
Meta发布大规模视觉模型评估基准FACET!开源视觉模型DINOv2允许商用

作者 | 谢年年
近日,Meta宣布开源计算机视觉模型DINOv2现在可商业化应用了,并发布了全新的视觉模型评估新基准FACET。
DINOv2是Meta AI继「分割一切」SAM模型之后发布的一重磅视觉基础模型,在今年4月份宣布开源,但之前只能用于技术研究,这次Meta宣布其可在 Apache 2.0 许可证下进行商业化。意味着开发者、研究人员可以灵活地探索其在业务中的应用,给实际业务提供解决方案。
DINOv2是高性能计算机视觉基础模型,能产生高性能的视觉表征,具备自我监督学习,无需微调就能用于分类、分割、图像检索、深度估计等下游任务。 该模型的应用范围非常广泛,例如,世界资源研究所通过DINOv2绘制虚拟森林地图。
相较于其他模型,DINOv2在执行视觉任务时能够更准确地处理人物的年龄、性别、肤色等特征,提供更一致的结果。
体验demo:
https://dinov2.metademolab.com/
论文地址:
https://arxiv.org/abs/2304.07193
GitHub地址:
https://github.com/facebookresearch/dinov2
让我们通过一些例子来看看DINOv2的表现吧!
深度估计(Depth Estimation)
一般很少有预训练模型展示自己在深度估计方面的能力,DINOv2 模型表现出强大的分布外泛化能力(strong out-of-distribution performance)。
语义分割(Semantic Segmentation)
DINOv2 的冻结特征(frozen features)可以很容易地用于语义分割任务。
实例检索(Instance Retrieval)
给定目标图像,从大量的艺术图像中找到与给定图像相似的艺术作品。
原图:
检索结果:

稠密匹配(Dense Matching)
在检索到与目标图像相似的多个图像后,可从中选择一张图片进行像素点到像素点更细粒度的匹配。在两张图像中找到最相似的对应点。

稀疏匹配(Sparse Matching)
稀疏匹配相对于稠密匹配,其匹配的单位更大一些。
视觉模型评估基准——FACET
虽然DINOv2等计算机视觉模型在分类、检测、分割等任务中展现出令人印象深刻的能力。然而,由于训练数据的限制,这些模型可能会学习到社会偏见,并在下游任务中传递这些有害的刻板印象。
以往的研究表明,计算机视觉公平性评估非常具有挑战性,并且可能存在误差。为了应对这个问题,Meta发布了一项全新的综合基准测试工具——FACET。
FACET提供了一种新的方法来评估计算机视觉模型的公平性。它不仅考虑了人口统计和物理属性,还考虑了与人类相关的类别,例如评估图片人物的性别、肤色、光线等,从而能够进行更深入的评估,揭示模型中存在的偏见。
通过引入FACET,我们能够更全面地评估计算机视觉模型的公平性,打破刻板印象,推动公正和包容的计算机视觉技术发展。
FACET论文链接:
https://ai.meta.com/research/publications/facet-fairness-in-computer-vision-evaluation-benchmark/
FACET数据集下载地址:
https://ai.meta.com/datasets/facet-downloads/
FACET数据集
该数据集包含32,000张图像,涵盖了50,000个人的信息。这些图像由专家进行标注,包括人口统计属性(如性别、年龄)、额外的身体属性(如肤色、发型)以及与职业和活动相关的细粒度类别,如医生、唱片骑师或吉他手等。FACET还包含了SA-1B数据集中69,000个戴口罩的人的头发和服装标签。

通过使用FACET初步评估发现,目前最先进的模型在展示不同人口群体之间的性能差异方面存在一些倾向。例如,对于肤色较深的人,识别他们的照片可能更具挑战性,而对于卷发而非直发的人来说,这种挑战可能会更加显著。
通过发布FACET,研究人员和从业人员执行此基准测试以更好地了解其模型存在的差异,并帮助他们更好地理解和处理模型中的偏见和不公平现象。这为研究人员提供了一个有力的工具,使他们能够更深入地探索和解决计算机视觉模型中的公平性问题。
在FACET上评估DINOv2
为了验证DINOv2模型的公平性,研究人员运用FACET评估了DINOv2在不同属性上的性能差异,并将其与SEERv2模型和OpenCLIP视觉编码器进行了比较,这些属性包括分类、年龄组和肤色等。
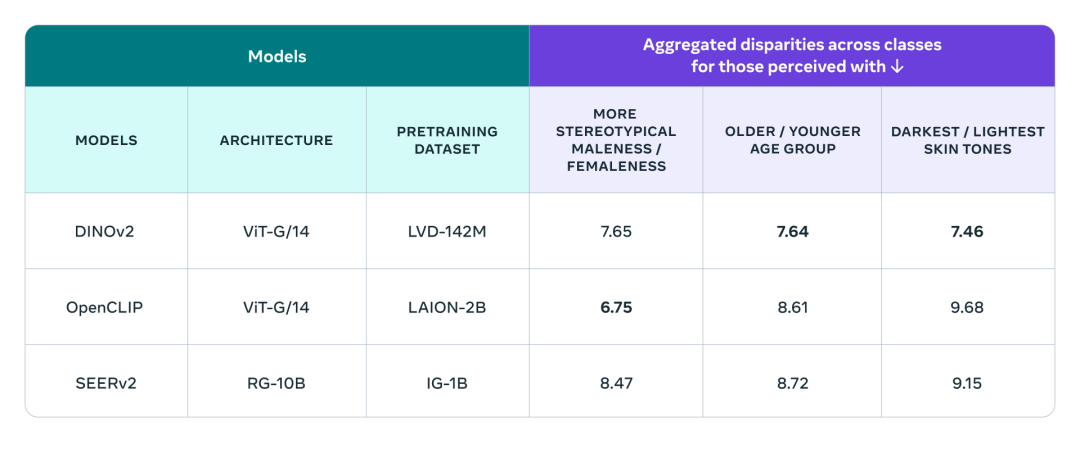
研究结果显示,DINOv2在性能上与其他模型相当:在感知性别方面略逊于OpenCLIP,但在感知年龄组和肤色方面优于其他模型。
FACET评估能够更深入地研究模型的潜在偏见,这是FACET相对于以往的公平性评估基准的优势所在。
尽管SEERv2、OpenCLIP和DINOv2在大多数属性上表现良好,但在某些特定属性上仍存在性别、年龄和肤色方面的偏见。例如,在性别偏见最严重的职业中,如"护士",这三种模型都表现出不同程度的偏见,其中SEERv2和OpenCLIP的偏见更为显著。
这可能是因为SEERv2是在未经筛选的社交媒体内容上进行预训练,导致数据源缺乏多样性。而OpenCLIP使用CLIP视觉语言模型进行数据过滤,但这可能会放大已存在于图像、文本训练数据和模型中的职业和性别之间的关联。
而DINOv2的预训练数据集可能无意中复制了参考数据集中的偏见。例如,如果一个数据集的图像分布不足以代表某些群体,那么会从ImageNet中选择一部分数据作为主要参考,从而导致偏见的产生。
由此可见,计算机视觉模型在某种程度上存在偏见,这对下游任务将会造成了巨大的危害。因此,我们仍然需要进一步改进模型,以确保计算机视觉模型的公平性和公正性。
One More thing
Meta在2021年开源DINO模型,2023年4月开源了DINOV2版本,本次宣布可商用化足以看出Meta在开源上的决心,希望越来越多的优秀模型可以引入到开源社区,开发者一起推进AI技术进步和应用。
