
爬虫实战 | 手把手教你批量爬取某站视频数据
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源:志斌的python笔记 作者:志斌
大家好,我是老表~
这几天一直有小伙伴问B站上的视频数据是怎么获取的,今天就来给大家分享一下批量获取B站视频数据的方式。
大家也可以看看前天发的该死!B 站上这些 Python 视频真香!
即学即用~
01
页面分析
B站的反爬虫技术是信息校验型反爬虫中的cookie反爬虫,我们需要在爬取数据的时候加上cookie,即可绕过该其反爬虫机制。有不懂怎么绕过的小伙伴可以看看这篇文章学会Cookie,解决登录爬取的困扰!。
登陆之后,我们在搜索框随便输入一个想要获取数据的视频名称,我这里以输入Python为例。输入后,我们寻找一下数据的存储位置,我们发现数据存储在源网页中。
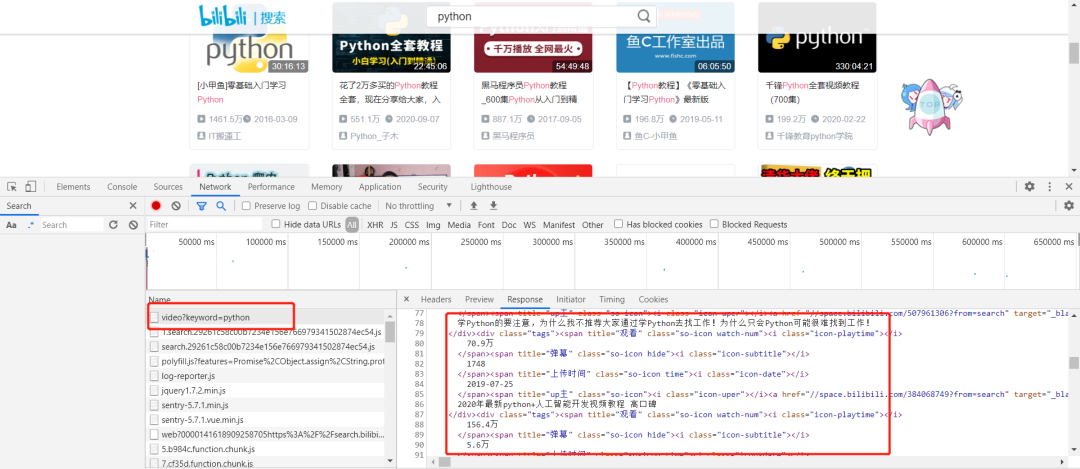
02
数据采集
在上面我们已经找到了数据的存储位置了,现在只需要将它给采集出来即可。
通过对页面的观察我们发现,数据是存储在页面的标签中的。那么我们用BS4对数据进行爬取是最方便的。
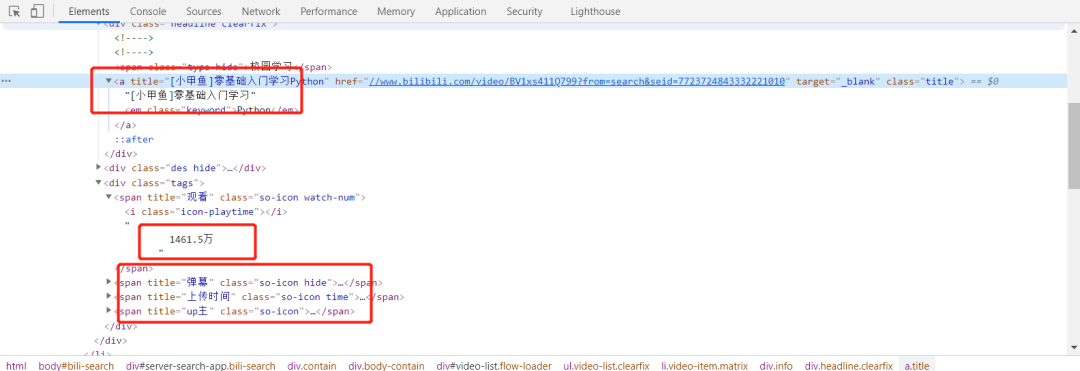
提取数据的核心代码如下:
import requests
from bs4 import BeautifulSoup
import re
import csv
import time
params = (
('keyword', 'python'),
('page', str(page)),
)
response = requests.get('https://search.bilibili.com/video', headers=headers, params=params)
soup = BeautifulSoup(response.text,'html.parser')
zong = soup.find('ul',class_='video-list clearfix')
for i in zong.find_all('li'):
title = i.find(class_='headline clearfix').find('a').text
bofang = i.find(class_='so-icon watch-num').text.split()[0]
danmu = i.find(class_='so-icon hide').text.split()[0]
shangchuanshijian = i.find(class_='so-icon time').text.split()[0]
upzhu = i.find(class_='up-name').text.split()[0]
href = re.findall('(www.*)', i.find('a')['href'])[0]
with open('123.csv', 'a', newline='') as f:
writer = csv.writer(f)
try:
writer.writerow([title,bofang,danmu,shangchuanshijian,upzhu,href])
except:
pass
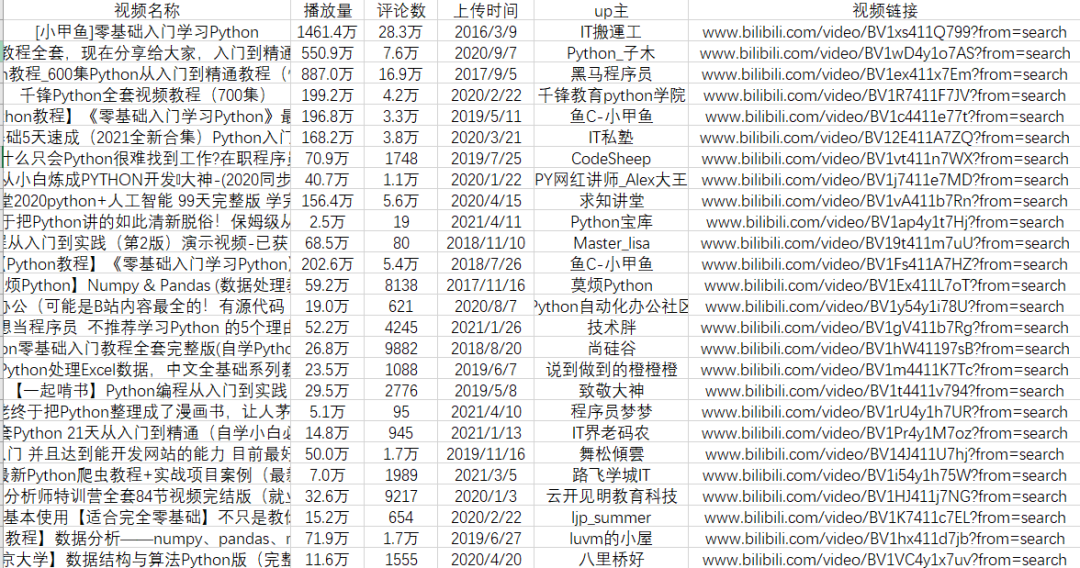
让我们来看看爬取的效果:
03
批量爬取
我发现,在params参数中,有一个keyword参数,当改变这个参数的值时,即可获取相应参数的信息。核心代码如下:
keywords = []
for keyword in keywords:
for page in range(1,51):
params = (
('keyword', keyword),
('page', str(page)),
)
04
小结
1. 以上就是批量爬取B站视频数据的方法。
2. 本文仅供大家学习参考,不做商用。
3. 扫下方二维码添加我微信,回复:B站,即可获得源码。
扫码查看我朋友圈
获取最新学习资源
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢 
评论