
扒开 Kafka 的神秘面纱
01 为什么从 Kafka 开始?

第三,Kafka 其实是一个轻量级的 MQ,它具备 MQ 最基础的能力,但是在延迟队列、重试机制等高级特性上并未做支持,因此降低了实现复杂度。从 Kafka 入手,有利于大家快速掌握 MQ 最核心的东西。
02 扒开 Kafka 的面纱
在深入分析一门技术之前,不建议上来就去了解架构以及技术细节,而是先弄清楚它是什么?它是为了解决什么问题而产生的?
掌握这些背景知识后,有利于我们理解它背后的设计考虑以及设计思想。
在写这篇文章时,我查阅了很多资料,关于 Kafka 的定义可以说五花八门,不仔细推敲很容易懵圈,我觉得有必要带大家捋一捋。
我们先看看 Kafka 官网给自己下的定义:
Apache Kafka is an open-source distributed event streaming platform.
Kafka 最开始其实是 Linkedin 内部孵化的项目,在设计之初是被当做「数据管道」,用于处理以下两种场景:
1、运营活动场景:记录用户的浏览、搜索、点击、活跃度等行为。
2、系统运维场景:监控服务器的 CPU、内存、请求耗时等性能指标。
可以看到这两种数据都属于日志范畴,特点是:数据实时生产,而且数据量很大。
Linkedin 最初也尝试过用 ActiveMQ 来解决数据传输问题,但是性能无法满足要求,然后才决定自研 Kafka。
所以从一开始,Kafka 就是为实时日志流而生的。了解了这个背景,就不难理解 Kafka 与流数据的关系了,以及 Kafka 为什么在大数据领域有如此广泛的应用?也是因为它最初就是为解决大数据的管道问题而诞生的。
接着再解释下:为什么 Kafka 被官方定义成流处理平台呢?它不就提供了一个数据通道能力吗,怎么还和平台扯上关系了?
1、Kafka Streams:一个轻量化的流计算库,性质类似于 Spark、Flink。
2、Kafka Connect:一个数据同步工具,能将 Kafka 中的数据导入到关系数据库、Hadoop、搜索引擎中。
可见 Kafka 的野心不仅仅是一个消息系统,它早就在往「实时流处理平台」方向发展了。
1、数据的发布和订阅能力(消息队列)
2、数据的分布式存储能力(存储系统)
3、数据的实时处理能力(流处理引擎)
03 从 Kafka的消息模型说起
下面我们尝试分析下 Kafka 的消息模型,看看它究竟是如何演化来的?
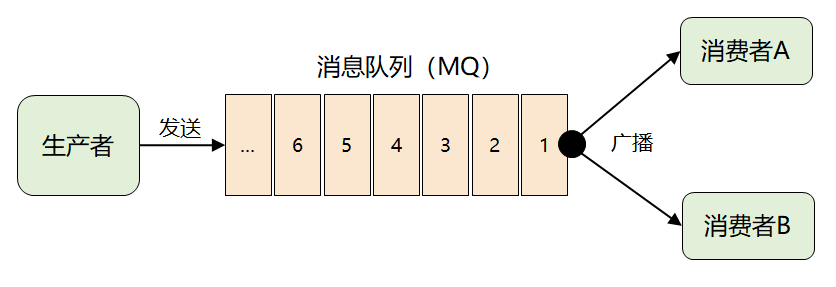
紧接着问题出现了:来一条消息,就广播给所有消费者,但并非每个消费者都想要全部的消息,比如消费者 A 只想要消息1、2、3,消费者 B 只想要消息4、5、6,这时候该怎么办呢?
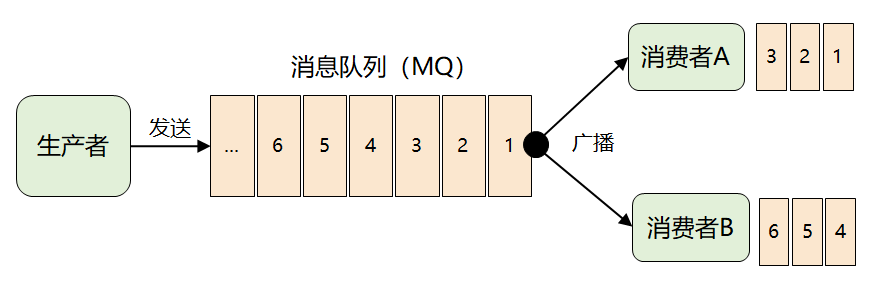
这个问题的关键点在于:MQ 不理解消息的语义,它根本无法做到对消息进行分类投递。
此时,MQ 想到了一个很聪明的办法:它将难题直接抛给了生产者,要求生产者在发送消息时,对消息进行逻辑上的分类,因此就演进出了我们熟知的 Topic 以及发布-订阅模型。
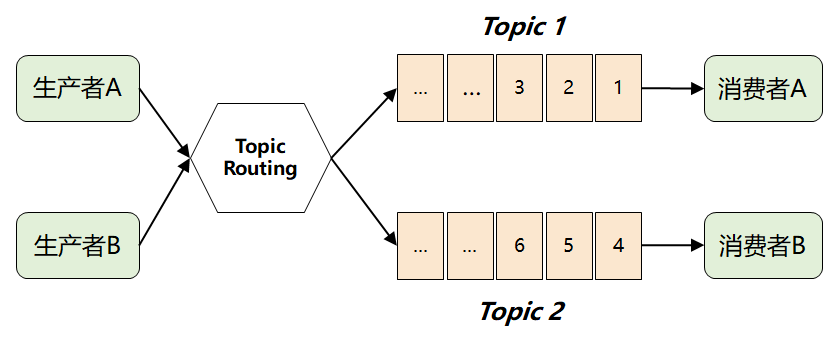
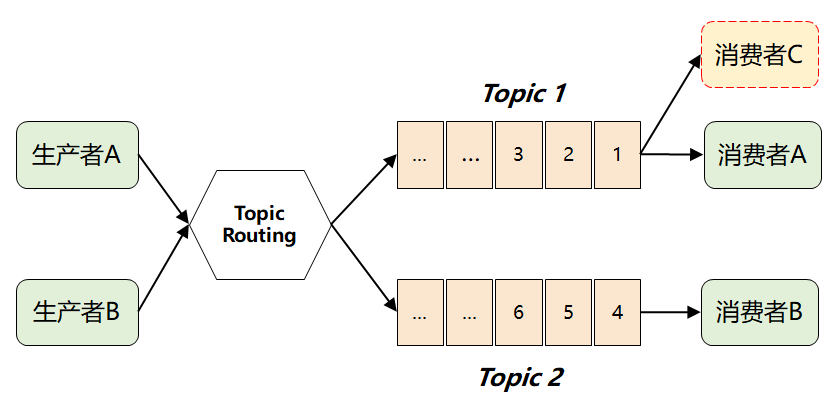
如果采用传统的队列模式(单播),那当一个消费者从队列中取走消息后,这条消息就会被删除,另外一个消费者就拿不到了。
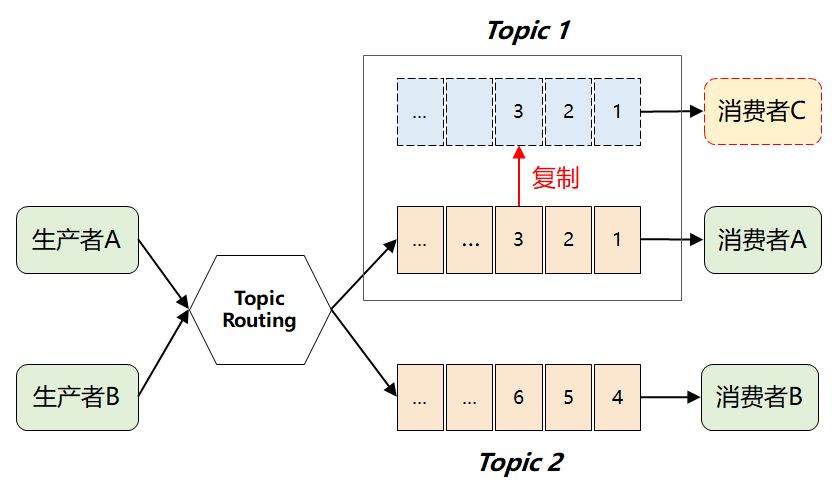
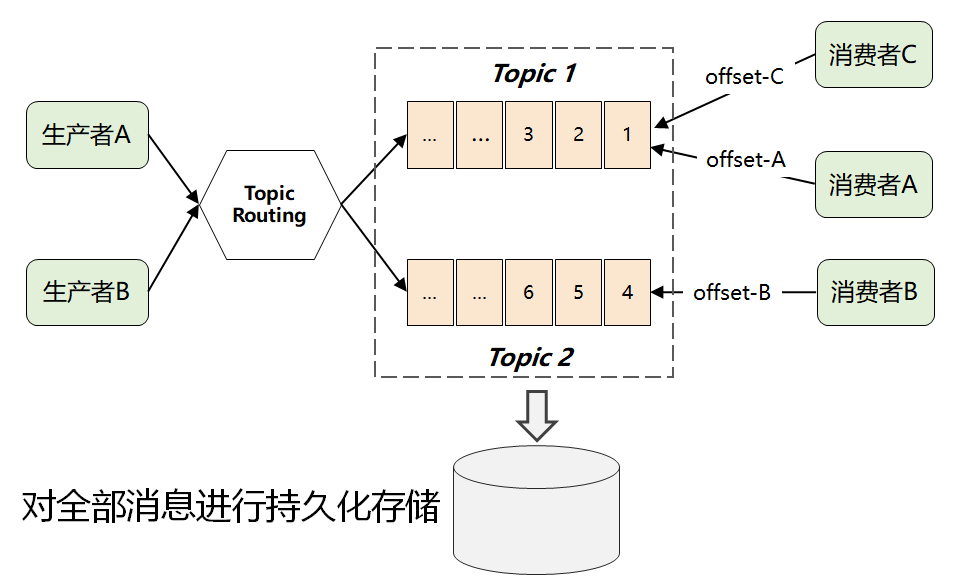
这时候,就有了 Kafka 最画龙点睛的一个解法:它将所有消息进行了持久化存储,由消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 即可。
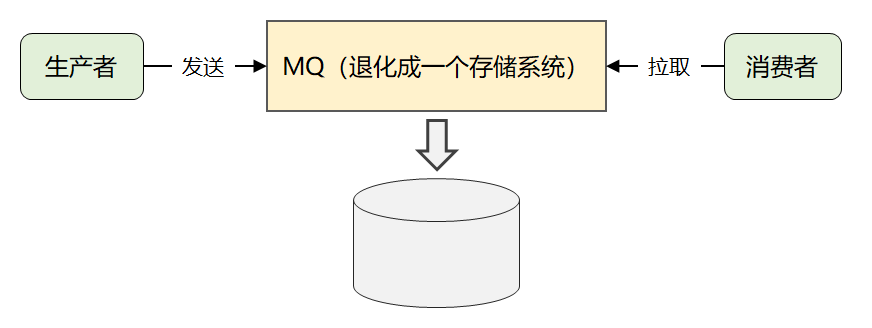
04 写在最后