
《对线面试官》 MySQL 调优
面试官:要不你来讲讲你们对MySQL是怎么调优的?
候选者:哇,这命题很大阿…我认为,对于开发者而言,对MySQL的调优重点一般是在「开发规范」、「数据库索引」又或者说解决线上慢查询上。
候选者:而对于MySQL内部的参数调优,由专业的DBA来搞。
面试官:扯了这么多,你就是想表达你不会MySQL参数调优,对吧
候选者:草,被发现了。
面试官:那你来聊聊你们平时开发的规范和索引这块,平时是怎么样的吧。
候选者:嗯,首先,我们在生产环境下,创建数据库表,都是在工单系统下完成的(那就自然需要DBA审批)。如果在创建表时检测到没有创建索引,那就会直接提示warning(:

候选者:理论上来说,如果表有一定的数据量,那就应该要创建对应的索引。从数据库查询数据需要注意的地方还是蛮多的,其中很多都是平时积累来的。比如说:
候选者:1. 是否能使用「覆盖索引」,减少「回表」所消耗的时间。意味着,我们在select 的时候,一定要指明对应的列,而不是select *
候选者:2. 考虑是否组建「联合索引」,如果组建「联合索引」,尽量将区分度最高的放在最左边,并且需要考虑「最左匹配原则」
候选者:3.对索引进行函数操作或者表达式计算会导致索引失效
候选者:4.利用子查询优化超多分页场景。比如 limit offset , n 在MySQL是获取 offset + n的记录,再返回n条。而利用子查询则是查出n条,通过ID检索对应的记录出来,提高查询效率。
面试官:嗯…
候选者:5.通过explain命令来查看SQL的执行计划,看看自己写的SQL是否走了索引,走了什么索引。通过show profile 来查看SQL对系统资源的损耗情况(不过一般还是比较少用到的)
候选者:6.在开启事务后,在事务内尽可能只操作数据库,并有意识地减少锁的持有时间(比如在事务内需要插入&&修改数据,那可以先插入后修改。因为修改是更新操作,会加行锁。如果先更新,那并发下可能会导致多个事务的请求等待行锁释放)

面试官:嗯,你提到了事务,之前也讲过了事务的隔离级别嘛,那你线上用的是什么隔离级别?
候选者:嗯,我们这边用的是Read Commit(读已提交),MySQL默认用的是Repeatable read(可重复读)。选用什么隔离级别,主要看应用场景嘛,因为隔离级别越低,事务并发性能越高。
候选者:(一般互联网公司都选择Read Commit作为主要的隔离级别)
候选者:像Repeatable read(可重复读)隔离级别,就有可能因为「间隙锁」导致的死锁问题。
候选者:但可能你已经知道,MySQL默认的隔离级别为Repeatable read。很大一部分原因是在最开始的时候,MySQL的binlog没有row模式,在read commit隔离级别下会存在「主从数据不一致」的问题
候选者:binlog记录了数据库表结构和表数据「变更」,比如update/delete/insert/truncate/create。在MySQL中,主从同步实际上就是应用了binlog来实现的(:
候选者:有了该历史原因,所以MySQL就将默认的隔离级别设置为Repeatable read

面试官:嗯,那我顺便想问下,你们遇到过类似的问题吗:即便走对了索引,线上查询还是慢。
候选者:嗯嗯,当然遇到过了
面试官:那你们是怎么做的?
候选者:如果走对了索引,但查询还是慢,那一般来说就是表的数据量实在是太大了。
候选者:首先,考虑能不能把「旧的数据」给”删掉”,对于我们公司而言,我们都会把数据同步到Hive,说明已经离线存储了一份了。
候选者:那如果「旧的数据」已经没有查询的业务了,那最简单的办法肯定是”删掉”部分数据咯。数据量降低了,那自然,检索速度就快了…
面试官:嗯,但一般不会删的
候选者:没错,只有极少部分业务可以删掉数据(:
候选者:随后,就考虑另一种情况,能不能在查询之前,直接走一层缓存(Redis)。
候选者:而走缓存的话,又要看业务能不能忍受读取的「非真正实时」的数据(毕竟Redis和MySQL的数据一致性需要保证),如果查询条件相对复杂且多变的话(涉及各种group by 和sum),那走缓存也不是一种好的办法,维护起来就不方便了…
候选者:再看看是不是有「字符串」检索的场景导致查询低效,如果是的话,可以考虑把表的数据导入至Elasticsearch类的搜索引擎,后续的线上查询就直接走Elasticsearch了。
候选者:MySQL->Elasticsearch需要有对应的同步程序(一般就是监听MySQL的binlog,解析binlog后导入到Elasticsearch)
候选者:如果还不是的话,那考虑要不要根据查询条件的维度,做相对应的聚合表,线上的请求就查询聚合表的数据,不走原表。
候选者:比如,用户下单后,有一份订单明细,而订单明细表的量级太大。但在产品侧(前台)透出的查询功能是以「天」维度来展示的,那就可以将每个用户的每天数据聚合起来,在聚合表就是一个用户一天只有一条汇总后的数据。
候选者:查询走聚合后的表,那速度肯定杠杠的(聚合后的表数据量肯定比原始表要少很多)
候选者:思路大致的就是「以空间换时间」,相同的数据换别的地方也存储一份,提高查询效率

面试官:那我还想问下,除了读之外,写性能同样有瓶颈,怎么办?
候选者:你说到这个,我就不困了。
候选者:如果在MySQL读写都有瓶颈,那首先看下目前MySQL的架构是怎么样的。
候选者:如果是单库的,那是不是可以考虑升级至主从架构,实现读写分离。
候选者:简单理解就是:主库接收写请求,从库接收读请求。从库的数据由主库发送的binlog进而更新,实现主从数据一致(在一般场景下,主从的数据是通过异步来保证最终一致性的)

面试官:嗯…
候选者:如果在主从架构下,读写仍存在瓶颈,那就要考虑是否要分库分表了
候选者:至少在我前公司的架构下,业务是区分的。流量有流量数据库,广告有广告的数据库,商品有商品的数据库。所以,我这里讲的分库分表的含义是:在原来的某个库的某个表进而拆分。
候选者:比如,现在我有一张业务订单表,这张订单表在广告库中,假定这张业务订单表已经有1亿数据量了,现在我要分库分表
候选者:那就会将这张表的数据分至多个广告库以及多张表中(:
候选者:分库分表的最明显的好处就是把请求进行均摊(本来单个库单个表有一亿的数据,那假设我分开8个库,那每个库1200+W的数据量,每个库下分8张表,那每张表就150W的数据量)。

面试官:你们是以什么来作为分库键的?
候选者:按照我们这边的经验,一般来说是按照userId的(因为按照用户的维度查询比较多),如果要按照其他的维度进行查询,那还是参照上面的的思路(以空间换时间)。
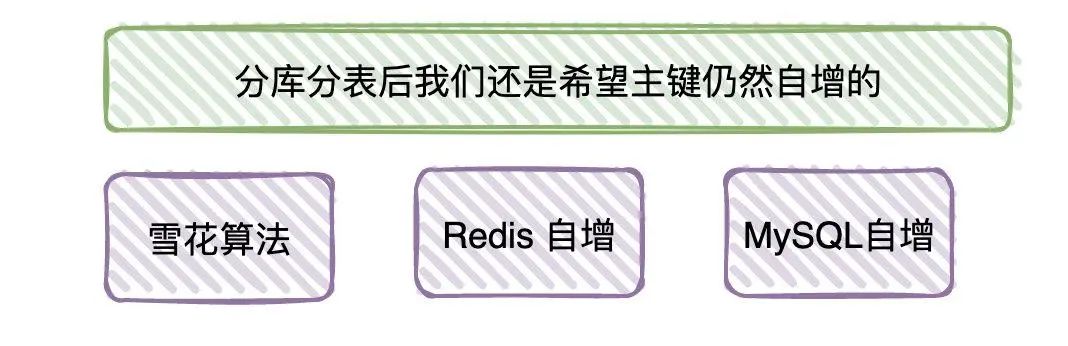
面试官:那分库分表后的ID是怎么生成的?
候选者:这就涉及到分布式ID生成的方式了,思路有很多。有借助MySQL自增的,有借助Redis自增的,有基于「雪花算法」自增的。具体使用哪种方式,那就看公司的技术栈了,一般使用Redis和基于「雪花算法」实现用得比较多。
候选者:至于为什么强调自增(还是跟索引是有序有关,前面已经讲过了,你应该还记得)
面试官:嗯,那如果我要分库分表了,迁移的过程是怎么样的呢
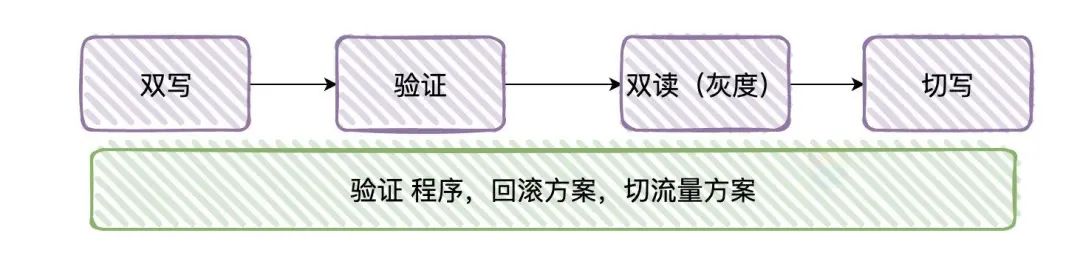
候选者:我们一般采取「双写」的方式来进行迁移,大致步骤就是:
候选者:一、增量的消息各自往新表和旧表写一份
候选者:二、将旧表的数据迁移至新库
候选者:三、迟早新表的数据都会追得上旧表(在某个节点上数据是同步的)
候选者:四、校验新表和老表的数据是否正常(主要看能不能对得上)
候选者:五、开启双读(一部分流量走新表,一部分流量走老表),相当于灰度上线的过程
候选者:六、读流量全部切新表,停止老表的写入
候选者:七、提前准备回滚机制,临时切换失败能恢复正常业务以及有修数据的相关程序。
面试官:嗯…今天就到这吧
本文总结:
数据库表存在一定数据量,就需要有对应的索引 发现慢查询时,检查是否走对索引,是否能用更好的索引进行优化查询速度,查看使用索引的姿势有没有问题 当索引解决不了慢查询时,一般由于业务表的数据量太大导致,利用空间换时间的思想 当读写性能均遇到瓶颈时,先考虑能否升级数据库架构即可解决问题,若不能则需要考虑分库分表 分库分表虽然能解决掉读写瓶颈,但同时会带来各种问题,需要提前调研解决方案和踩坑
线上不是给你炫技的地方,安稳才是硬道理。能用简单的方式去解决,不要用复杂的方式