
2021-视频监控中的多目标跟踪综述
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
前言 本文来自一篇2021的论文,论文简要回顾了现有的SOTA模型和MOT算法、对多目标跟踪中的深度学习进行了讨论、介绍了评估方面的指标、数据集和基准结果,最后给出了结论。

视频监控中的多目标跟踪(MTT)是一项重要而富有挑战性的任务,由于其在各个领域的潜在应用而引起了研究人员的广泛关注。多目标跟踪任务需要在每帧中单独定位目标,这仍然是一个巨大的挑战,因为目标的外观会立即发生变化,并且会出现极端的遮挡。除此之外,多目标跟踪框架需要执行多个任务,即目标检测、轨迹估计、帧间关联和重新识别。已经提出了各种方法,并做出了一些假设,以将问题约束在特定问题的上下文中。本文对利用深度学习表征能力的MTT模型进行了综述。
多目标跟踪分为目标检测和跟踪两个主要任务。为了区分组内对象,MTT算法将唯一ID与在特定时间内保持特定于该对象的每个检测到的对象相关联。然后利用这些ID来生成被跟踪对象的运动轨迹。检测通常由预先训练的检测器提供,亲和力模型提供检测和方法之间的估计;优化关联
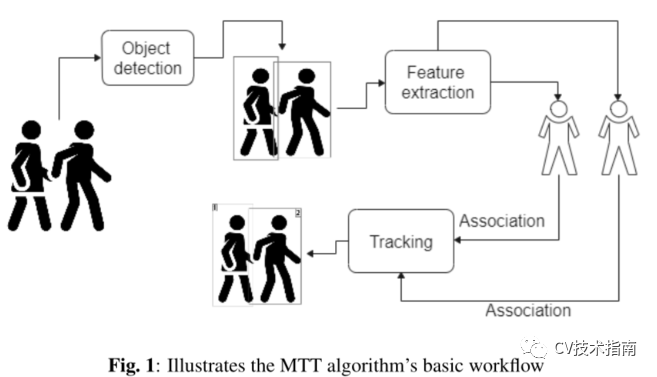
目标检测的精度决定了目标跟踪系统的有效性。MTT模型的精度受比例变化、频繁的id切换、旋转、光照变化等因素的影响很大。图1显示了MTT算法的输出。此外,多目标跟踪系统中存在背景杂波、后移、航迹初始化和终止等复杂任务。为了克服这些问题,研究人员利用深度神经网络,提出了多种策略。
MTT算法的分类
根据对象的初始化方式,MOT实现可分为基于检测(DBT)或无检测跟踪(Detection free tracking, DFT)。然而,MTT模型是围绕基于检测的训练进行标准化的,其中检测(识别帧中的对象)是作为预跟踪步骤来检索的。由于DBT中需要一个目标检测器来识别目标,因此性能在很大程度上取决于检测器的质量,因此选择一个检测框架是至关重要的。
无检测跟踪(DFT)
检测器的输出通常被用作跟踪器的输入,跟踪器的输出被提供给运动预测算法,该算法预测物体在接下来的几秒钟内将移动到哪里。然而,在无检测跟踪中,情况并非如此。基于DFT的模型要求必须在第一帧中手动初始化固定数量的对象,然后必须在随后的帧中对这些对象进行定位。
DFT是一项困难的任务,因为关于要跟踪的对象的信息有限,而且这些信息不清楚。结果,初始边界框仅与背景中的感兴趣对象近似,并且对象的外观可能随着时间的推移而急剧改变。
在线跟踪(Online tracking)
在线跟踪算法,也称为顺序跟踪,根据过去和现在的信息生成对当前帧的预测。这种类型的算法以分步方式处理帧。在一些应用中,例如自动驾驶和机器人导航,这些信息是必不可少的。
批次跟踪(Batch tracking)
为了确定给定帧中的对象身份,批次跟踪(离线跟踪)技术使用前一帧的信息。它们经常使用全局数据,从而提高了跟踪质量;但是,由于计算和内存的限制,并不总是能够一次处理所有帧。
深度学习算法
大多数算法共有的主要步骤如下:
目标检测(Object Detection)阶段:通过分析输入帧,使用边界框在一系列帧中定位目标。
运动预测(Motion Prediction)阶段:分析检测以提取外观、运动或交互特征。
亲和度(Affinity)计算阶段:将提取的特征用于检测对之间的相似度/距离计算。
关联(Association)阶段:通过向对应于相同目标的检测提供相同的ID,在关联中利用相似性/距离度量。
检测阶段
检测阶段主要用的是目标检测中的一些算法。
YOLO单卷积神经网络在一次评价中直接从全图中预测多个bounding boxes和类概率,在全图上训练并直接优化检测性能,同时学习目标的泛化表示。然而,YOLO对边界框预测施加了严格的空间约束,限制了模型可以预测的相邻项目的数量。成群出现的小物件,如鸟类,对于此模型也同样有问题。
faster R-CNN,一个由全深度CNN组成的单一统一对象识别网络,提高了检测的准确性和效率,同时减少了计算开销。该模型集成了一种在区域方案微调之间交替的训练方法,使得统一的、基于深度学习的目标识别系统能够以接近实时的帧率运行,然后在保持固定目标的同时微调目标检测。
在某些监视画面中,遮挡是十分频繁,以至于不可能像在人类的情况下那样检测对象的整个形状。
为了解决这个问题,Khan等人提出了经过训练仅检测头部位置的时间一致性模型(temporal consistency model)。同样,一些技术也被探索到只跟踪头部位置,而不是整个身体形状。
Bewley在EL29上提出了framework SORT,以利用基于CNN的检测的力量,在MOT前景中,它在速度和准确性方面都取得了同类最好的性能,它专注于帧到帧的预测和关联。通过将从聚合信道特征(Aggregated Channel Features, ACF)获得的检测替换为Faster RCNN计算的检测,基于卡尔曼滤波器和匈牙利算法的体系结构,它变得能够被评为性能最好的。在某些情况下,CNN在检测步骤中被用于构建目标边界框之外的其他目的。
对于多目标(如汽车)的跟踪,结合鲁棒检测和二分类器的新策略,对于多车辆的鲁棒和精确识别,Min提出了升级的ViBe。当ViBe算法被用来识别汽车时,CNN用它来消除假阳性。它能有效地抑制动态噪声,并能快速去除鬼影和物体的残留阴影。
运动预测(Motion Prediction)阶段
深度模型用于研究诸如时间和空间注意图或时间顺序之类的MOT特征时,性能可以得到改善。一些基于端到端深度学习的模型,不仅可以提取外观描述符的特征,还可以提取运动信息的特征。
Wang等人提出了最早在MOT管道中应用DL的方法之一。该系统充分利用了单目标跟踪器的优点,在不影响计算能力的前提下解决了由于遮挡造成的漂移问题;为了提高提取特征,网络采用了两层堆叠的编码器,然后利用支持向量机计算亲和度。目标的可见性图被学习,然后被用来推断空间注意图,该空间注意图随后被用来对特征进行加权。此外,可见性贴图还可用于估计遮挡状态。这就是所谓的时间注意过程。
最常用的基于CNN的方法可进一步分为:用于特征提取的经典CNN和siamese CNN。
经典CNN
Kim等人声称多假设跟踪(Multiple Hypotheses Tracking, MHT)技术与现有的视觉跟踪视角是兼容的。现代基于检测的跟踪技术的进步和用于物体外观的高效特征表示的发展为MHT过程提供了新的可能性。他们通过整合一个正则化的最小二乘框架来改进MHT,该框架用于在线训练每个跟踪目标的外观模型。
Wojke等人提出了对SORT的改进,虽然在高帧率下获得了较好的精度和精度,但产生了相对较多的单位移位。Wojke等人通过整合外观运动信息对其进行了改进,通过将关联度量替换为卷积神经网络(CNN),克服了这个问题。卷积神经网络经过训练,可以在大规模的行人重识别数据集中区分行人。与SORT相比,升级的跟踪系统有效地将身份翻转的次数从1423次减少到781次。这减少了约45%,在保持实时速度的同时实现了具有竞争力的性能。
Siamese CNN
Siamese CNN已经被证明在MOT中很有用,因为跟踪阶段的特征学习的目的是确定检测和跟踪之间的相似性。
Leal-taxe等人提出了一种两阶段匹配检测方法的策略,为行人跟踪中的目标关联挑战提供了新的视角。在这种情况下,他们将CNN的概念应用到多人跟踪中,并提出学习两个检测是否属于同一轨迹的判断,以避免手动设计特征进行数据关联。模型的学习框架分为两个阶段。
CNN在Siamese 结构中进行预训练,以测量两个大小相等的图像区域的相似性,然后将CNN与收集到的特征进行合并以产生预测。通过将跟踪问题描述为线性规划,并将深度特征和运动信息与梯度增强方法相结合,它们很好地解决了跟踪问题。
亲和度(Affinity)计算阶段
虽然一些实现使用深度学习模型来立即生成亲和度分数,而不需要特征之间的显式距离度量,但仍然有其他方法通过对CNN获得的特征应用一些距离度量来计算跟踪和检测之间的亲和度。
米兰等人解决了神经网络环境中数据关联和轨迹估计的难题。在线MOT任务中跟踪目标的状态估计采用由观测预测和更新组成的递归贝叶斯滤波器,该模型扩展了RNN对该过程进行建模,将目标状态、现有观测及其对应的匹配矩阵以及存在前景作为输入输入到网络中。该模型输出目标的预测状态和更新结果,以及判断目标是否终止的存在概率,取得了较好的跟踪效果。
Chen等人建议计算采样粒子和跟踪目标之间的亲和力,而不是计算目标和探测器之间的亲和力。取而代之的是,使用与被跟踪对象不一致的检测来创建新的轨迹并恢复丢失的对象。尽管它是一个在线监测算法,但在发表时,它能够在MOT15上获得最好的结果,既使用公共检测,也使用私人检测。
跟踪/关联阶段
在一些MTT模型中已经使用深度学习来改进关联步骤。
Ma等人在扩大Siamese跟踪器网络时,采用了双向GRU来决定在何处终止跟踪器。对于每一次检测,网络提取轨迹特征并将其发送到双向GRU网络,双向GRU网络的输出在欧几里德空间中短暂汇集以提供轨迹的整体特征。在跟踪过程中,根据双向GRU输出之间的局部距离,生成子轨,然后将其拆分成小的子轨;最后,考虑到时间池全局方面的相似性,将这些子轨重新连接到长轨迹。在MOT16数据集上,此方法获得的结果与最新SOTA水平相当。
勒恩等人提出了一种使用多个深层RL(强化学习) 智能体完成关联任务的协同实现方案。预测网络和决策网络是该模型的两个关键组成部分。利用最新的跟踪轨迹,CNN被用作预测网络,并被训练以预测新帧中的目标运动。
其它方法
除了基于以上四个步骤的模型,还存在一些其它的方法。
Jiang等人利用Deep RL代理完成了bounding boxes回归,提高了跟踪算法的效率;采用VGG-16CNN进行外观提取,提取的特征保存并使用目标最近10次运动的历史记录,然后集成网络预测bounding boxes运动、缩放以及终止动作等多种备选结果之一。在MOT15数据集上,在几种最先进的MOT算法上使用这种bounding boxes回归方法,提高了2到7个绝对MoTA点,使其在公共检测方法中名列前茅。
Xiang等人部署MetricNet进行行人跟踪,将亲和力模型与贝叶斯滤波器得到的轨迹估计相结合。利用VGG-16CNN对目标进行再识别训练,提取特征并进行bounding boxes回归,运动模型分为两部分,一部分以轨迹坐标作为输入,另一部分结合检测框进行贝叶斯滤波,并在MOT16和MOT15上输出目标的更新位置,该算法在在线方法中分别获得了最好的和次佳的得分。
无模型单目标跟踪(model free single object tacking) SOT算法的最新进展极大地推动了SOT在多目标跟踪(MOT)中的应用,以提高恢复能力并减少对外部检测器的依赖。另一方面,SOT算法通常被设计成将目标与其周围环境区分开来,当目标在空间上与类似的伪像混合时,它们经常会遇到问题,就像在MOT中看到的那样。
Chu等人提出了一种模型来解决鲁棒性和消除对外部检测器的依赖问题。他们在算法中使用了三种不同的CNN实现了一个模型。集成PafNet以区分背景和跟踪对象。该部分对跟踪目标进行区分,另一个集成的CNN是卷积层,它决定了跟踪模型是否需要刷新。使用支持向量机分类器和匈牙利技术,使用非关联检测来从目标遮挡中恢复。该算法在MOT15和MOT16数据集上进行了测试,第一种方法产生了最好的总体结果,第二种方法产生了在线方法中最好的结果。
评估指标
最相关的是Classical metrics 和 CLEAR MOT metrics。
Classical metrics指出了算法可能遇到的缺陷,如多目标跟踪(MT)轨迹、多丢失(ML)轨迹、ID切换等。
CLEAR MOT metrics有MOTA(多对象跟踪精度)和MOTP(多对象跟踪精度)。MOTA将假阳性、假阴性和失配率合并为单个值,从而产生总体良好的跟踪性能。尽管有一些缺陷和抱怨,但这是迄今为止使用最广泛的评估方法。MOTP描述了使用边界框重叠和/或距离测量来跟踪对象的精确度。
基准数据集
基准数据集包括 MOTChallenger、KITTI、UADETRAC。
MOTChallest数据集是目前可用的最大、最完整的行人跟踪数据集,为训练深度模型提供了更多的数据。MOT15是最初的MOT挑战数据集,它的特点是视频具有一系列属性,模型需要更好地推广这些属性才能获得好的结果。MOT16和MOT19是其他修改版本。
基准结果
如下为Gioele等人列出在MOT ChallengeMOT15数据集和MOT16数据集上测试的公开结果,这些数据集记录自相应的出版物,以便对本工作中提到的方法之间的结果进行清晰的比较。
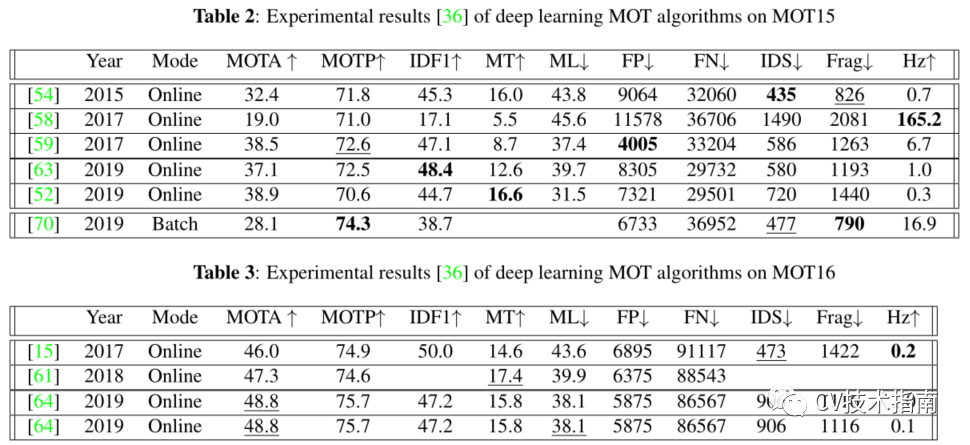
由于检测质量对性能有影响,因此将研究结果分为基于公共检测的模型和基于私有检测的模型。这些方法分为两类:在线和离线。
发布的参考文档的年份、其操作模式、MOTA、MOTP、IDF1、主要跟踪(MT)和主要丢失(ML)指标,以百分比表示;假阳性(FP)、假阴性(FN)、ID开关(IDS)和碎片(Frag)的绝对数;以每秒帧数(Hz)表示的算法速度。
对于每个度量,向上的箭头(↑)表示更高的分数,而向下的箭头(↓)表示相反的分数。在运行相同模式(批处理/在线)的模型中强调最佳性能,并且每个统计数据都以粗体突出显示。我们只在表2和表3中列出了从本综述中访问的模型获得的结果。
在现实中,使用深度学习和具有在线处理模式的模型产生了最大的结果。然而,这可能是更加重视建立在线方法的结果,这在MOT深度学习研究社区中变得越来越流行。大量的碎片化是在线方法中经常出现的问题,这在MOTA得分中没有反映出来。当遮挡或探测丢失时,在线算法不会向前看,不会重新识别丢失的目标,也不会插入视频中丢失的轨迹片段。
结论
本文对利用深度学习解决MTT问题的方法进行了简要的探索。这项研究讨论了使用深度学习来解决MTT问题的四个步骤中的每一个步骤的解决方案,使SOTA的MOT技术的总数达到n。
对MOT算法的评估,包括评估措施和来自可访问数据集的基准结果,进行了简要的讨论。单对象跟踪器最近受益于将深度模型引入全局图优化算法,从而产生了高性能的在线跟踪器;另一方面,批处理技术受益于将深度模型引入全局图优化算法。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
