
缓冲区溢出

1 引言
“缓冲区溢出”对现代操作系统与编译器来讲已经不是什么大问题,但是作为一个合格的 C/C++ 程序员,还是完全有必要了解它的整个细节。
计算机程序一般都会使用到一些内存,这些内存或是程序内部使用,或是存放用户的输入数据,这样的内存一般称作缓冲区。简单的说,缓冲区就是一块连续的计算机内存区域,它可以保存相同数据类型的多个实例,如字符数组。而缓冲区溢出则是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。
2 C/C++中内存分配
任何一个源程序通常都包括静态的代码段(或者称为文本段)和静态的数据段,为了运行程序,操作系统首先负责为其创建进程,并在进程的虚拟地址空间中为其代码段和数据段建立映射。但是只有静态的代码段和数据段是不够的,进程在运行过程中还要有其动态环境。
一般说来,默认的动态存储环境通过堆栈机制建立。所有局部变量及所有按值传递的函数参数都通过堆栈机制自动分配内存空间。如下图。
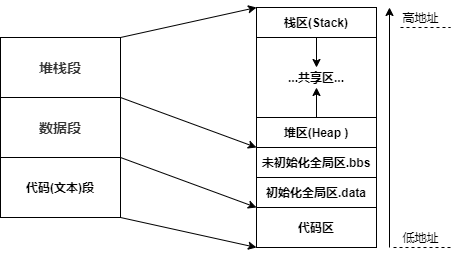
栈区(stack):由编译器自动分配与释放,存放为运行时函数分配的局部变量、函数参数、返回数据、返回地址等。其操作类似于数据结构中的栈。 堆区(heap):一般由程序员自动分配,如果程序员没有释放,程序结束时可能有OS回收。其分配类似于链表。 全局区(静态区static):数据段,程序结束后由系统释放。全局区分为已初始化全局区(data),用来存放保存全局的和静态的已初始化变量和未初始化全局区(bss),用来保存全局的和静态的未初始化变量。 常量区(文字常量区):数据段,存放常量字符串,程序结束后有系统释放。 代码区:存放函数体(类成员函数和全局区)的二进制代码,这个段在内存中一般被标记为只读,任何对该区的写操作都会导致段错误(Segmentation Fault)。
需要特别注意的是,堆(Heap)和栈(Stack)是有区别的,很多程序员混淆堆栈的概念,或者认为它们就是一个概念。简单来说,它们之间的主要区别可以表现在如下五个方面。
分配和管理方式不同
堆是动态分配的,其空间的分配和释放都由程序员控制。也就是说,堆的大小并不固定,可动态扩张或缩减,其分配由malloc()等这类实时内存分配函数来实现。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
而栈由编译器自动管理,其分配方式有两种:静态分配和动态分配。静态分配由编译器完成,比如局部变量的分配。动态分配由alloca()函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,无需手工控制。
申请的大小限制不同
栈是向低地址扩展的数据结构,是一块连续的内存区域,栈顶的地址和栈的最大容量是系统预先规定好的,能从栈获得的空间较小。
堆是向高地址扩展的数据结构,是不连续的内存区域,这是由于系统是由链表在存储空闲内存地址,自然堆就是不连续的内存区域,且链表的遍历也是从低地址向高地址遍历的,堆的大小受限于计算机系统的有效虚拟内存空间,
由此空间,堆获得的空间比较灵活,也比较大。在 32 位平台下,VC6 下默认为 1M,堆最大可以到 4G;
申请效率不同
栈由系统自动分配,速度快,但是程序员无法控制。 堆是有程序员自己分配,速度较慢,容易产生碎片,不过用起来方便。
产生碎片不同
对堆来说,频繁执行malloc或free势必会造成内存空间的不连续,形成大量的碎片,使程序效率降低;而对栈而言,则不存在碎片问题。
内存地址增长的方向不同
堆是向着内存地址增加的方向增长的,从内存的低地址向高地址方向增长; 栈的增长方向与之相反,是向着内存地址减小的方向增长,由内存的高地址向低地址方向增长。
假设一个程序的函数调用顺序为:主函数main调用函数func1,函数func1调用函数func2。当这个程序被操作系统调入内存运行时,其对应的进程在内存中的映射结果如下图所示

进程的栈是由多个栈帧构成的,其中每个栈帧都对应一个函数调用。当调用函数时,新的栈帧被压入栈;当函数返回时,相应的栈帧从栈中弹出。由于需要将函数返回地址这样的重要数据保存在程序员可见的堆栈中,因此也给系统安全带来了极大的隐患。
当程序写入超过缓冲区的边界时,就会产生所谓的“缓冲区溢出”。发生缓冲区溢出时,就会覆盖下一个相邻的内存块,导致程序发生一些不可预料的结果:也许程序可以继续,也许程序的执行出现奇怪现象,也许程序完全失败或者崩溃等。
缓冲区溢出
对于缓冲区溢出,一般可以分为4种类型,即栈溢出、堆溢出、BSS溢出与格式化串溢出。其中,栈溢出是最简单,也是最为常见的一种溢出方式。
没有保证足够的存储空间存储复制过来的数据
void function(char *str)
{
char buffer[10];
strcpy(buffer,str);
}
上面的strcpy()将直接把str中的内容copy到buffer中。这样只要str的长度大于 10 ,就会造成buffer的溢出,使程序运行出错。存在象strcpy这样的问题的标准函数还有strcat(),sprintf(),vsprintf(),gets(),scanf()等。对应的有更加安全的函数,即在函数名后加上_s,如scanf_s()函数。
严格检查输入长度和缓冲区长度。 常见的高危函数
| 函数 | 严重性 | 防范手段 |
|---|---|---|
| gets() | 最危险 | 使用 fgets(buf, size, stdin) |
| strcpy() | 很危险 | 改为使用 strncpy() |
| strcat() | 很危险 | 改为使用 strncat() |
| sprintf() | 很危险 | 改为使用snprintf(),或者使用精度说明符 |
| scanf() | 很危险 | 使用精度说明符,或自己进行解析 |
| sscanf() | 很危险 | 使用精度说明符,或自己进行解析 |
| fscanf() | 很危险 | 使用精度说明符,或自己进行解析 |
| vfscanf() | 很危险 | 使用精度说明符,或自己进行解析 |
| vfscanf() | 很危险 | 改为使用 vsnprintf(),或者使用精度说明符 |
| vscanf() | 很危险 | 使用精度说明符,或自己进行解析 |
| vsscanf() | 很危险 | 使用精度说明符,或自己进行解析 |
| streadd() | 很危险 | 使用精度说明符,或自己进行解析 |
整数溢出
宽度溢出:把一个宽度较大的操作数赋给宽度较小的操作数,就有可能发生数据截断或符号位丢失
#include
int main()
{
signed int value1 = 10;
usigned int value2 = (unsigned int)value1;
}
算术溢出,该程序即使在接受用户输入的时候对a、b的赋值做安全性检查,a+b 依旧可能溢出:
#include
int main()
{
int a;
int b;
int c=a*b;
return 0;
}
数组索引不在合法范围内
enum {TABLESIZE = 100};
int *table = NULL;
int insert_in_table(int pos, int value) {
if(!table) {
table = (int *)malloc(sizeof(int) *TABLESIZE);
}
if(pos >= TABLESIZE) {
return -1;
}
table[pos] = value;
return 0;
}
其中:pos为int类型,可能为负数,这会导致在数组所引用的内存边界之外进行写入,可以将pos类型改为size_t避免
空字符错误
例如:
//错误
char array[]={'0','1','2','3','4','5','6','7','8'};
//正确的写法应为:
char array[]={'0','1','2','3','4','5','6','7','8',’\0’};
//或者
char array[11]={'0','1','2','3','4','5','6','7','8','9’};
点【在看】是最大的支持 