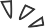Apache Flink不止于计算,数仓架构或兴起新一轮变革
共 7492字,需浏览 15分钟
·
2022-01-14 02:48

大数据文摘出品
作者:蔡芳芳
采访嘉宾:王峰(莫问)
维基百科的“Apache Flink”词条下,有这么一句描述:“Flink 并不提供自己的数据存储系统,但为 Amazon Kinesis、Apache Kafka、Alluxio、HDFS、Apache Cassandra 和 Elasticsearch 等系统提供了数据源和接收器”,很快,这句话的前半句或许将不再适用。
2021 年初,在 InfoQ 编辑部策划的全年技术趋势展望中,我们提到大数据领域将加速拥抱“融合”(或“一体化”)演进的新方向。本质是为了降低大数据分析的技术复杂度和成本,同时满足对性能和易用性的更高要求。如今,我们看到流行的流处理引擎 Apache Flink(下称 Flink)沿着这个趋势又迈出了新的一步。
1 月 8 日上午,Flink Forward Asia 2021 以线上会议的形式拉开帷幕。今年是 Flink Forward Asia(下文简称 FFA)落地中国的第四个年头,也是 Flink 成为 Apache 软件基金会顶级项目的第七年。伴随着实时化浪潮的发展和深化,Flink 已逐步演进为流处理的领军角色和事实标准。
回顾其演进历程,Flink 一方面持续优化其流计算核心能力,不断提高整个行业的流计算处理标准,另一方面沿着流批一体的思路逐步推进架构改造和应用场景落地。但在这些之外,Flink 长期发展还需要一个新的突破口。
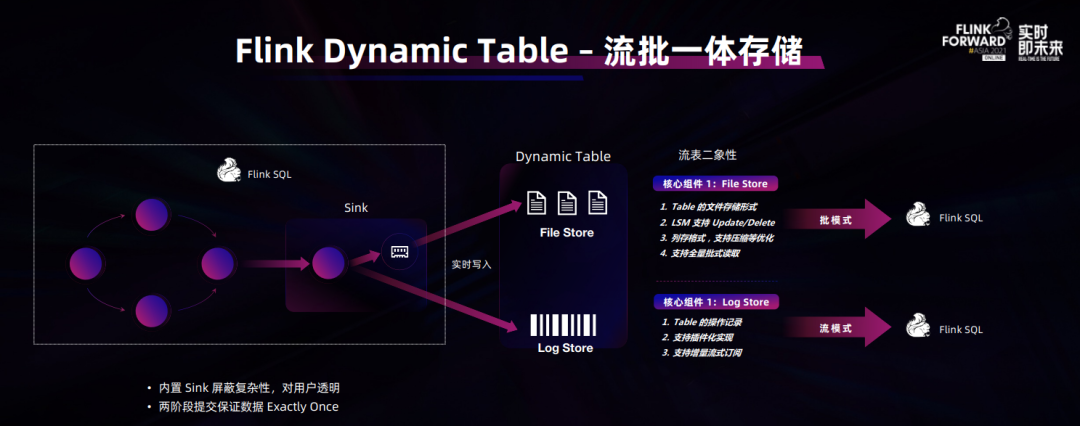
在 Flink Forward Asia 2021 的主题演讲中,Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰(花名莫问)重点介绍了 Flink 在流批一体架构演进和落地方面的最新进展,并提出了 Flink 下一步的发展方向——流式数仓(Streaming Warehouse,简称 Streamhouse)。正如主题演讲标题“Flink Next, Beyond Stream Processing”所言,Flink 要从 Stream Processing 走向 Streaming Warehouse 去覆盖更大的场景,帮助开发者解决更多问题。而要实现流式数仓的目标,就意味着 Flink 社区要拓展适合流批一体的数据存储,这是 Flink 今年在技术方面的一个创新,社区相关工作已经在 10 月份启动,接下来这会作为 Flink 社区未来一年的一个重点方向来推进。
那么,如何理解流式数仓?它想解决现有数据架构的哪些问题?为什么 Flink 要选择这个方向?流式数仓的实现路径会是怎样的?带着这些问题,InfoQ 独家专访了莫问,进一步了解流式数仓背后的思考路径。
Flink 这几年一直在反复强调流批一体,即:使用同一套 API、同一套开发范式来实现大数据的流计算和批计算,进而保证处理过程与结果的一致性。莫问表示,流批一体更多是一种技术理念和能力,它本身不解决用户的任何问题,只有当它真正落到实际业务场景中,才能够体现出开发效率和运行效率上的价值。而流式数仓可以理解为流批一体大方向下对落地解决方案的思考。
流批一体的两个应用场景

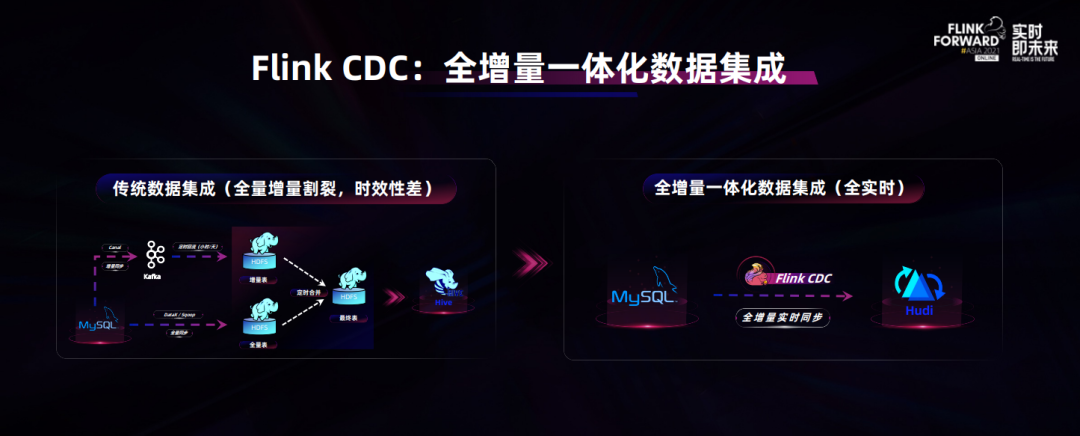
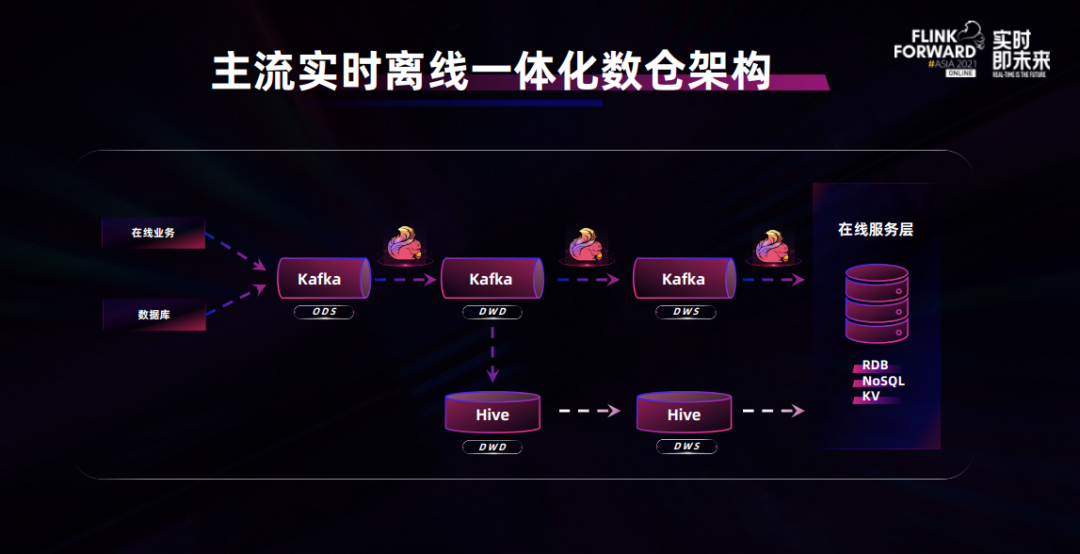
理解流式数仓

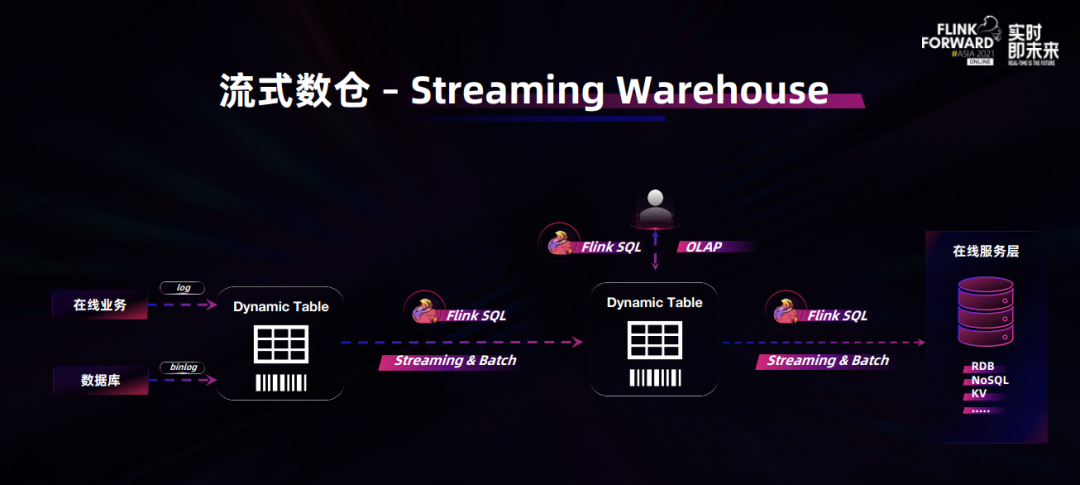
流批一体存储:Flink Dynamic Table
Flink 不止于计算
在大数据实时化转型大趋势之下,Flink 不只能做一件事情,它还能做更多。
结语