(version 5.6及以上)
Hadoop (2.6.0 or later)
Hive (version 2.x)
Spark (version 2.2.1)
Livy(livy-0.5.0-incubating)
ElasticSearch (5.0 or later versions)
Hello Griffin!
--create hive tables here. hql script
--Note: replace hdfs location with your own path
CREATE EXTERNAL TABLE `demo_src`(
`id` bigint,
`age` int,
`desc` string)
PARTITIONED BY (
`dt` string,
`hour` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
LOCATION
'hdfs:///griffin/data/batch/demo_src';
--Note: replace hdfs location with your own path
CREATE EXTERNAL TABLE `demo_tgt`(
`id` bigint,
`age` int,
`desc` string)
PARTITIONED BY (
`dt` string,
`hour` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
LOCATION
'hdfs:///griffin/data/batch/demo_tgt';
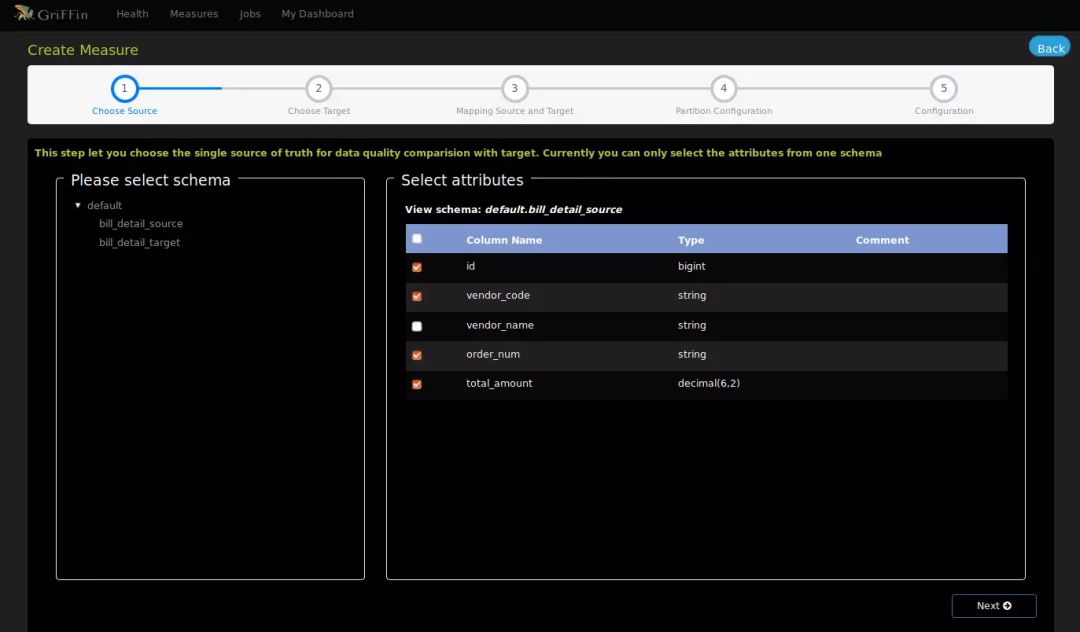
选择数据源
选择账单明细源表字段
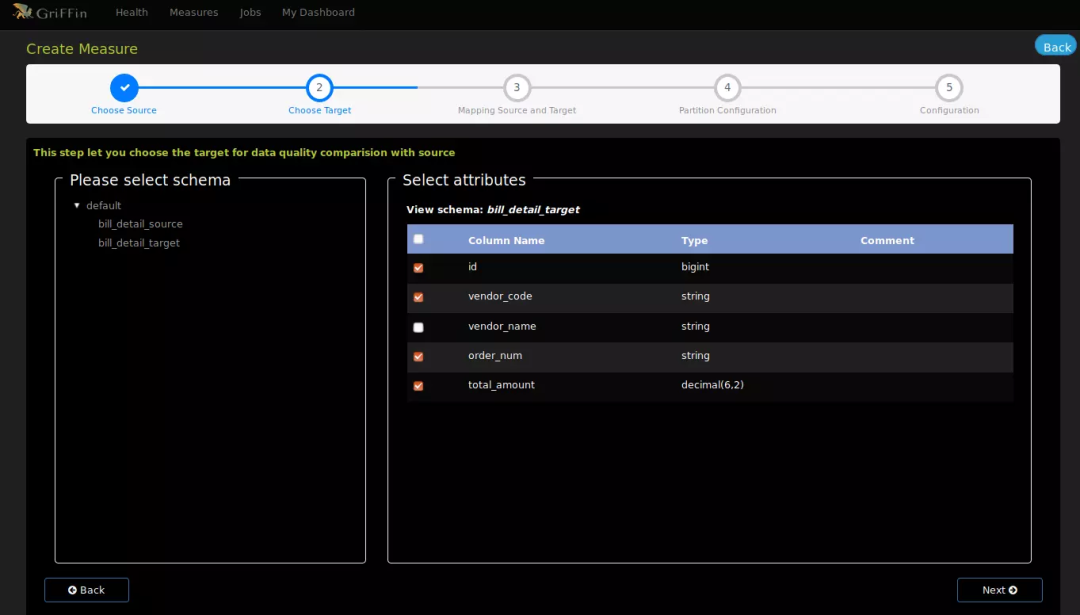
选择账单明细目标表字段
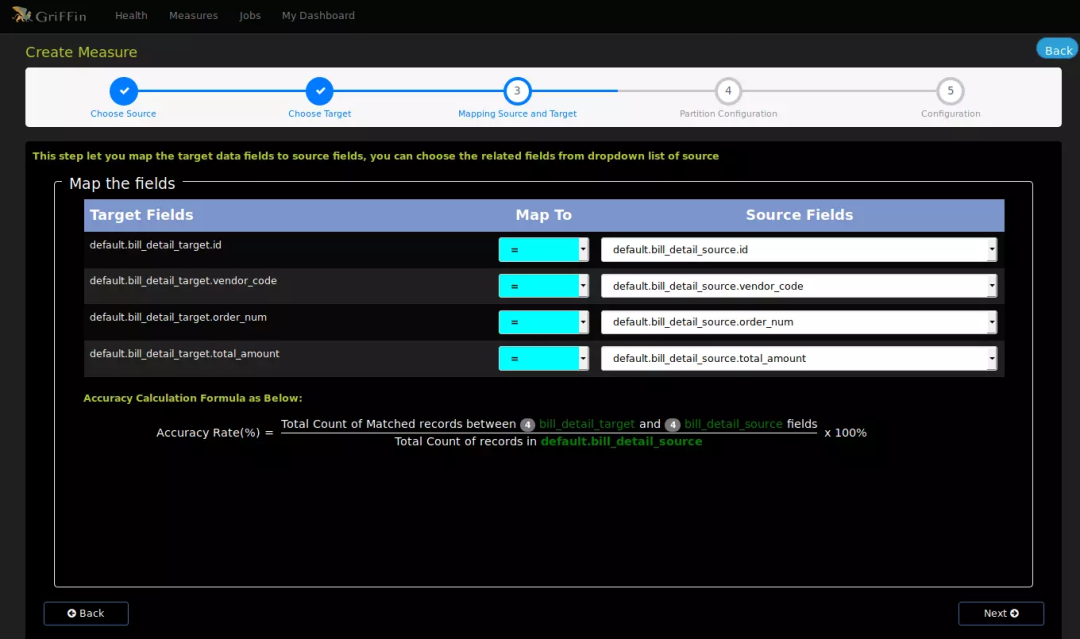
设置源表和目标表的校验字段映射关系
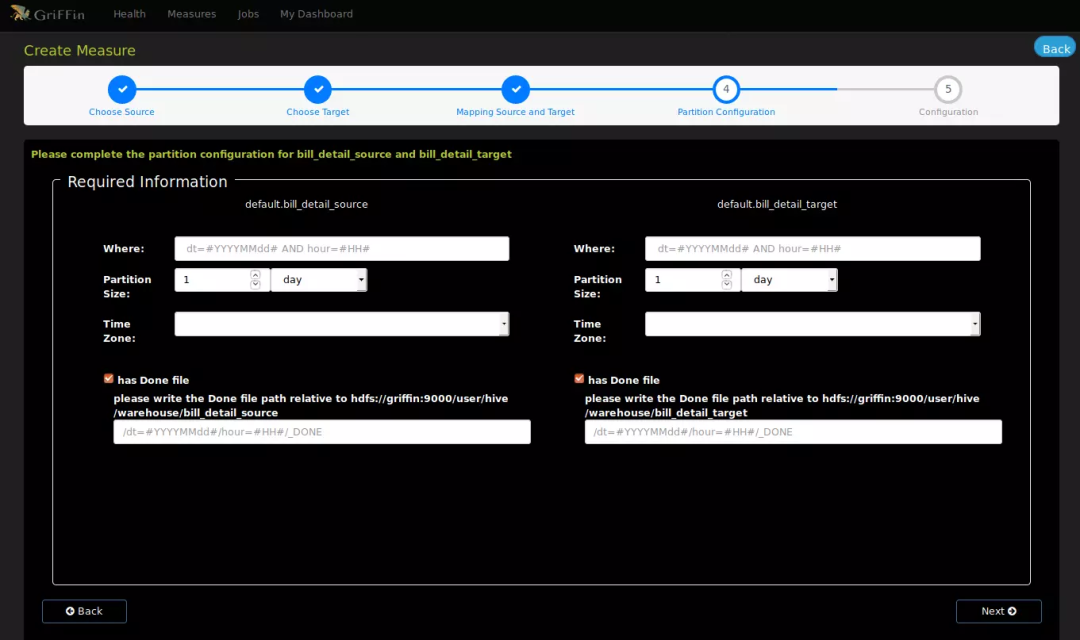
选择数据分区、条件和是否输出结果文件。(无分区表可以跳过)
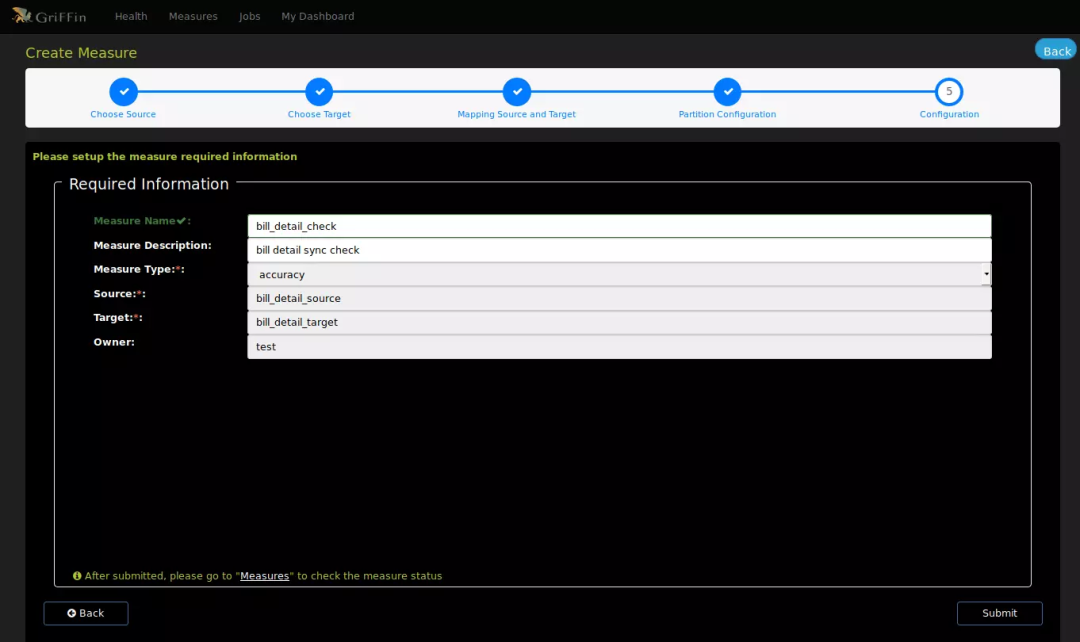
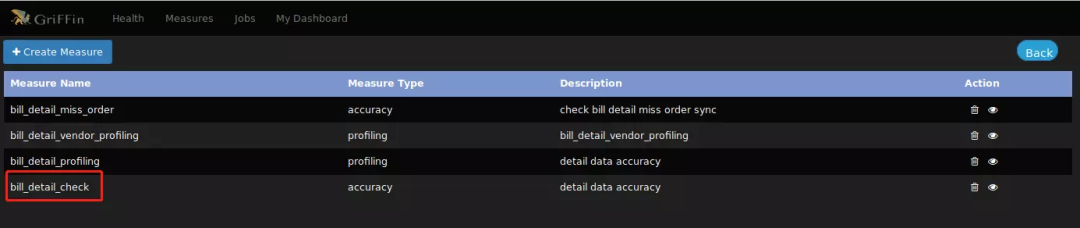
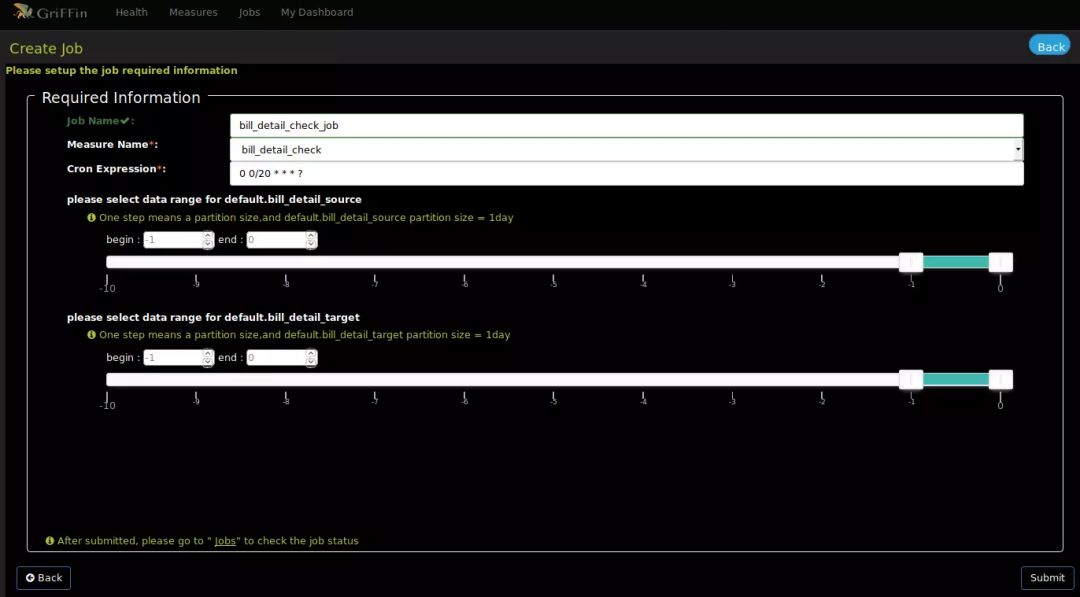
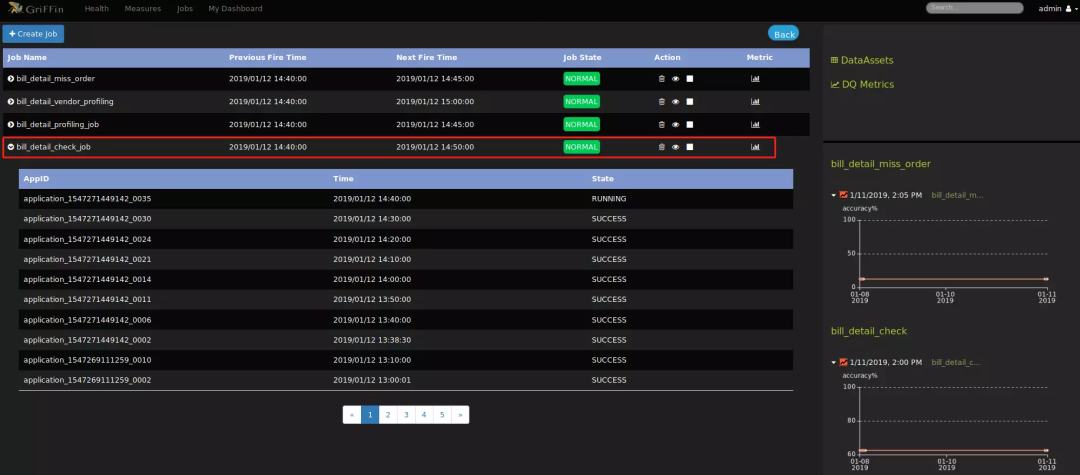
设置验证项目名称和描述,提交后就可以在列表看到度量的信息了
在job菜单下,选择Create Job
总结
Spark
Hadoop
Hive
Livy
Quartz
目前Apache Giffin目前的数据源是支持HIVE,TXT,文件,avro文件和实时数据源 Kafka,Mysql和其他关系型数据库的扩展需要自己进行扩展
Apache Griffin进行Mesausre生成之后,会形成Spark大数据执行规则模板,shu的最终提交是交给了Spark执行,需要懂Spark进行扩展
Apache Griffin中的源码中,只有针对于接口层的数据使用的是Spring Boot,measure关于Spark定时任务的代码为scala 语言,扩展的时候需要在measure中进行扩展,需要了解一下对应的scala脚本。
大家还可以参考:
https://blog.csdn.net/vipshop_fin_dev/article/details/86362706
https://blog.csdn.net/zcswl7961/article/details/101479637
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!
