
ChatGLM-6B 本地部署指南!
Datawhale干货
作者:宋志学,Datawhale成员
注意事项-写在最前
-
显卡需要至少6GB的显存
-
使用GPU部署模型需要自行安装torch和与自己显卡匹配的CUDA、cudnn
下载ChatGLM-6B
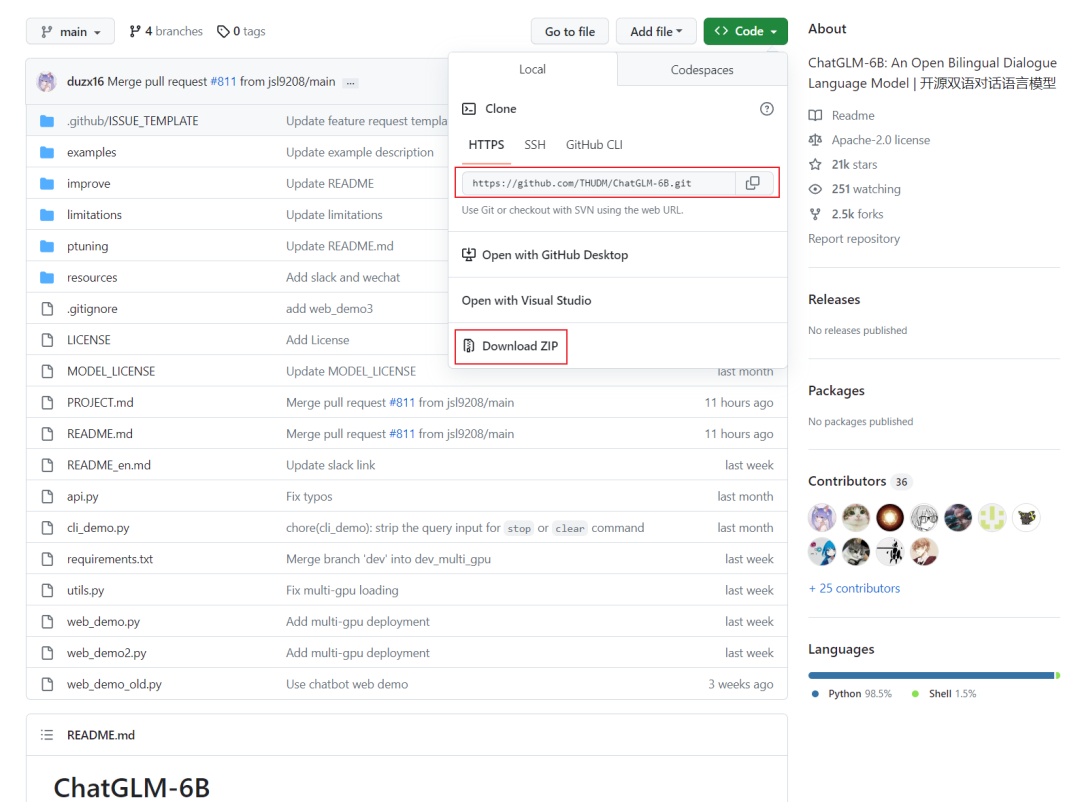
在GitHub上下载chatglm-6b的源码,地址如下
https://github.com/THUDM/ChatGLM-6B
开源双语对话语言模型 | An Open Bilingual Dialogue Language Model
可以使用git clone代码,也可以下载代码压缩包到本地(看你心情)
然后,安装一些包。
pip install -r requirements.txt
下载int4模型
在Hugging Face上下载chatglm-6b int4量化模型地址如下:
https://huggingface.co/THUDM/chatglm-6b-int4
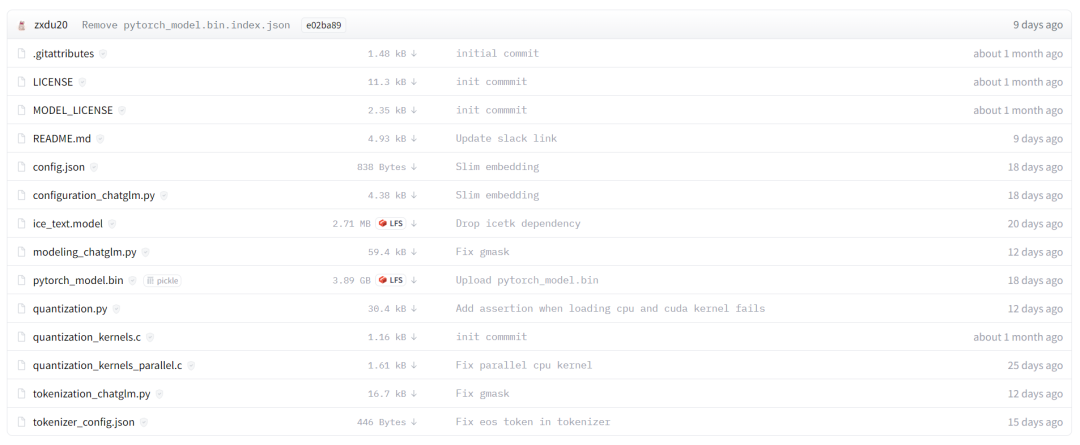
这些所有文件都需要下载(可能需要一点点魔法,但是相信聪明的你,一定可以!)
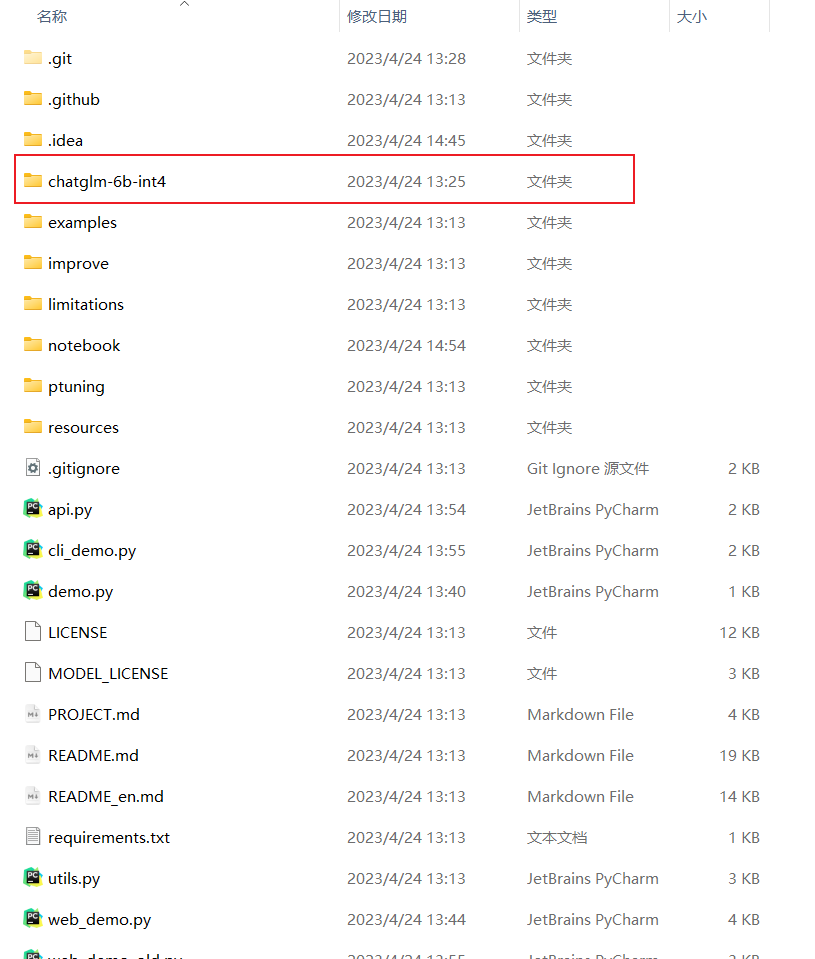
在刚刚下载好的chatglm源码中新建一个用于下载模型文件的文件夹,命名为chatglm-6b-int4(你也可以换一个你喜欢的名字)。将Hugging Face上的int4量化模型下载到里面。
修改源码
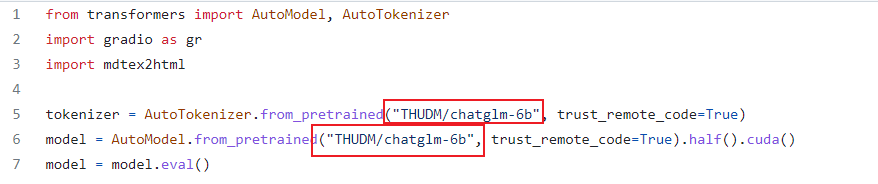
web_demo.py
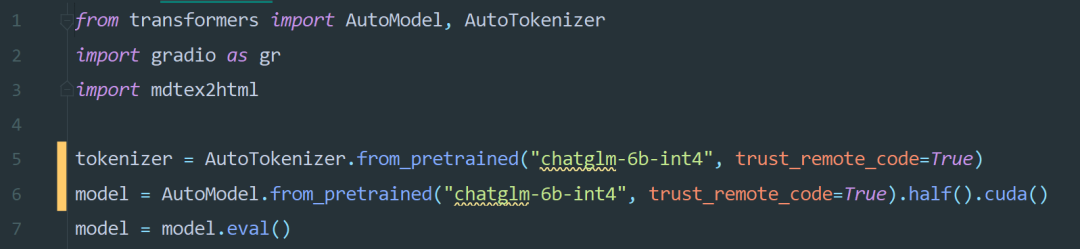
将源码中wei_demo.py文件中的第5、6两行代码中的模型路径修改为chatglm-6b-int4也就是刚刚下载模型的文件夹。如下图所示。
切记:不要用./chatglm-6b-in4不要出现"点杠"的形式,如果你把模型文件放在了其他地方,请务必使用绝对路径,如:"G:\日常文件\Chatgpt相关\ChatGLM-6B\chatglm-6b-int4"。(要使用双斜杠,双斜杠,双斜杠!!!)鼓励你像我这样直接放在源码里面,免去路径问题的困扰。(相信你足够聪明,可以解决这个问题!)
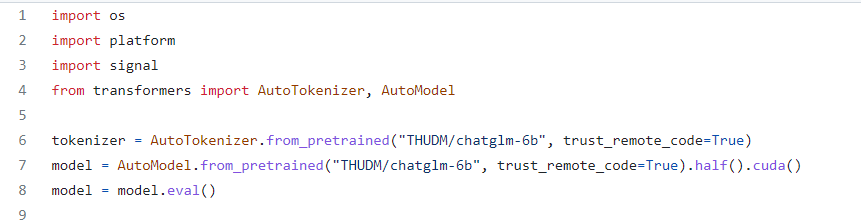
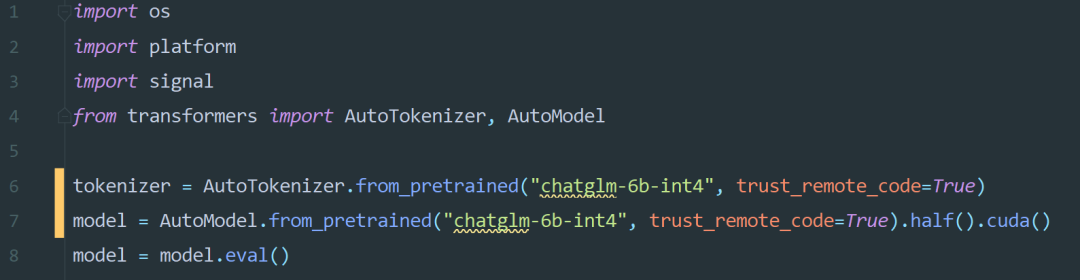
api.py


cli_demo.py
运行代码
web_demo.py
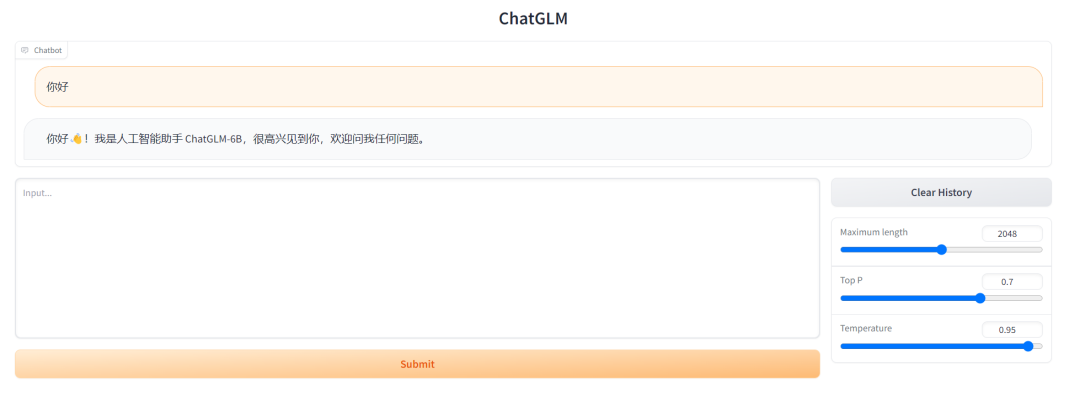
在下载chatglm源码的目录,打开cmd,输入python web_demo.py经过一段时间的等待,出现如下图一样的输出就代表运行成功,在浏览器输入地址:http://127.0.0.1:7860,就可以愉快地使用chatglm啦~
-
gcc报错不需要管,属于windows自己问题,咱们使用GPU运行,gcc与我们无关
在 CPU 上运行时,会根据硬件自动编译 CPU Kernel ,请确保已安装 GCC 和 OpenMP (Linux一般已安装,对于Windows则需手动安装),以获得最佳并行计算能力。
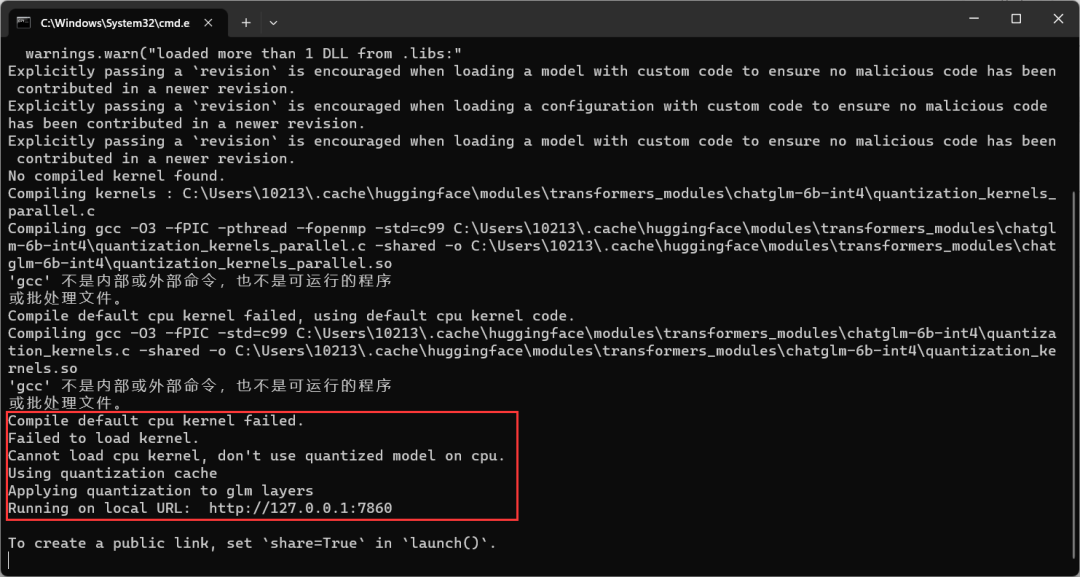
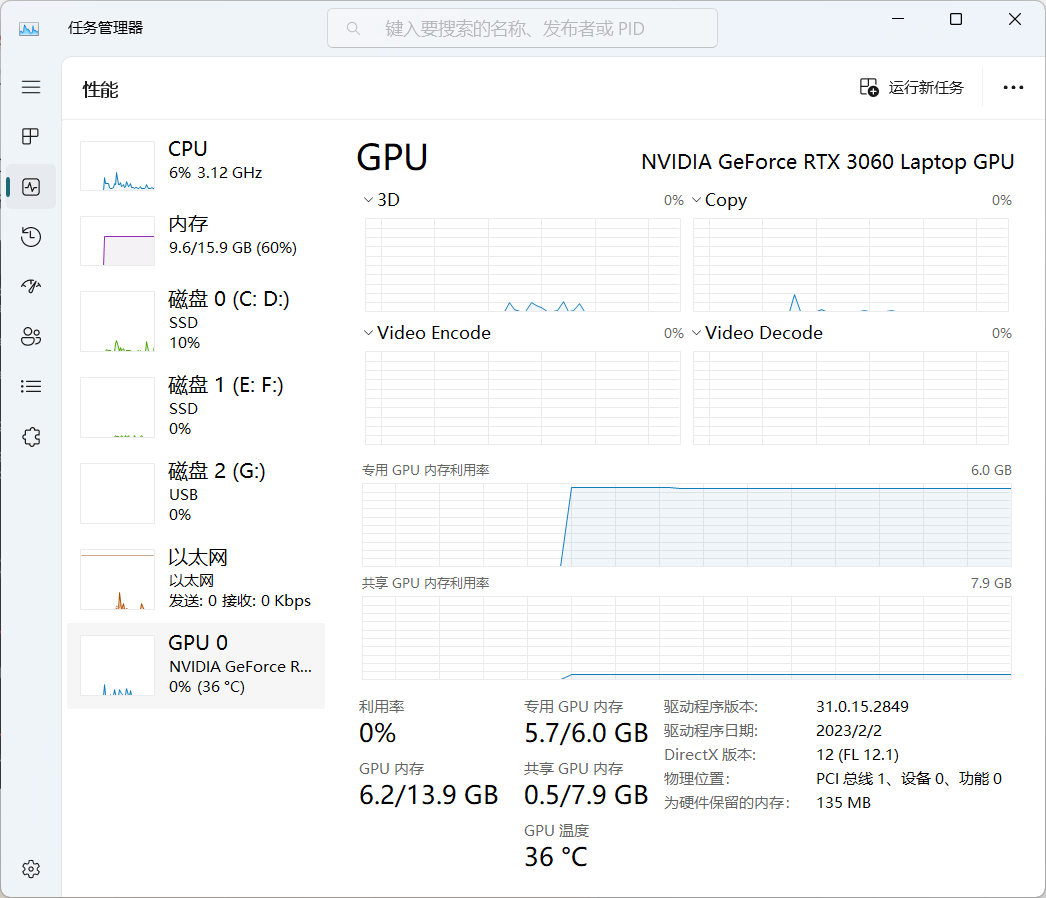
可以看到显存占了5.7GB,所以需要至少一张6GB的显存的显卡,再来玩这个。
- 注意:对话太长也会爆显存。
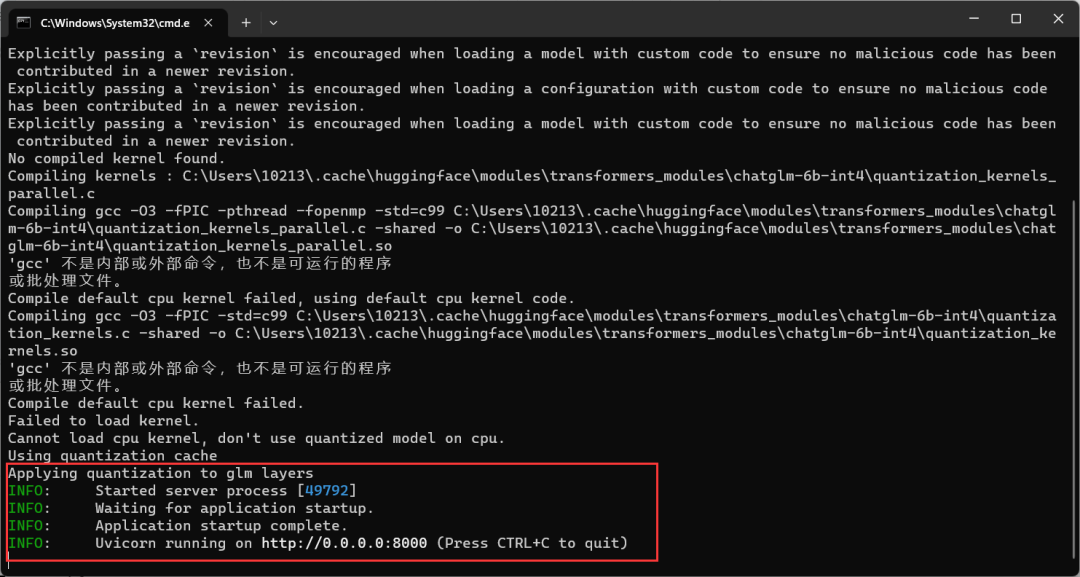
api.py
在命令行输入python api.py,经过一段时间的运行,出现如下输出,就是运行成功。
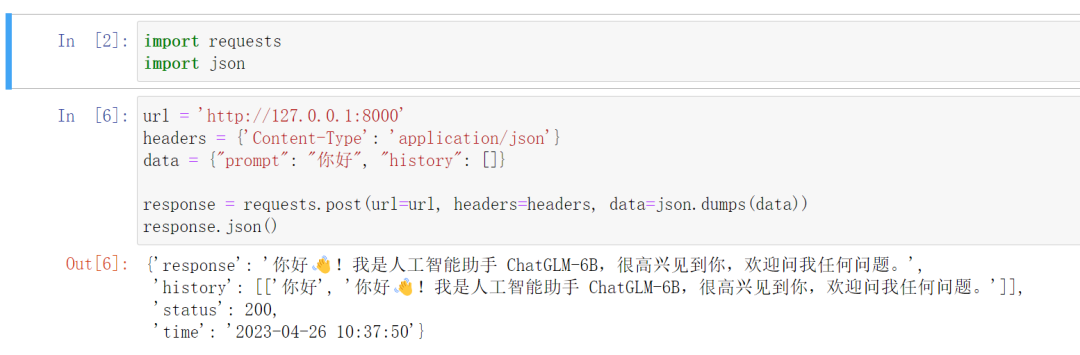
按照官网给的示例
curl -X POST "http://127.0.0.1:8000"
-H 'Content-Type: application/json'
-d '{"prompt": "你好", "history": []}'
可以使用python中的requests库进行访问,聪明的你可以把这个代码封装一下实现多轮对话。
import requests
import json
url = 'http://127.0.0.1:8000'
headers = {'Content-Type': 'application/json'}
data = {"prompt": "你好", "history": []}
response = requests.post(url=url, headers=headers, data=json.dumps(data))
response.json()
cli_demo.py
在命令行输入python cli_demo.py,经过一段时间的运行,出现如下输出,就是运行成功。
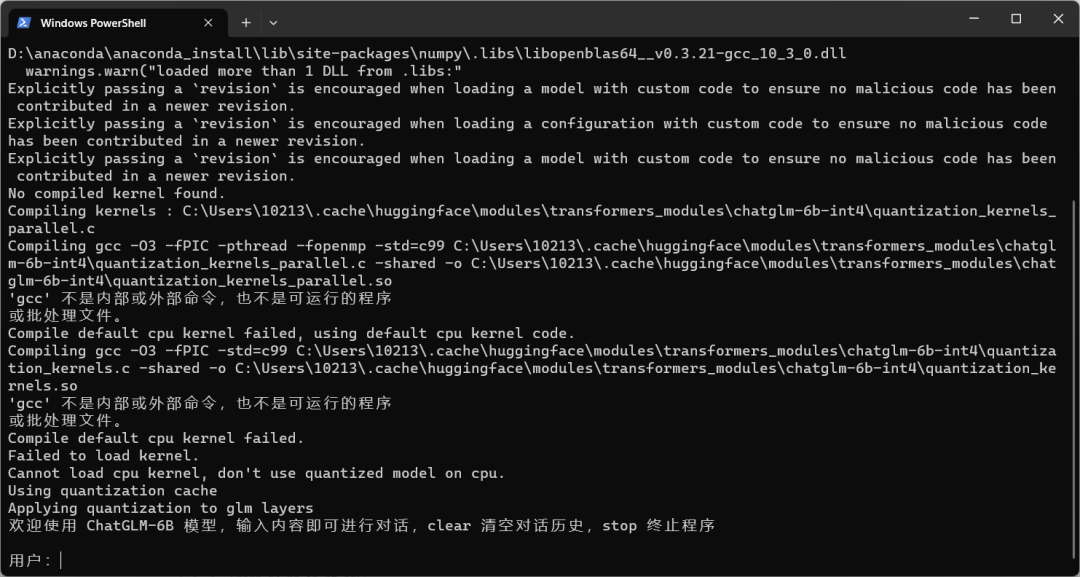
然后,可以和他进行对话,就像运行wei_demo.py一样。
注:以下为号主的知识星球广告