
直观理解Diffusion model & 常见打开方式
复杂问题分解:DDPM
一张高清图片的分布非常复杂,想要让模型直接生成难度太大了,所以换个思路:把这个过程分解为很多个步骤。从噪声开始,每次叠加一点点噪声,最终得到一张高清图片。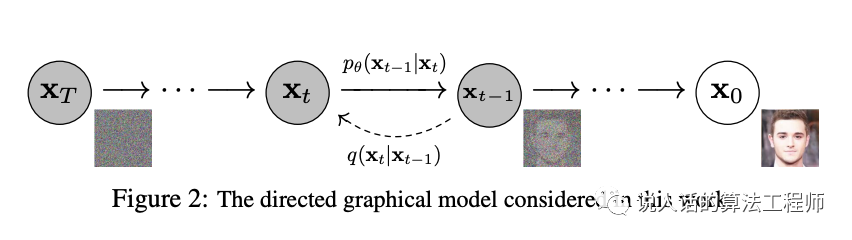 所以训练和生成两个阶段模型做的事情刚好就是图中的两个方向:
所以训练和生成两个阶段模型做的事情刚好就是图中的两个方向:
- 训练:学习从一张高清图片如何能通过一步步叠加噪声的方式,最终变成一个高斯噪声
- 生成:先随机生成一张高斯噪声,再用训练阶段学到的方式反过来算
从单一到可控:Classifier/Semantic Guided
DDPM的缺点是不可控,只能生成一类图像。在此基础上,我们希望可以控制模型生成不同的图像。
- 基础版,按分类:训练阶段图片附带猫/狗的标签,生成阶段输入标签即可得到猫或狗。
- 高阶版,按语义:理想情况是我们可以随意输入文本、甚至是图像,模型给我们生成符合文本语义或和图像相似的图片。
高阶版的效果听起来有点too good to be true?不过这件事情真的实现了。
大力出奇迹:CLIP
openAI收集了4个小目标的图像-文本对,一个图像-文本对的示例如图所示。训练方式是对比学习:取N个图像-文本对,两两组合共 个元素,能对应上(对角线元素)的作为正样本,其他(非对角线)都是负样本。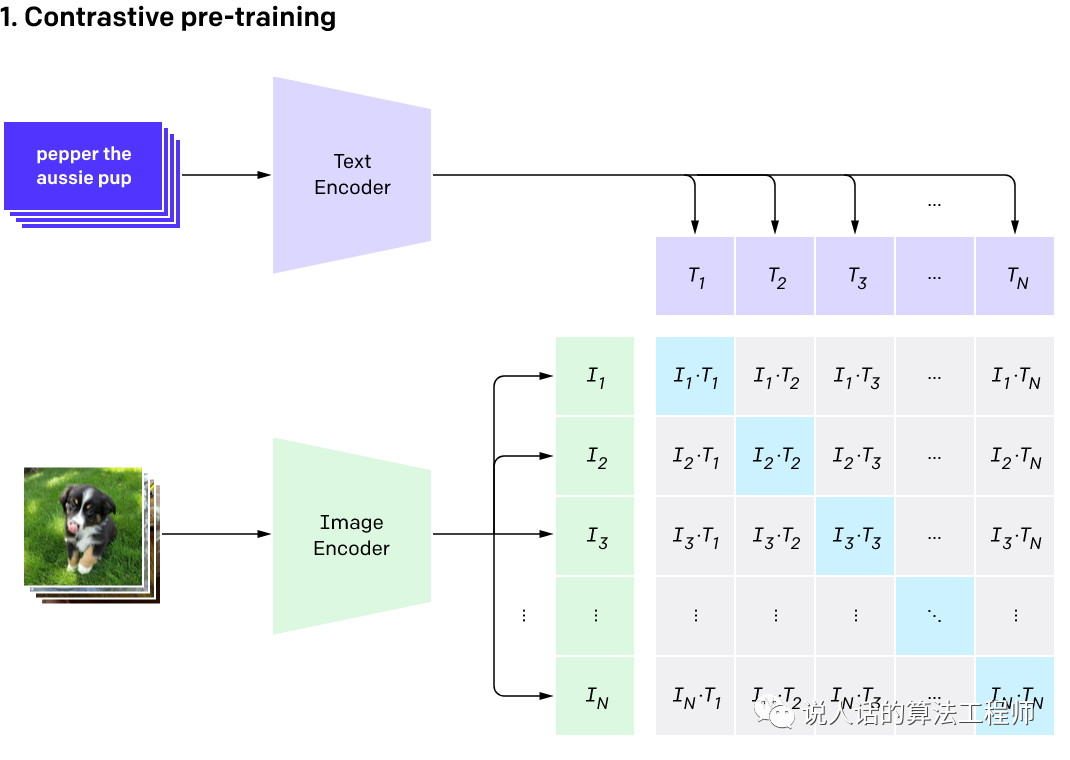
这样做的效果是在zero-shot和few-shot的场景下完爆了过去在imagenet上训练的sota模型,这个事情的牛逼之处在于:
- 过去都是在给定1000个分类下训练和评估,也就是限制了考试大纲的情况下,疯狂做题再参加考试。
- 这次干脆不需要做题(zero-shot)或者只做个两三道题(few-shot)就去参加考试,只靠积累的硬实力上考场。
也就是说,素质教育完爆了应试教育。当然前提是素质教育的爸爸足够有钱,才能让他们的孩子见到足够多的世面。
合体变身:Stable Diffusion
将上面说的东西全部合并到一起,就得到了可以用文本/图像做引导,生成新的图像的diffusion模型了。在很多不同的实现当中,stable diffusion是效果不错、轻量级、且开源的一个,接下来去看一看官方给的使用说明。
1.基础玩法:单一类别、不可控的生成首先介绍几个关键词的含义
- model:负责最核心计算的模型。
- pipeline:把大象放进冰箱里,需要三个步骤。把三个步骤封装到一行代码里,方便使用。
-
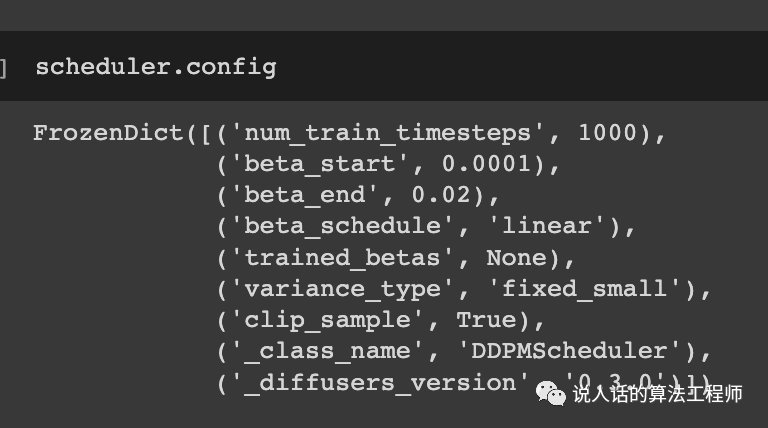
scheduler:为了关大象这个过程更可控、更优雅,我们还可以控制冰箱门开关的动作,速度等。
使用pipeline:一步到位生成单类别图片
from diffusers import DDPMPipeline
image_pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
image_pipe.to("cuda")
images = image_pipe().images
因为模型是从celebahq人脸数据集训练得到的,所以也只能生成人脸
使用scheduler:观察生成的过程
加载教堂模型,并初始化一个noisy_sample
import torch
from diffusers import UNet2DModel
repo_id = "google/ddpm-church-256"
model = UNet2DModel.from_pretrained(repo_id)
torch.manual_seed(0)
noisy_sample = torch.randn(
1, model.config.in_channels, model.config.sample_size, model.config.sample_size
)
noisy_sample.shape
创建一个scheduler
from diffusers import DDPMScheduler
scheduler = DDPMScheduler.from_config(repo_id)
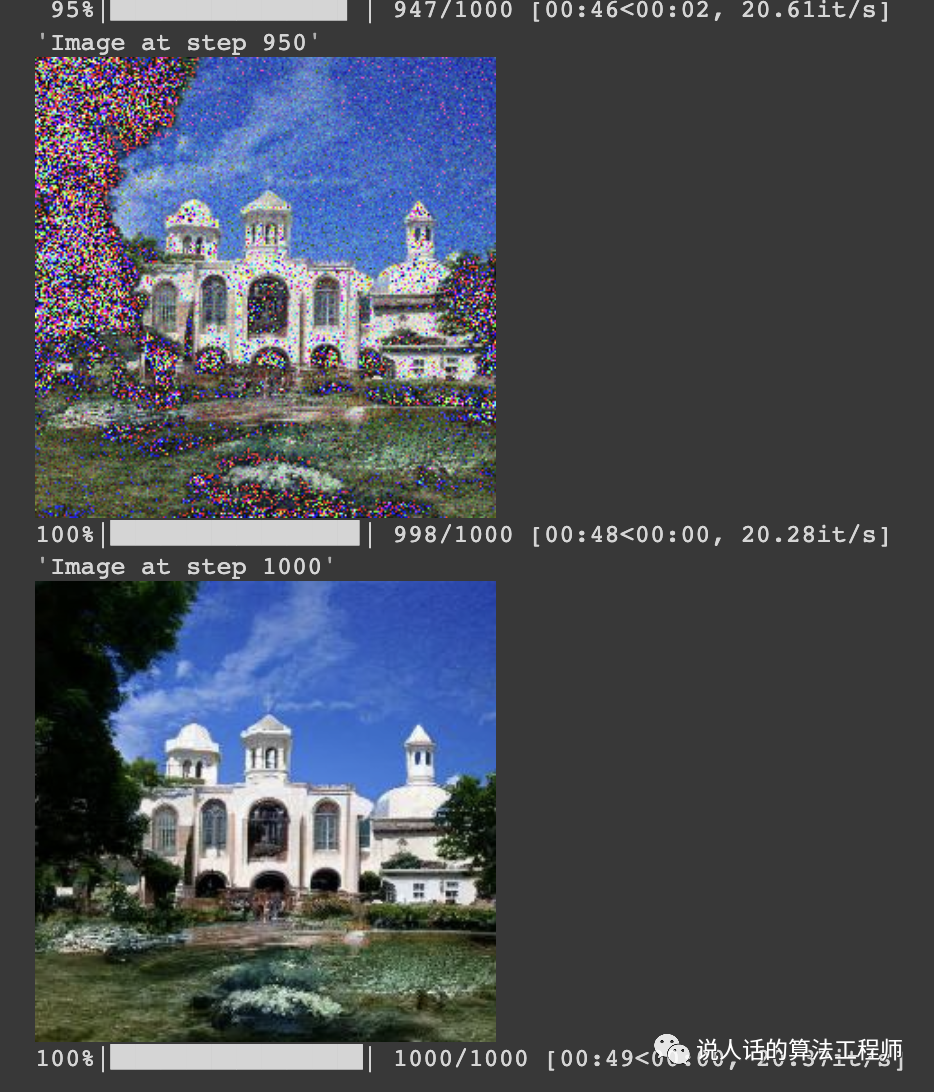
一边更新一边观察。这里按照习惯性的定义,噪声是T时刻,图像是0时刻,所以每一次迭代的输入是,对应sample;输出是,对应prev_sample。prev_sample赋值给sample进入下一轮迭代。
import tqdm
sample = noisy_sample
for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):
# 1. 模型计算
with torch.no_grad():
residual = model(sample, t).sample
# 2. 生成下一步的图像
sample = scheduler.step(residual, t, sample).prev_sample
# 3. 每50步观察一次
if (i + 1) % 50 == 0:
display_sample(sample, i + 1)
开始啥也不是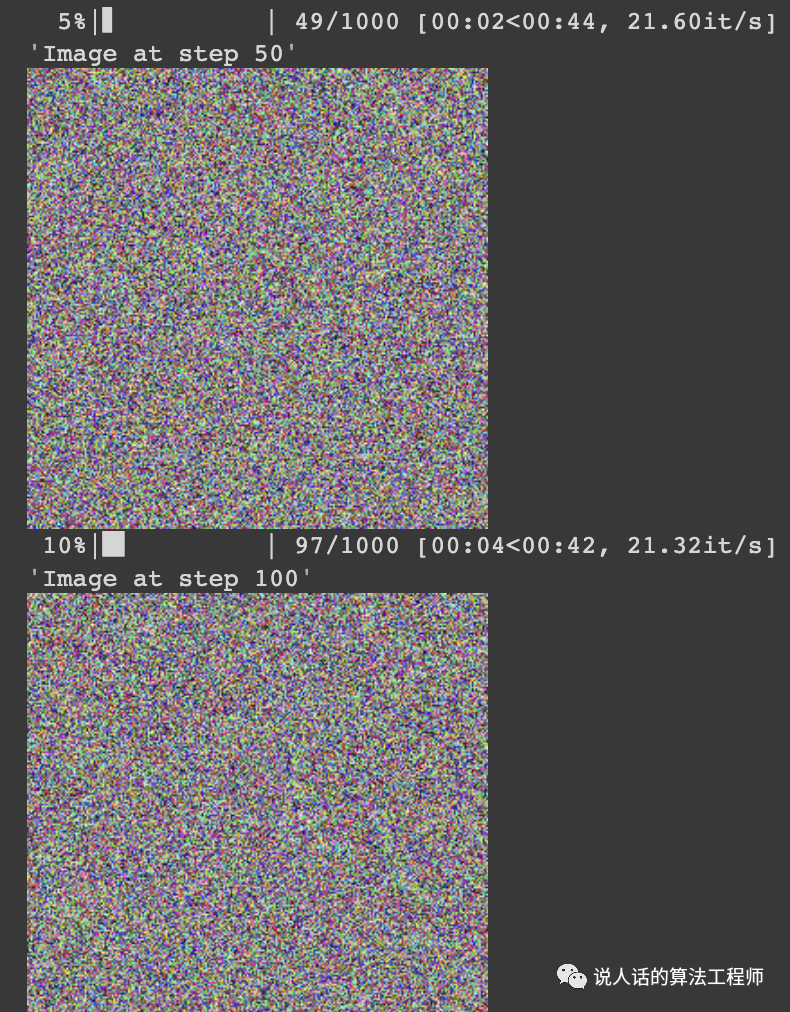
直到800步大概能看出个样子了
最后到1000步的效果
可控生成
可控生成有很多种方式
- text2image:输入文本,输出图像
- image2image:输入图像+文本,输出图像
- in-painting:把图像抹去一部分,补全抹去的部分
以上每一种都有自己的pipeline,可参考相关文档
finetune
实现了可控生成,还有个问题是,如果是模型没有见过的词/物体,就画不出来。这个问题可以通过finetune来解决:
- Textual Inversion:修改文本编码器,加入新的词向量。
- Dreambooth:调整图像生成器,使得输出限定在特定的主题内。
- Full Stable Diffusion fine-tuning:大规模finetune,比如pokemon diffusion。以上三种方法的复杂度和成本依次提高。
- diffuser入门 https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb
- pipeline说明 https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines
-
finetune说明 https://github.com/huggingface/diffusers#fine-tuning-stable-diffusion