
【时间序列】基于一维卷积自动特征提取的短期用水需求量预测

今天带大家精读的论文是 《Short-term water demand forecast based on automatic feature extraction by one-dimensional convolution(基于一维卷积自动特征提取的短期用水需求量预测)》。该论文是一篇以短期用水量需求预测为背景的Rearch paper,由同济大学环境科学与工程学院、同济大学智能水联合创新研发中心与阿里云计算有限公司联合发表。

所属期刊《Journal of Hydrology(水文学杂志)》是地球科学大类下中科院1区top,影响因子5.722。
*中科院分区以2021年12月最新升级版为准。
框架结构
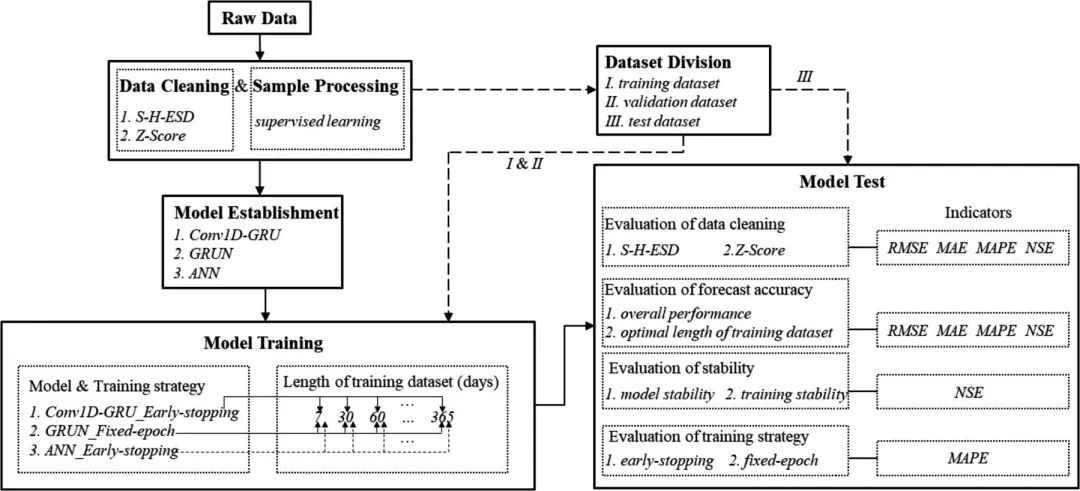
亮点:
离群值处理方法S-H-ESD(通过分析STL新生成的残余项,从统计学角度甄别离群值) 一维卷积+GRU(较为常见,学习思想) 随机选取不同位置、不同长度的数据集进行训练 新颖的验证集调整超参数的训练策略early-stop strategy
1 S-H-ESD
S-H-ESD (Seasonal Hybrid Extreme Student Deviate)离群值处理方法是由Rosner在1983年提出的方法[1],能够解决残余项上的异常值问题。为了获取残余项,该方法首先通过STL分解方法将原始序列分解为季节项、趋势项和残余项,但考虑到此方法分解出来的残余项可能包含虚假异常,或多或少会影响去除异常值的效果,因此将求残余项的公式由
 改为
改为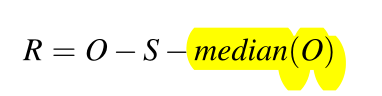 其中
其中median(O)代表原始时序的中值。这样求出来的残余项中带有部分趋势项,降低去除虚假异常的风险。之后,采用Grubbs[2]方法将最大(小)的前k个值标记为离群值进行处理。
2 Conv1D-GRU
卷积神经网络对于对于初次接触卷积神经网络的人来说,需要知道卷积神经网络多应用于提取数据的特征,其中最常见的是二维卷积(提取图像特征)和一维卷积(提取时间序列的信号特征)。当然,除此之外还有用于视频处理领域的三维卷积,在此不做描述。
卷积神经网络包括三个环节:卷积层、池化层、全连接层。
卷积层:提取信息中的特征 池化层:将提取出来的信息进行压缩,抓住主要特征的提高特征提取效率 全连接层:将捕获出来的特征进行整合,生成一个非线性特征组合
为了更好地理解卷积,我们先从二维卷积开始理解,见图:

对于上述图片中的内容有几点我做下解释:
卷积如何计算 以图片上5*5的卷积核(即过滤器)为例,在14*14的输入数据里面所有5*5的网格中依次游走遍历,每一次都将卷积核与输入数据中对应方格中的数字相乘并加和,卷积的结果是得到一个10*10数据维度的输出结果。 channel 由于任意颜色均是由红黄蓝三原色组成,每一个图片均可看作由红、黄、蓝三个图层的叠加,所以在提取图像特征时,为提取更多局部特征,channel通常取3。 卷积核数量 卷积核的数量是自己设定的,但必须为channel的倍数。举个栗子,如果一个图像计划使用3个卷积核去自动提取特征,仅考虑一个channel时有3个卷积核,若该图像此时分了3个channel则会出现3*3=9个卷积核(每个channel分别训练3个卷积核)。 卷积核如何确定 卷积核不是自己凭空设定的,是训练出来的。
对于池化层,我们通过这张图能够更直观的理解: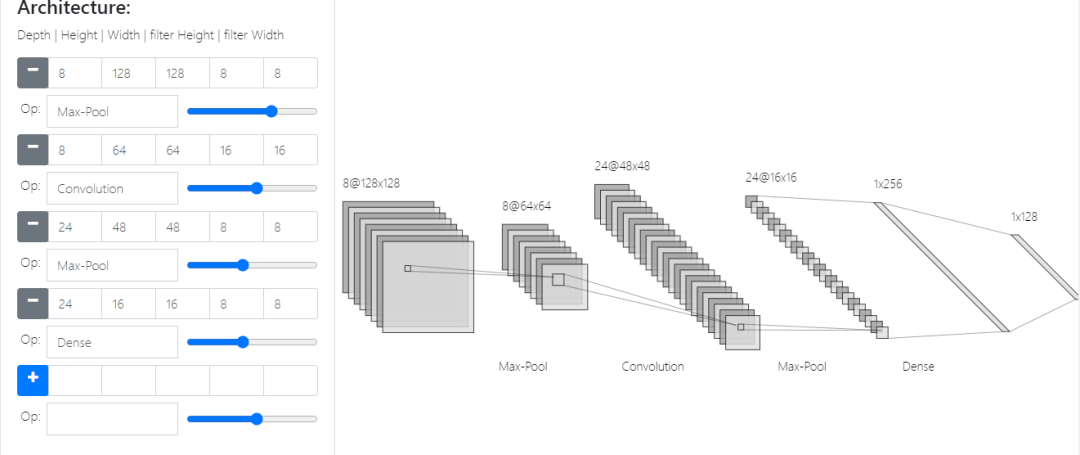
池化层的主要目的是对输入的数据进行压缩,例如上图中出现了两层池化层,都是对上一层的输出在channel不变的情况下进行主要的特征提取,从左到右第二个池化层中将上一层的24个48*48的信息压缩成了24个16*16的网格。池化常见的Max-pool的压缩方式是在某一区域内选取一个最大值。
一维卷积与二维卷积原理相同,相信理解大致的二维卷积神经网络之后能够很顺畅的将思想迁移到一维卷积上来,只不过输入数据是1*n,同样卷积核是1*m的数据格式,如下图。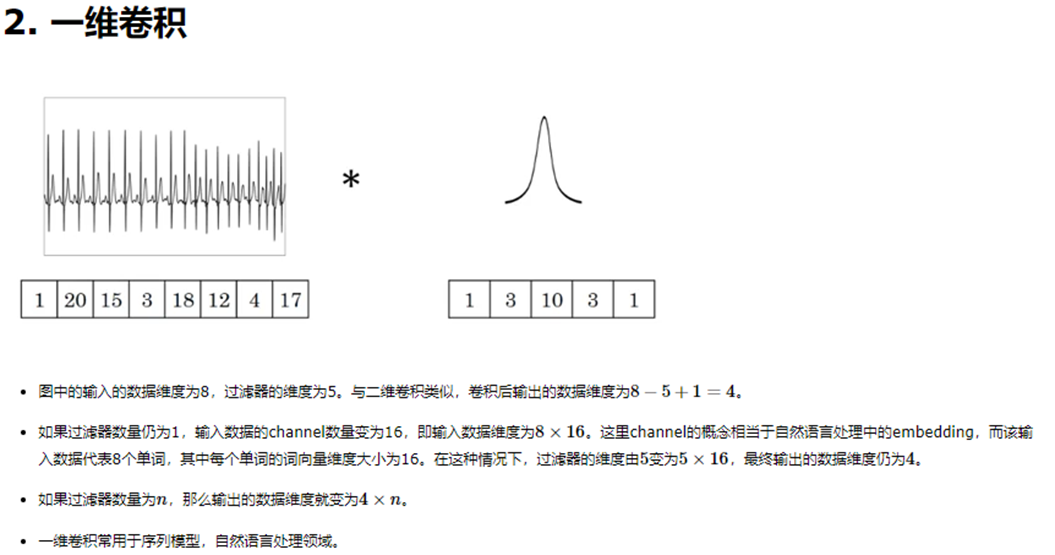
3 数据划分
本文选取的数据是湖州某一水厂从2017年1月1日到2019年5月31日的用水量,采样时间间隔为15min。本文在训练模型的时候在数据集划分上也做了讨论。其采用随机抽样法在全部数据中随机选取一个数据点,对于该点之后的六天,前三天作为验证集,后三天作为测试集,该点之前的训练集长度又分了7种情况,分别是选取数据点的前7、30、60、90、120、180、365天数据。也就是说每一次随机选取的时间点都能创建7组划分数据集的方式,总共随机抽样10次。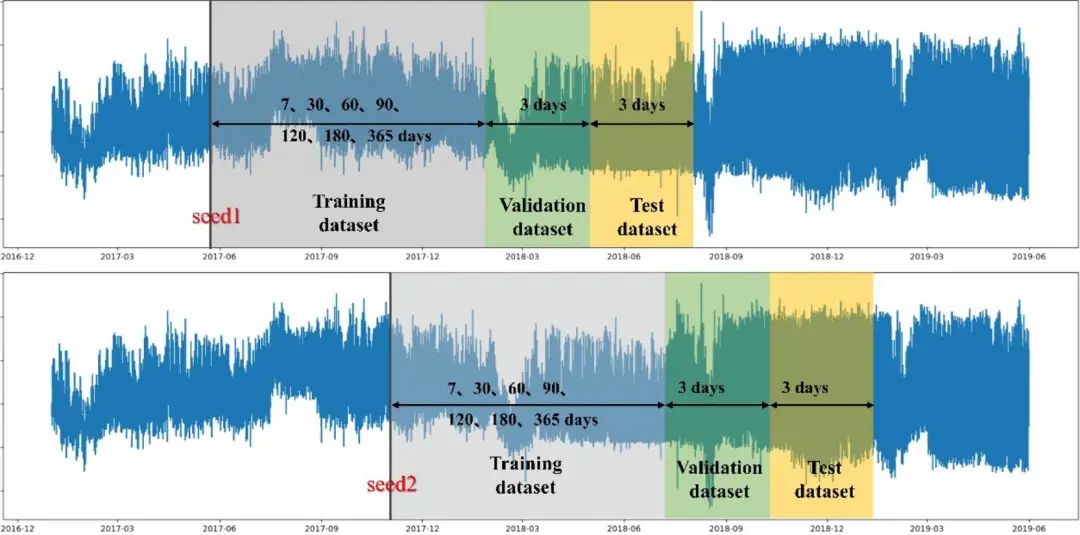
4 Early-stop strategy
如何避免神经网络在训练过程中出现过拟合和欠拟合的现象是深度学习中的一个关键问题,找寻一个适配的超参数组合是至关重要的,常用的训练策略为退出策略、正则化策略等,这些方法需要在训练开始前进行设置次数,但由于数据和训练过程的不确定性,训练次数的设置很难拿捏。本文所采用的early-stop strategy是一种适应性训练策略,将训练模型的总次数设置为一个较大的数值(例如10000),通过检测模型对验证集的影响来判断模型训练是否结束,当模型对于验证数据集的效果不再改善时,终止训练,并保存训练结束前的最优神经网络参数。
参考资料
S-H-ESD方法: 10.1080/00401706.1983.10487848
[2]Grubbs方法: 10.1080/00401706.1969.10490657

—END—
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: