
大厂架构都开始做机房多活了
共 3306字,需浏览 7分钟
·
2021-07-31 08:25
写在前面
B站挂了的那天,就想写写机房多活的文章,但考虑到这方面的技术面涉及比较广,一时无从下手就拖到了现在,未来会陆续基于“多活”这个话题聊一聊我的经验。

在互联网行业,一定规模的业务做“异地多活”都是标配了,做好“多活”价值很大,当然做好“多活”设计也很难,涉及到网络、数据、事务、冗余等各种挑战。需要解决多活带来的技术问题,比如“怎么保证跨机房数据的一致性”、“如何保证异地事务一致性”、“怎么在多个异地之间无缝切换”。
通用的多活架构
我们先看一个通用的多活架构图是什么样的,如下图所示:
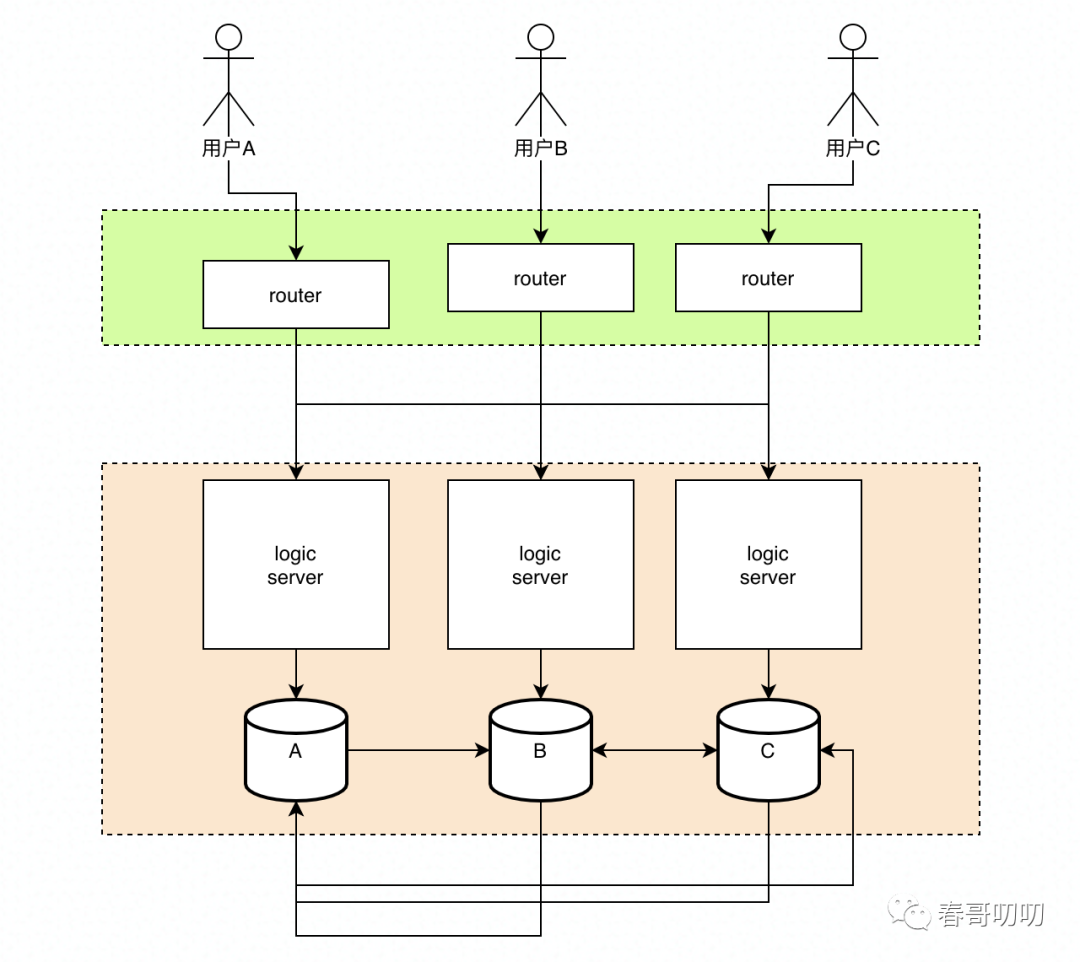
上图可以看做是一个基于用户分区的架构,每个用户有自己所属的分区,在每个分区内有用户自己相关的主要数据。比如用户A主数据分区是A,用户B主数据分区是B。
用户可以就近接入离他最近的机房,Router层可以看做是一个Nginx or LVS的路由层,我们将路由规则下发到这层,基于用户数据(手机号、uid等)做hash,路由到不同的数据分区,应用服务与数据自闭环在分区内。
为提高分区的容灾能力,每个分区冗余另外两个分区的数据,比如A分区里面除了有自己的分区数据外,还有B、C分区的数据。
业务上的取舍
多活本质上也是可用性的一种保障机制,做好可用性,大家首先想到的就是冗余,而冗余是有成本的,成本包括资源成本和系统因为高可用复杂度提升的人力成本。
所以多活首先要做的就是服务分级,只有那些核心链路上的核心业务才有必要投入这些成本做多活。
也就是说:不是所有业务都需要做异地多活,核心业务才需要。
架构本质是取舍,我们看看如何基于核心业务场景做业务上的取舍。
想象一个问题,比如A用户本来的数据分区是A,但如果A挂掉了,想让A用户到分区B继续工作,由于数据同步是异步的,可能这时B里面并不是所有的A用户数据都有。
这个问题是常态,所以就需要考虑我们业务上是否可以低成本方式兼容类似的问题了。
以注册为例,如果A用户注册数据没有同步到B分区,那在B分区A用户就不能工作了吗?肯定不是。
在业务上让用户A在分区B重新注册就好了,这部分数据一致性与可靠性要求不高。通过这种方式,注册功能就无形中实现了“多活”。
所以让那些真正核心业务做好多活即可,以B站为例,登录、看视频是核心业务场景,充会员、打赏火箭有可能都不是核心业务,也不需要花费成本做多活了。
解决异地数据不一致的关键方案
上面的例子提到了,解决一些业务多活的方式可以是允许不同分区内存在数据不一致的情况,那如果故障恢复之后,如何解决不同分区下数据一致性问题呢?简单来说就是应该用哪份数据?
有可能后修改的数据由于分区之间异地延迟,导致先生效,反之也同样成立。
大部分场景此类问题解决起来并不复杂,可以看成以后修改的为准即可。但这个先后的判断,不能以时间看,因为不同机器、不同机房的时间可能是不准的,最好的方式是采用全局唯一自增id,类似于Snowflake方式,谁大依赖谁。
但需要考虑好这个唯一id生成服务的异地多活,我觉得还好,可以把这个id生成服务部署为分区内独立的,id生成就不存在冲突了。
解决数据不能实时同步的矛盾
做多活,还存在一个误区:“数据需要百分之百实时同步”。
这是不可能的,以北京到上海为例,网络传输延迟20~30ms,再加上上层业务处理的话,可能延迟在秒级,所以百分百实时同步数据是不可能的。
如何平衡业务上要求数据快速同步,而物理上做不到数据快速同步这个矛盾呢?
完全解决这个矛盾是不可能的,我们能做的就是降低这个矛盾:
尽量减小异地机房之间的距离,搭建专线;
尽量减少数据同步数量;
保障最终一致性,不保证实时一致性;
业务层面容错处理;
尽量减小异地机房之间的距离,搭建专线
减小异地机房之间的距离,可以采用同城双活的方式,就是在一个城市里面搭建多个多活机房,这样这些机房可以逻辑上看成一个机房。
这种方案的优点是:提高了性能;缺点是:不能做到城市层面的容灾。
尽量减少数据同步数量
由于数据同步需要占用机房之间专线带宽,所以尽量只同步需要的数据,不需要的不同步。
保障最终一致性,不保证实时一致性
既然物理上我们难以实现实时性,所以必须接受最终一致性这个事实。反映在架构上,就是我们需要面对最终一致性这个特点设计架构方案。
不同存储场景需要考虑不同最终一致性的时间窗口,是30ms、30s还是3小时,我们在技术层面需要根据不同的业务特点进行差异化的技术实现,以满足业务需求。
业务层面容错处理
将流量切到不同分区下,可以视为出现了系统故障。一般我们做降级、切流操作过程中,业务可能是有损的。也就是哪怕我们做了多活可用,也不能让业务实现百分百的可用性,很多时候我们只需要实现99.99%即可。
所以业务上需要针对于这个损失窗口做一定的容错设计,提高用户体验。比如分区内缓存兜底、用户动线跳转等,降低对于实时同步数据的依赖。
数据同步
通过上面内容可以看出来,做多活最重要的是对于有状态服务的处理,数据同步是实现多活方案的核心。
常用的中间件本身都具备一定的数据同步方案,比如mysql的主备复制、redis的cluster功能、es的集群功能,但仅仅采用这些存储中间件提供的复制功能是不能解决异地数据复制的问题的。
比如mysql的主从复制,大部分场景是满足的,但对于这种跨异地机房的数据同步场景来说,mysql单线程复制功能在网络抖动时经常发生延迟问题,短则十几秒,长则十几分钟。而且mysql主从复制出现问题时,尽管发现了,但是没办法快速通过扩容方式解决,只能干等。
Redis 3.0之前的主从同步方案存在一个问题,当从机宕机或者与主机断开重连时,会触发全量的主从复制,这时主机会生成大量内存快照,由于数据量大,同步恢复时间长,从机就不能对外提供服务了。
所以光依靠存储系统本身的同步复制功能,在一些场合是不满足业务需求的。特别是异地机房这种场景,宽带有限,长距离传输,网络抖动常态的情况下,光依靠存储系统的同步功能是不能实现多活的。
为解决以上问题,大部分场景还是需要基于MQ实现最终的异地数据复制。一方面自研更适合我们的业务场景,同时MQ本身具备很好的扩容能力,在同步数据有压力的情况下,可以快速进行扩容解决复制延迟问题。
其他数据同步方式:
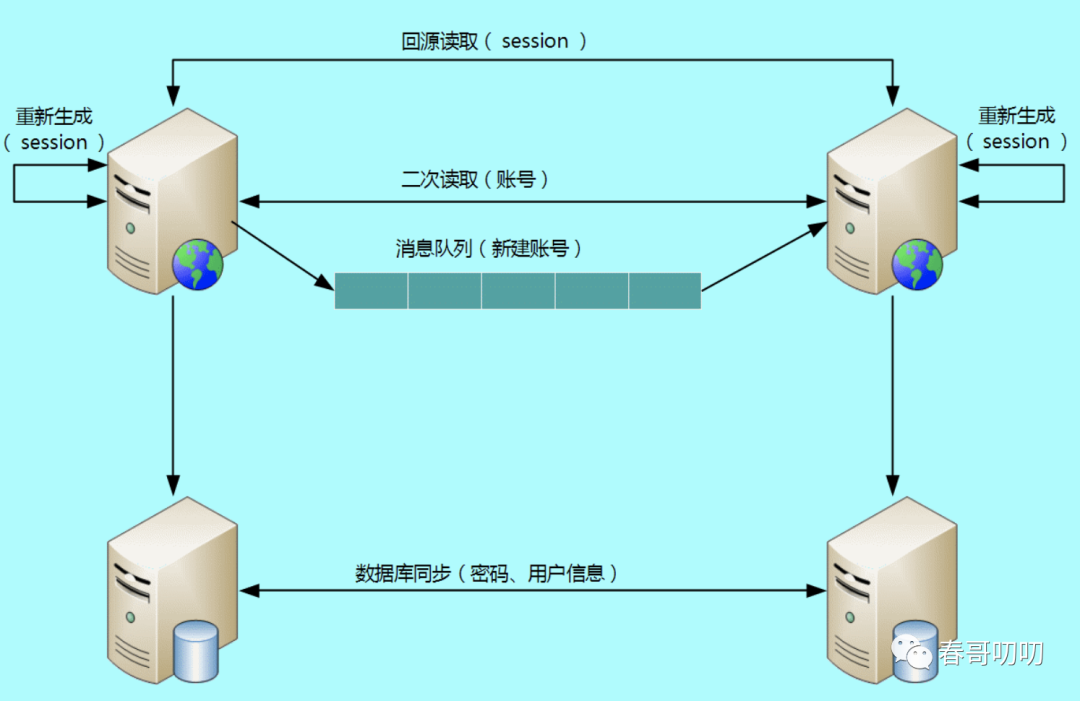
消息队列同步方式;
二次路由方式:当消息队列同步延迟了,导致目标分区没有数据,可以强制读取原分区获取数据,当然这种只是解决流量进入错误的分区,而不是分区故障的路由;
存储系统主从复制方式:为提高一个分区内多机房的可用性(一般是同城双活这种),可以采用存储系统的主从同步复制能力,比如mysql的主从;
重新生成方式:还有一种方式,数据不需要做跨数据中心的数据同步,或者可以容忍数据同步的丢失或延迟,所以解法可以是数据重建。比如分区内的缓存数据,可以基于跨数据分区同步,也可以基于分区内元数据重建即可;
我们需要做到多活的百分百可用吗?
百分百可用不可用达到,没有任何一个系统可以承诺自己百分百可用。但如果有的业务要求百分百可用怎么办呢?
按照CAP定理来说,这属于CP系统,对于一致性要求高,那么只能舍弃A(可用性)了。
这种场景一般是银行类业务,比如小明办理了招商银行账号,想通过招行转账的话,需要确保招行数据中心是可用的。不然会出现数据不一致问题,解决允许转账再处理数据问题的成本远大于不让转账的成本与风险,不让转账是最合理的选择。
其实我们使用银行类APP转账时,可以看到他有自己的一些处理方式,比如交易时间内不允许操作,先锁金额记录流水再转账等。可以发现为了提高系统对于金钱的一致性处理,业务上牺牲了体验,但这种体验的缺失是可以接受的。
如果想让体验更好一点的话,可以做些降级层面的体验优化,比如挂公告:研发小哥哥在紧急处理问题哦,或做事后的优惠券补偿,这是我们经常采用的一种方式,给用户发券既可以提升体验,又可以增加转化率可能。