
重磅!微软在 GitHub 又一开源力作面世,代号「女娲」!
开发者全社区
共 5400字,需浏览 11分钟
·
2021-12-18 22:28
相关阅读:杭州程序员从互联网跳央企,晒一天工作和收入,网友:待一年就废






论文地址:https://arxiv.org/pdf/2102.12092.pdf



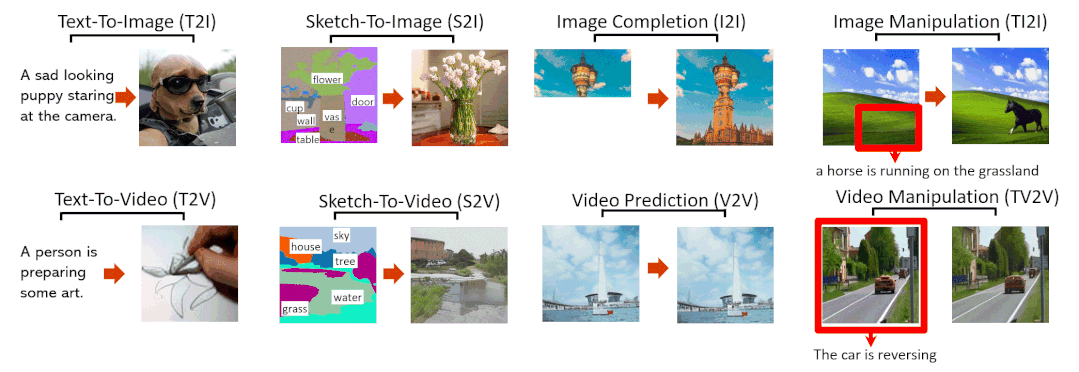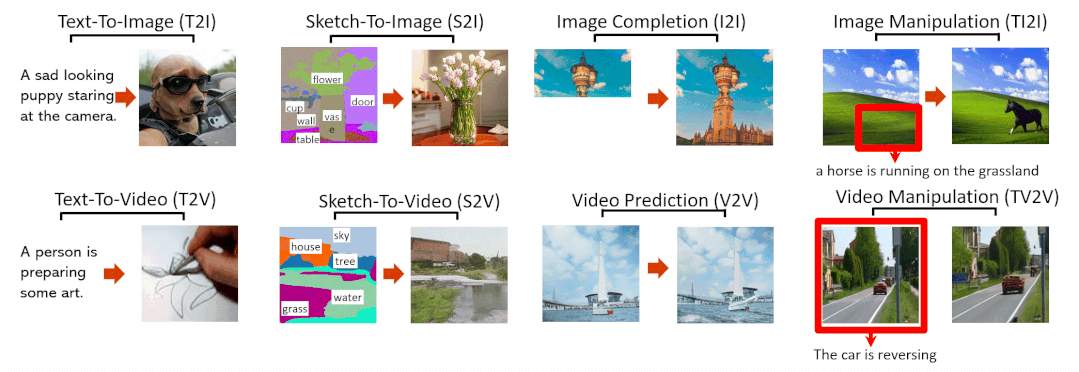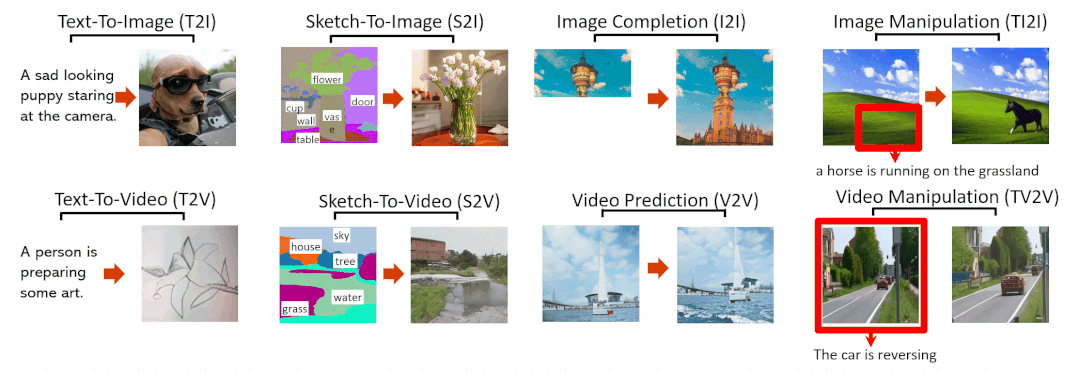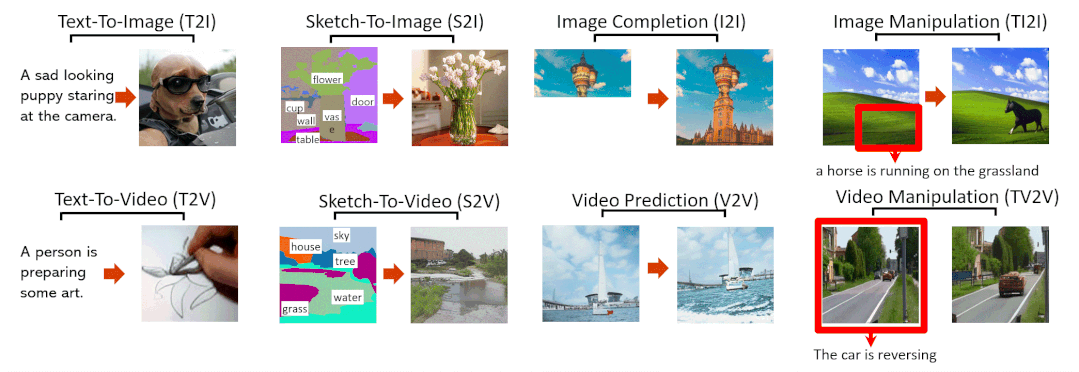
文字转图像(Text-To-Image,T2I)

草图转图像(SKetch-to-Image,S2I)

图像补全(Image Completion,I2I)

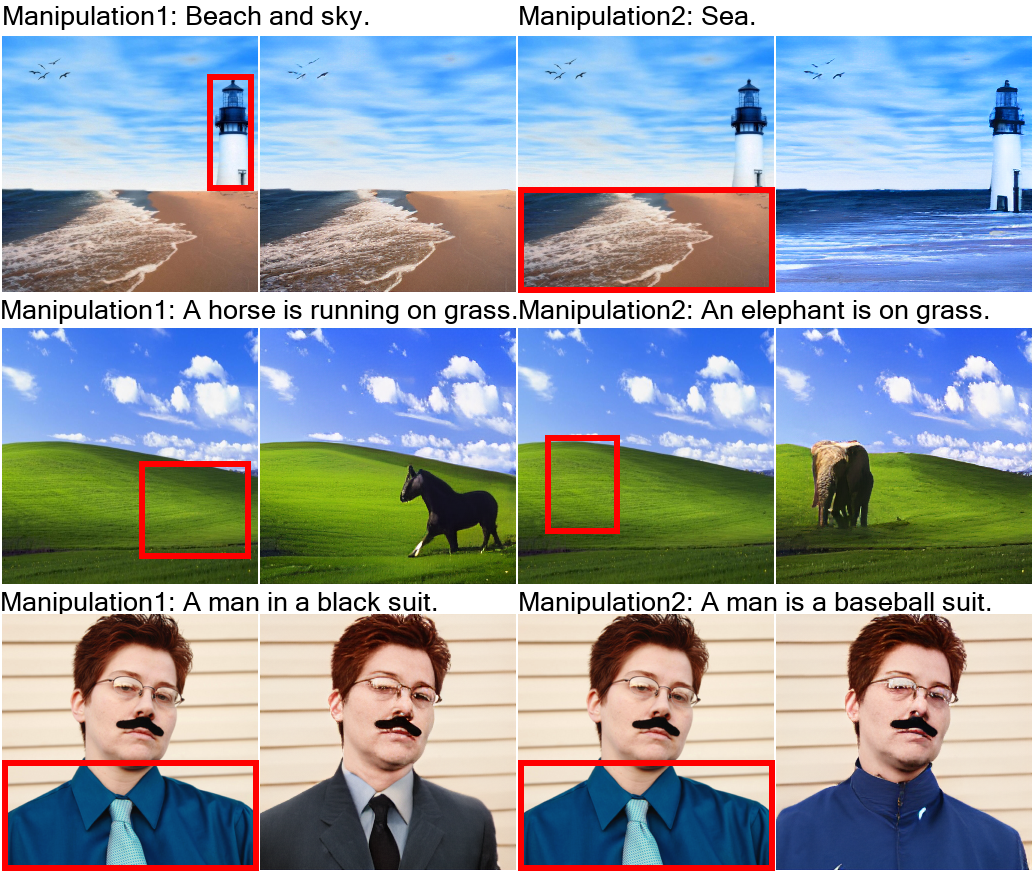
用文字指示修改图像(Text-Guided Image Manipulation,TI2I)
文字转视频(Text-to-Video,T2V)
视频预测(Video Prediction,V2V)

草图转视频(Sketch-to-Video,S2V)

用文字指示修改视频(Text-Guided Video Manipulation,TV2V)

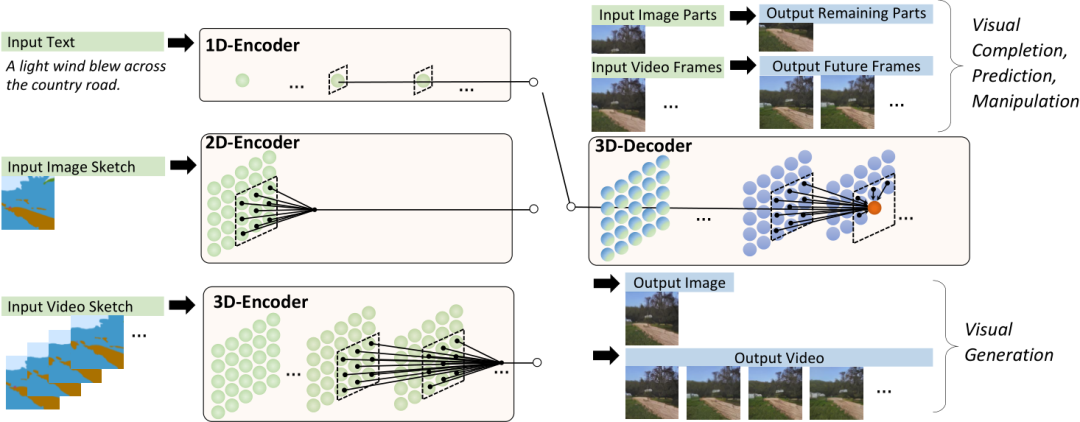
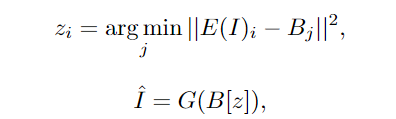
视频可以被视为图像的一种时序展开,最近一些研究如 VideoGPT 和 VideoGen 将 VQ-VAE 编码器中的卷积从 2D 扩展到 3D,并能够训练一种针对视频输入的特殊表征。
但这种方法无法使图像和视频的表示统一起来。研究人员证明了仅使用 2D VQ-GAN 就能够编码视频中的每一帧,并且能生成时序一致的视频,结果表示维度为 h×w×s×d,其中 s 代表视频的帧数。
对于图像素描(image sketch)来说,可以将其视为具有特殊通道的图像。

基于统一的 3D 表示,文中还提出一种新的注意力机制 3D Nearby Self-Attention (3DNA) ,能够同时支持 self-attention 和 cross-attention。
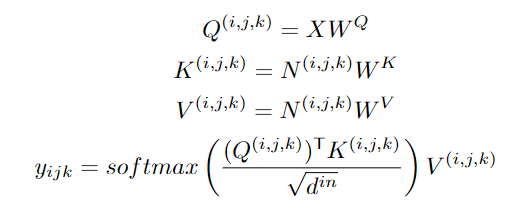
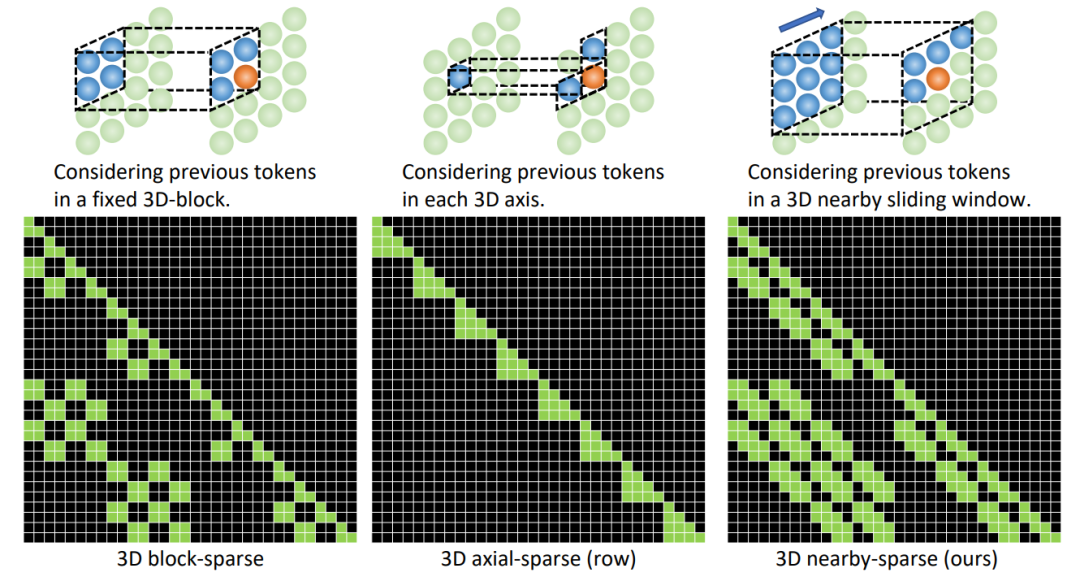
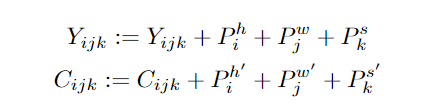
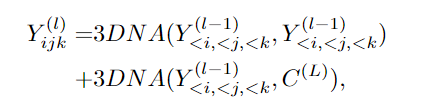
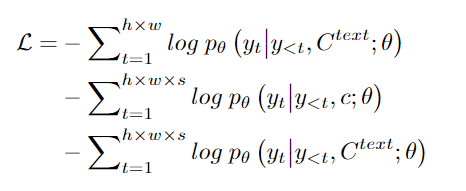
对于 T2I 和 T2V 任务,C^text 表示文本条件。对于 V2V 任务,由于没有文本输入,所以 c 为一个常量,单词 None 的 3D 表示,θ 表示模型参数。
实验结果
实验结果
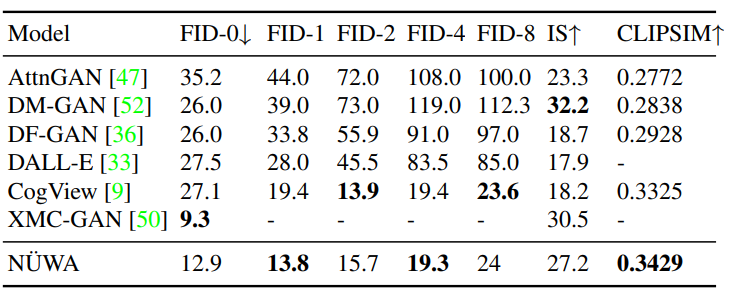
文本转图像(T2I)

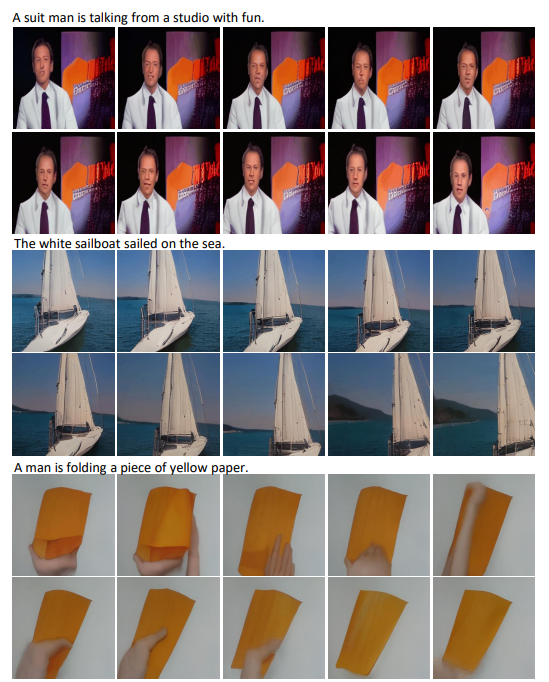
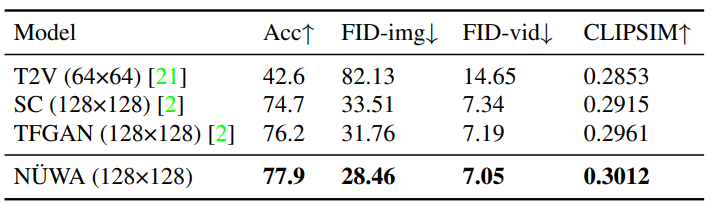
文本转视频(T2V)

图像补全(I2I)

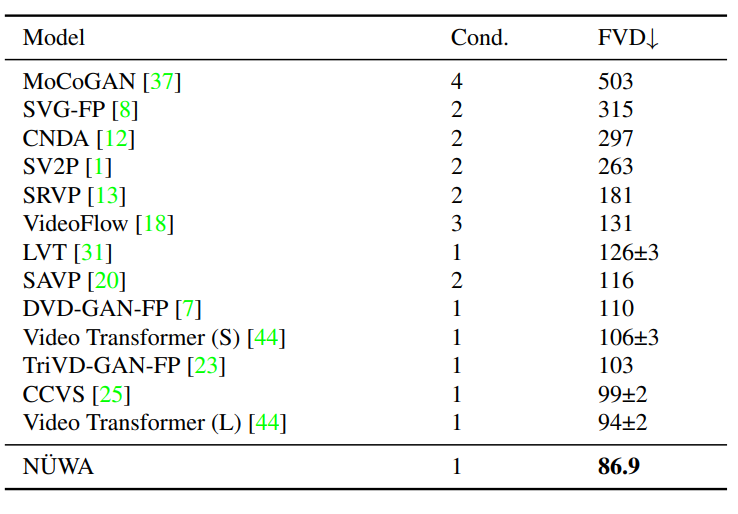
视频预测(V2V)
草图转图像(S2I)

用文本引导图像修改(TI2I)

结论
结论
参考资料:
https://arxiv.org/abs/2111.12417
评论