
吴恩达,确诊新冠阳性
点击“开发者技术前线”,选择“星标”
让一部分开发者看到未来

转载自:新智元 | 编辑:好困 袁榭
点击“开发者技术前线”,选择“星标”
让一部分开发者看到未来
转载自:新智元 | 编辑:好困 袁榭
【导读】当代人工智能领域最权威的学者之一吴恩达,于2022年2月8日晨在自己推特上宣布新冠检测结果阳性,不过症状轻微。
北京时间,2022年2月8日早上6点,吴恩达新冠病毒检测呈阳性。
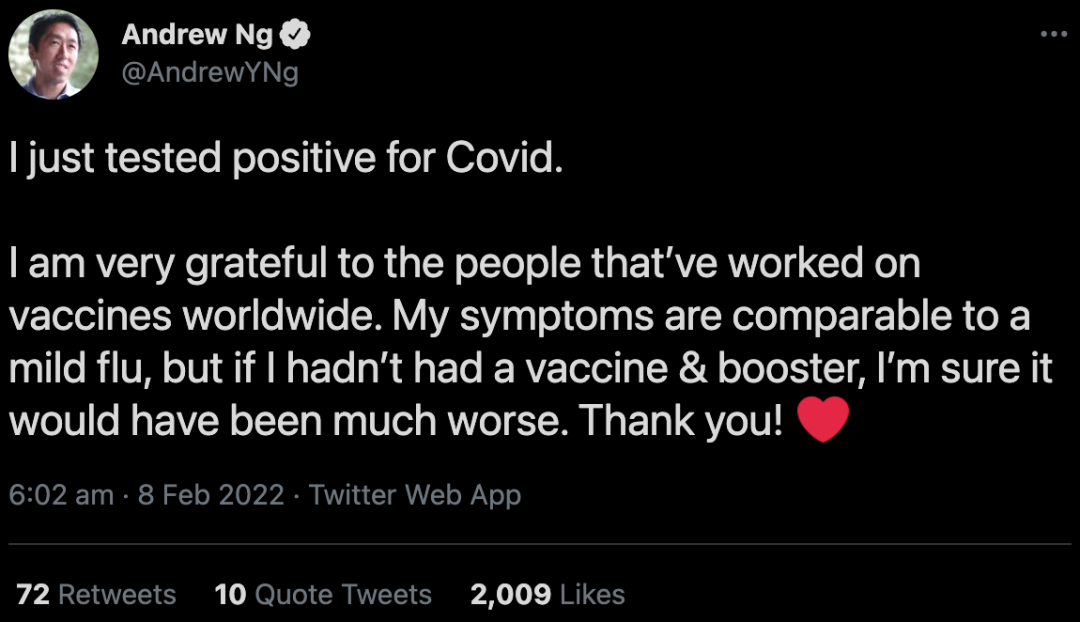
吴恩达表示,由于自己已经接种了疫苗和加强针,目前的症状和与轻度的流感差不多。感谢全世界从事疫苗工作的人们。
大年初一的时候,他还发推祝大家虎年快乐。
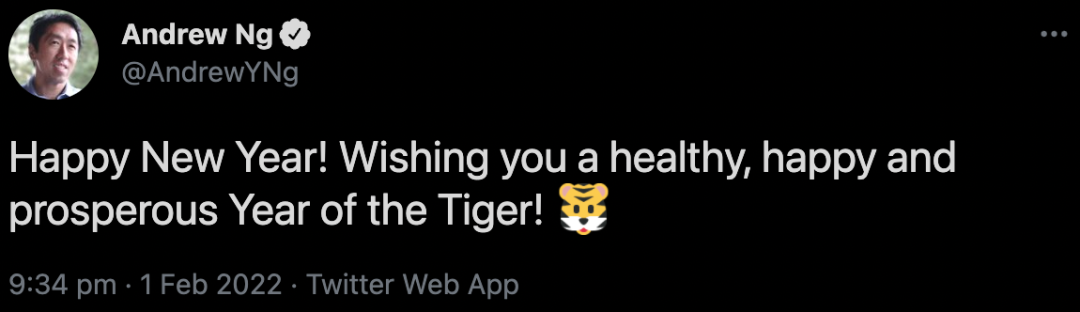
还有不到3个月就要过46岁生日了,希望大佬好好休息,早日康复。
成就一览
成就一览
吴恩达无疑是当代人工智能和机器学习领域最权威的学者之一,同时在商业上也颇有建树。
吴恩达是斯坦福大学计算机科学系和电气工程系的客座教授,曾任斯坦福人工智能实验室主任。
吴恩达的理想是让世界上每个人能够接受高质量的、免费的教育。于是便与达芙妮·科勒 (机器学习界的一姐和大牛,《Probabilistic Graphical Models: Principles and Techniques》的作者)一起创建了在线教育平台Coursera。

吴恩达于1976年出生于英国伦敦。他的父母都是来自香港的移民。在成长过程中,他在香港和新加坡度过了一段时间,后来于1992年从新加坡莱佛士书院毕业。
1997年,他获得了宾夕法尼亚州匹兹堡卡尼基美隆大学班级顶尖的计算机科学、统计学和经济学三重专业大学学位。1996年至1998年间,他在AT&T贝尔实验室进行了强化学习,模型选择和特征选择的研究。
1998年,吴恩达在马萨诸塞州剑桥的麻省理工学院获得硕士学位。在麻省理工学院,他为网络上的研究论文建立了第一个公开可用,自动索引的网络搜索引擎(它是CiteSeer/ResearchIndex的前身,但专注于机器学习)。

趣味哏图:「当你看到以下片头标时,就会知道影视产品很棒:20世纪佛克斯、派拉蒙、华纳兄弟、吴恩达微笑」
2011年,吴恩达在谷歌创建了谷歌大脑项目,以通过分布式集群计算器开发超大规模的人工神经网络。
2014年5月16日,吴恩达加入百度,负责「百度大脑」计划,并担任百度公司首席科学家。2017年3月20日,吴恩达宣布从百度辞职。
2017年12月,吴恩达宣布成立人工智能公司Landing.ai,担任公司的首席执行官。

趣味哏图:「AI的文艺形象是终结者,真实形象是吴恩达公开课」
作为教师,他保持一项纪录:在2013-1014年斯坦福大学秋季学期的「机器学习」课程中,这门由吴恩达主讲的课程有超过800名学生选修。这曾是斯坦福历史上最多人同时选修的课程。
没有任何教室可以容纳,所以很多人都是在家看课堂录像。不过这门计算机专业的研究生课程比Coursera上的同名公开课要难很多,用他自己的话来说就是“这(和Coursera上的相比)可以说是两门课”。

吴教授公开课金句:「听不懂先不要怕」
他在斯坦福公开课与Coursera里主讲机器学习,效果极佳,在业界和普罗大众中都非常受欢迎。

趣味哏图:「女友:你看泰坦尼克都不哭!难以置信!你究竟有没有感情!你哭过没有!AI学子:有啊,吴恩达公开课结尾出手写感谢字幕的时候。」
吴恩达在Coursera上的机器学习课程,平均得分4.9分。Coursera上的课程评分满分5分,大部分公开课处于4-4.5分之间,能做到4.9分的课程很少,而这门课程有近五万人给出评分。按Freecodecamp的统计,这是机器学习在线课程中最受欢迎的一门。

吴恩达的公开课程中高数内容相对不多,在同类公开课中比较亲善大众。他解释过原因:「这门课没有使用过多数学的原因就是考虑到其受众广泛,因此用直觉式的解释让大家有信心继续坚持学习。」

趣味哏图:「吴恩达公开课,默默为AI新丁挡下了微积分、线代、统计、概率论这些高数火力,让学子们得以安眠。」
80%的数据+20%的模型=更好的机器学习
80%的数据+20%的模型=更好的机器学习
机器学习的进步是模型带来的还是数据带来的,这可能是一个世纪辩题。
吴恩达对此的想法是,一个机器学习团队80%的工作应该放在数据准备上,确保数据质量是最重要的工作。
「AI = Data + Code」
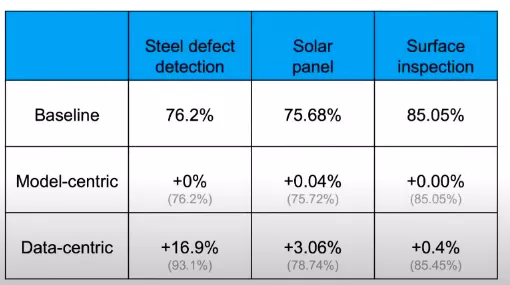
出现问题时,大部分团队会本能地尝试改进代码。但是对于许多实际应用而言,集中精力改善数据会更有效。
吴恩达认为,如果更多地强调以数据为中心而不是以模型为中心,那么机器学习将快速发展。
我们都知道Google的BERT,OpenAI的GPT-3。但是,这些神奇的模型仅解决了业务问题的20%。而剩下80%就是数据的质量。
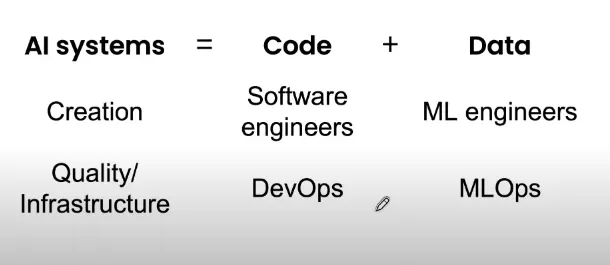
MLOps是什么?
MLOps是什么?
MLOps,即Machine Learning和Operations的组合,是ModelOps的子集。
它是数据科学家与操作专业人员之间进行协作和交流以帮助管理机器学习任务生命周期的一种实践。
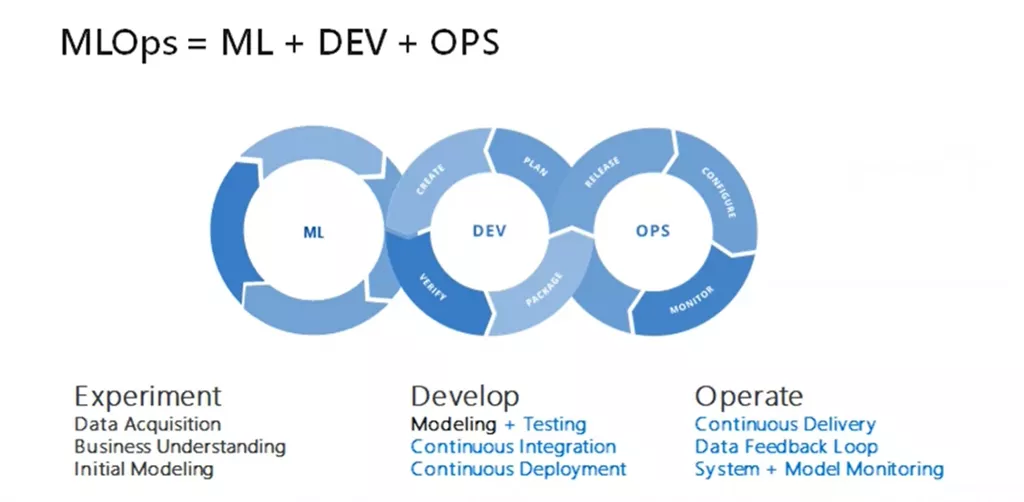
与DevOps或DataOps方法类似,MLOps希望提高自动化程度并提高生产ML的质量,同时还要关注业务和法规要求。
比如在缺少数据的应用场景中进行部署AI时,例如农业场景,你不能指望自己有一百万台拖拉机为自己收集数据。
基于MLOps,吴恩达也提出几点建议:
MLOps的最重要任务是提供高质量数据。 标签的一致性也很重要。检验标签是否有自己所管辖的明确界限,即使标签的定义是好的,缺乏一致性也会导致模型效果不佳。 系统地改善baseline模型上的数据质量要比追求具有低质量数据的最新模型要好。 如果训练期间出现错误,那么应当采取以数据为中心的方法。 如果以数据为中心,对于较小的数据集(<10,000个样本),则数据容量上存在很大的改进空间。 当使用较小的数据集时,提高数据质量的工具和服务至关重要。
参考资料:
https://twitter.com/AndrewYNg/status/1490808144267673601
— 完 —
点这里👇关注我,记得标星呀~
前线推出学习交流一定要备注: 研究/工作方向+地点+学校/公司+昵称( 如算法+上海 扫码加微信,进群和大佬们零距离
后台回复“电子书” “资料” 领取一份干货,数百面试手册等你 开发者技术前线 ,汇集技术前线快讯和关注行业趋势,大厂干货, 是开发者经历和成长的优秀指南。