
EMNLP 2021 | 多标签文本分类中长尾分布的平衡策略
共 12771字,需浏览 26分钟
·
2021-11-14 21:45
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

多标签文本分类是自然语言处理中的一类经典任务,训练模型为给定文本标记上不定数目的类别标签。然而实际应用时,各类别标签的训练数据量往往差异较大(不平衡分类问题),甚至是长尾分布,影响了所获得模型的效果。重采样(Resampling)和重加权(Reweighting)常用于应对不平衡分类问题,但由于多标签文本分类的场景下类别标签间存在关联,现有方法会导致对高频标签的过采样。本项工作中,我们探讨了优化损失函数的策略,尤其是平衡损失函数在多标签文本分类中的应用。基于通用数据集 (Reuters-21578,90 个标签) 和生物医学领域数据集(PubMed,18211 个标签)的多组实验,我们发现一类分布平衡损失函数的表现整体优于常用损失函数。研究人员近期发现该类损失函数对图像识别模型的效果提升,而我们的工作进一步证明其在自然语言处理中的有效性。
多标签文本分类是自然语言处理(NLP)的核心任务之一,旨在为给定文本从标签库中找到多个相关标签,可应用于搜索(Prabhu et al., 2018)和产品分类(Agrawal et al., 2013)等诸多场景。图 1 展示了通用多标签文本分类数据集 Reuters-21578 的样例数据(Hayes and Weinstein, 1990)。

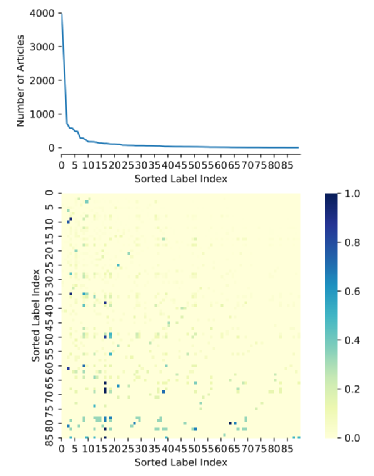
图2 Reuters-21578的长尾分布和标签连锁现象。
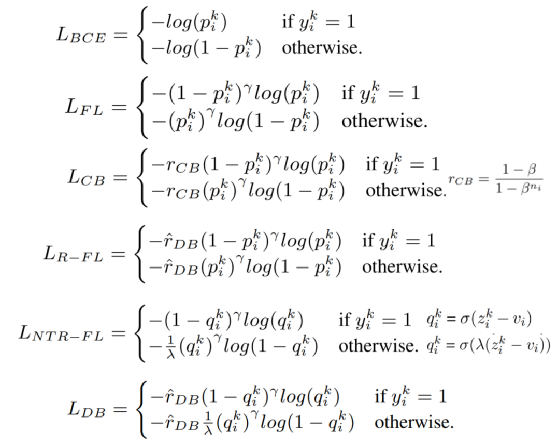
图3 损失函数的具体设计。
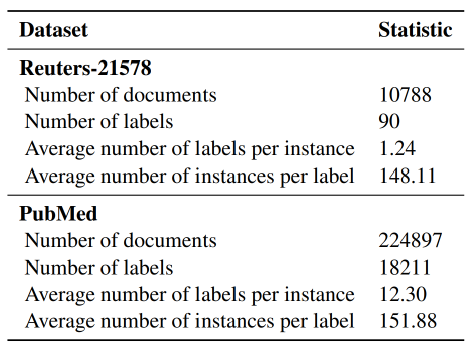
表1 实验用数据集的基本信息

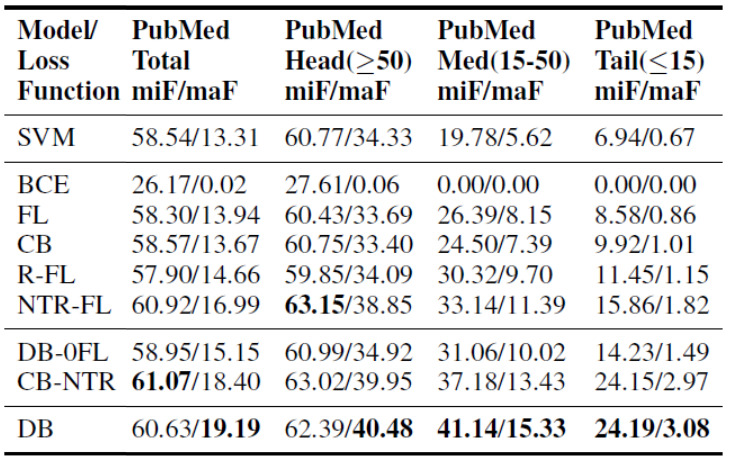
表2 实验结果对比
罗氏集团制药部门中国 CIO 施涪军:该工作来自于合作团队在生物医学领域的深度学习应用探索。相比于日常文本,生物医学领域的语料往往更专业,而标注更稀疏,导致 AI 应用面临“最后一公里”的落地挑战。本论文从稀疏标注的长尾分布等问题入手,由 CV 前沿研究引入损失函数并优化,使得既有 NLP 模型可以在框架不变的情况下将训练资源向实例较少的类别平衡,进而实现整体的模型效果提升。很高兴看到此策略在面临类似问题的日常文本上同样有效,希望继续与院校、企业在前沿技术的研究与应用上扎实共创。
参考文献:
Rahul Agrawal, Archit Gupta, Yashoteja Prabhu, and Manik Varma. 2013. Multi-label learning with millions of labels: Recommending advertiser bid phrases for web pages. In Proceedings of the 22nd international conference on World Wide Web, pages 13–24.
Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2013. Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1798–1828.
Francisco Charte, Antonio J Rivera, María J del Jesus,and Francisco Herrera. 2015. Addressing imbalance in multilabel classification: Measures and random resampling algorithms. Neurocomputing, 163:3–16.
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, and Daniel Weld. 2020. SPECTER: Document-level representation learning using citation-informed transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2270–2282, Online. Association for Computational Linguistics.
NCBI Resource Coordinators. 2017. Database resources of the National Center for Biotechnology Information. Nucleic Acids Research, 46(D1):D8–D13.
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. 2019. Class-balanced loss based on effective number of samples. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9260–9269.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
T. Durand, N. Mehrasa, and G. Mori. 2019. Learning a deep convnet for multi-label classification with partial labels. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 647–657, Los Alamitos, CA, USA. IEEE Computer Society.
Andrew Estabrooks, Taeho Jo, and Nathalie Japkowicz. 2004. A multiple resampling method for learning from imbalanced data sets. Computational intelligence, 20(1):18–36.
Weifeng Ge, Sibei Yang, and Yizhou Yu. 2018. Multievidence filtering and fusion for multi-label classification, object detection and semantic segmentation based on weakly supervised learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Philip J. Hayes and Steven P. Weinstein. 1990. Construe/tis: A system for content-based indexing of a database of news stories. In Proceedings of the The Second Conference on Innovative Applications of Artificial Intelligence, IAAI ’90, page 49–64. AAAI Press.
Gakuto Kurata, Bing Xiang, and Bowen Zhou. 2016. Improved neural network-based multi-label classification with better initialization leveraging label cooccurrence. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 521–526.
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2019. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics.
Jianqiang Li, Guanghui Fu, Yueda Chen, Pengzhi Li, Bo Liu, Yan Pei, and Hui Feng. 2020a. A multilabel classification model for full slice brain computerised tomography image. BMC Bioinformatics, 21(6):200.
Xiaoya Li, Xiaofei Sun, Yuxian Meng, Junjun Liang, Fei Wu, and Jiwei Li. 2020b. Dice loss for dataimbalanced NLP tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 465–476, Online. Association for Computational Linguistics.
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017. Focal loss for dense object detection. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 2999–3007, Los Alamitos, CA, USA. IEEE Computer Society.
Zachary C. Lipton, Charles Elkan, and Balakrishnan Naryanaswamy. 2014. Optimal thresholding of classifiers to maximize f1 measure. In Machine Learning and Knowledge Discovery in Databases, pages 225–239, Berlin, Heidelberg. Springer Berlin Heidelberg. Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. 2016. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In 2016 Fourth International Conference on 3D Vision (3DV), pages 565–571.
Jinseok Nam, Eneldo Loza Mencía, Hyunwoo J Kim, and Johannes Fürnkranz. 2017. Maximizing subset accuracy with recurrent neural networks in multilabel classification. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
Ankit Pal, Muru Selvakumar, and Malaikannan Sankarasubbu. 2020. Magnet: Multi-label text classification using attention-based graph neural network. In ICAART (2), pages 494–505.
F. Pedregosa, G. Varoqu
aux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830.
Yashoteja Prabhu, Anil Kag, Shrutendra Harsola, Rahul Agrawal, and Manik Varma. 2018. Parabel: Partitioned label trees for extreme classification with application to dynamic search advertising. In Proceedings of the 2018 World Wide Web Conference, pages 993–1002.
Che-Ping Tsai and Hung-yi Lee. 2020. Order-free learning alleviating exposure bias in multi-label classification. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty- Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pages 6038–6045. AAAI Press.
George Tsatsaronis, Georgios Balikas, Prodromos Malakasiotis, Ioannis Partalas, Matthias Zschunke, Michael R Alvers, Dirk Weissenborn, Anastasia Krithara, Sergios Petridis, Dimitris Polychronopoulos, Yannis Almirantis, John Pavlopoulos, Nicolas Baskiotis, Patrick Gallinari, Thierry Artieres, Axel Ngonga, Norman Heino, Eric Gaussier, Liliana Barrio-Alvers, Michael Schroeder, Ion Androutsopoulos, and Georgios Paliouras. 2015. An overview of the bioasq large-scale biomedical semantic indexing and question answering competition. BMC Bioinformatics, 16:138.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Jiawei Wu, Wenhan Xiong, and William Yang Wang. 2019. Learning to learn and predict: A metalearning approach for multi-label classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4354– 4364, Hong Kong, China. Association for Computational Linguistics.
Tong Wu, Qingqiu Huang, Ziwei Liu, Yu Wang, and Dahua Lin. 2020. Distribution-balanced loss for multi-label classification in long-tailed datasets. In Computer Vision – ECCV 2020, pages 162–178, Cham. Springer International Publishing.
Wenshuo Yang, Jiyi Li, Fumiyo Fukumoto, and Yanming Ye. 2020. HSCNN: A hybrid-Siamese convolutional neural network for extremely imbalanced multi-label text classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6716–6722, Online. Association for Computational Linguistics.
Yiming Yang and Xin Liu. 1999. A re-examination of text categorization methods. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’99, page 42–49, New York, NY, USA. Association for Computing Machinery.

点个在看 paper不断!